Author: Denis Avetisyan
A new method analyzes the underlying grammatical structure of text to reliably identify content generated by artificial intelligence.
DependencyAI leverages dependency parsing to detect AI-generated text across multiple languages, offering strong performance and feature interpretability.
The increasing prevalence of large language models necessitates robust methods for distinguishing machine-generated text from human writing, yet current approaches often rely on lexical features susceptible to simple manipulation. This paper introduces ‘DependencyAI: Detecting AI Generated Text through Dependency Parsing’, a novel technique that leverages syntactic structure-specifically linguistic dependency relations-to identify AI-generated text. DependencyAI achieves competitive performance across multiple settings without relying on lexical content, offering a strong, interpretable, and non-neural baseline for detection. Could a deeper understanding of these syntactic signatures reveal fundamental differences in how humans and machines construct language, and further improve cross-domain generalization of detection methods?
The Erosion of Authenticity: A Looming Challenge
The rapid increase in AI-driven text generation is fundamentally challenging established notions of online authenticity. Previously, determining the source of information relied heavily on assumptions about human authorship; however, increasingly sophisticated artificial intelligence can now produce text that closely mimics human writing styles, making it difficult to discern its origin. This proliferation isn’t merely a technical hurdle, but a societal one, as the ability to easily create convincing, yet fabricated, content threatens to erode trust in digital information, potentially impacting areas from journalism and academic research to social media interactions and political discourse. The sheer volume of AI-generated text further exacerbates the problem, overwhelming traditional methods of verification and demanding innovative approaches to content authentication.
Early attempts to identify artificially generated text often relied on identifying predictable patterns, such as repetitive phrasing or unusual statistical distributions of words. However, contemporary AI models, particularly large language models, have become remarkably adept at mimicking human writing styles, generating text that is contextually appropriate and grammatically sound. This nuanced output presents a significant hurdle for traditional detection methods, which struggle to differentiate between genuine human creativity and sophisticated algorithmic imitation. Consequently, research is shifting towards more robust approaches, including analyzing stylistic fingerprints, examining the “burstiness” of language-the variation in sentence length and complexity-and exploring the use of adversarial techniques to expose subtle inconsistencies in AI-generated content. The evolution of detection strategies must keep pace with the increasing sophistication of AI text generation to effectively safeguard information integrity.
The integrity of online information increasingly relies on the ability to differentiate between human and artificial authorship. As AI text generation becomes more sophisticated, the lines blur, creating vulnerabilities for misinformation and eroding public trust. A failure to accurately identify AI-generated content can have far-reaching consequences, influencing public opinion, damaging reputations, and even impacting critical decision-making processes. Consequently, developing reliable methods for discerning the origin of online text is not merely a technical challenge, but a fundamental requirement for preserving the credibility of digital spaces and fostering informed discourse. The proliferation of undetectable AI text threatens to destabilize established norms of authorship and accountability, making robust detection tools essential for maintaining a trustworthy information ecosystem.
DependencyAI: A Syntactic Fingerprint for AI Detection
DependencyAI employs a lightweight detection method by analyzing sequences of dependency relations extracted from text. Dependency parsing identifies grammatical structures, representing relationships between words-such as subject-verb or adjective-noun pairings-as a series of directed links. These dependency relation sequences, forming a textual “fingerprint” of syntactic structure, are then used as features for a classifier. This approach avoids the computational expense of large language models while still capturing stylistic differences between human and AI-generated text, as AI models often exhibit distinct patterns in dependency structure compared to natural human writing.
Dependency parsing is a natural language processing technique that analyzes the grammatical structure of a sentence to establish relationships between individual words. This involves identifying the head word of each word in a sentence and determining the type of dependency relation-such as subject, object, or modifier-that connects them. The output of dependency parsing is a tree-like structure representing these relationships, effectively mapping the syntactic dependencies within the text. By representing a sentence’s structure rather than simply its sequential word order, dependency parsing provides a method for capturing the underlying grammatical features used by DependencyAI to distinguish between human and AI writing styles.
DependencyAI differentiates between human and AI-generated text by analyzing variations in dependency relation sequences. Human writing exhibits a greater diversity and complexity in these sequences, characterized by a wider range of syntactic constructions and more frequent instances of non-canonical dependencies. Conversely, AI-generated text, while grammatically correct, tends to rely on more predictable and statistically common dependency patterns, resulting in a comparatively limited structural variation. This difference in syntactic complexity is quantified through metrics calculated from the parsed dependency trees, enabling the model to achieve accurate classification by identifying these stylistic fingerprints.
Unveiling Key Indicators: A Focus on Feature Importance
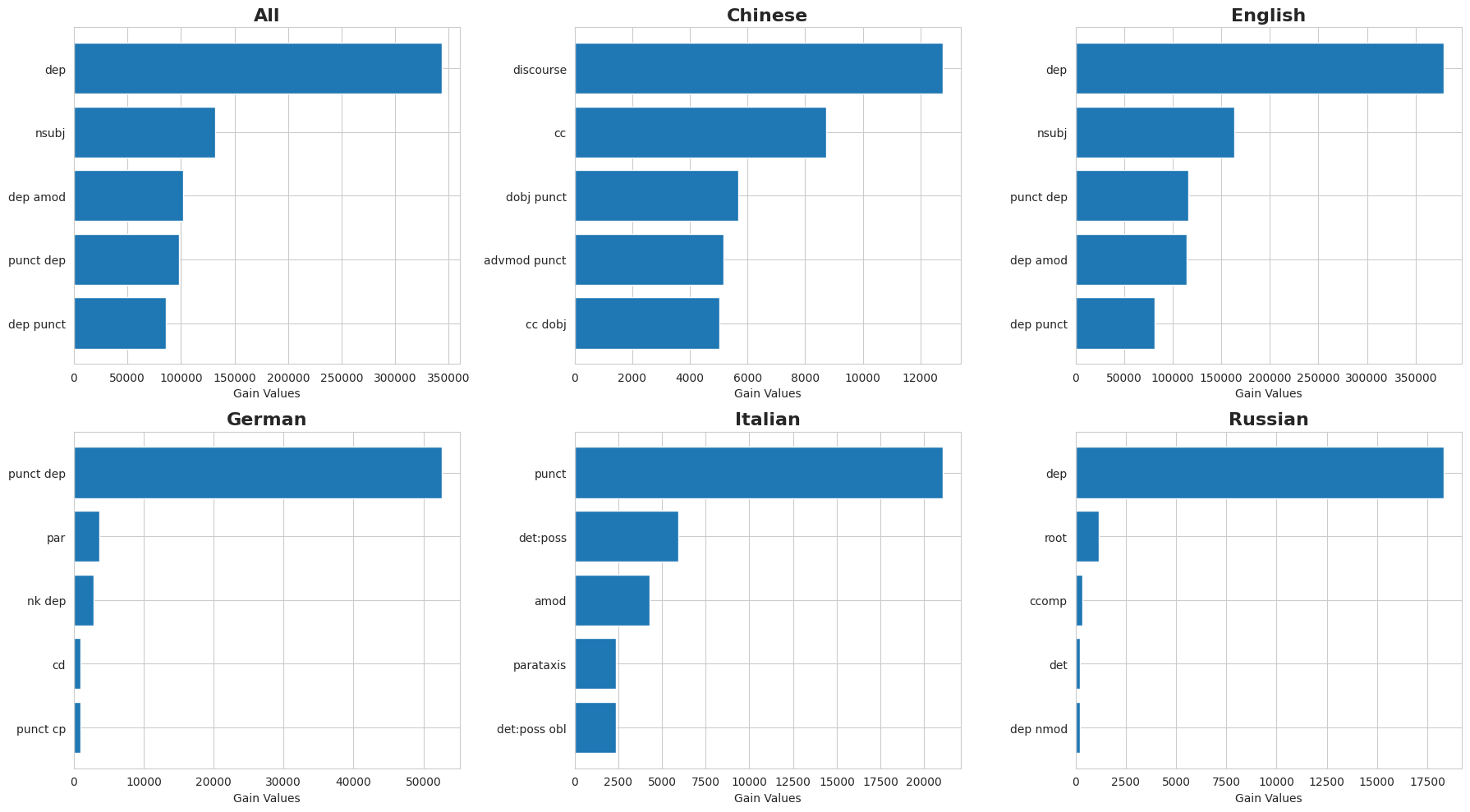
Feature Importance Analysis within the DependencyAI system utilized a methodology to determine the relative predictive power of individual dependency relations in classifying text as either human-written or AI-generated. This process involved evaluating each dependency relation’s contribution to the model’s overall accuracy. The analysis treated dependency relations as features, assessing their ability to differentiate between the two text sources. Results were then quantified to rank the dependency relations by their impact on detection performance, allowing for focused investigation of the most salient linguistic characteristics of AI-generated text.
Feature importance analysis conducted on the DependencyAI model demonstrated that certain dependency relations are strong indicators of AI-generated text. Specifically, the dependency relation labeled ‘Unspecified Dependency Relation’ consistently ranked among the most influential features for accurate detection. This suggests that the presence, frequency, or specific contextual usage of this relation type provides a discernible signal differentiating AI-generated content from human-authored text, and contributes meaningfully to the model’s overall predictive power.
The Gain metric, utilized in the feature importance analysis of DependencyAI, operates by calculating the average reduction in the Gini impurity or entropy achieved by splitting on each individual dependency relation. Specifically, the metric quantifies the cumulative reduction in model error attributable to each feature across all decision trees within the ensemble model. A higher Gain value indicates a greater contribution of that dependency relation to the overall predictive power of the model; values are normalized to provide a comparative scale for assessing relative feature importance. This allows for a data-driven ranking of dependency relations based on their impact on model performance, facilitating focused analysis and potential feature selection.
Robustness and Generalization: A Versatile Approach to Detection
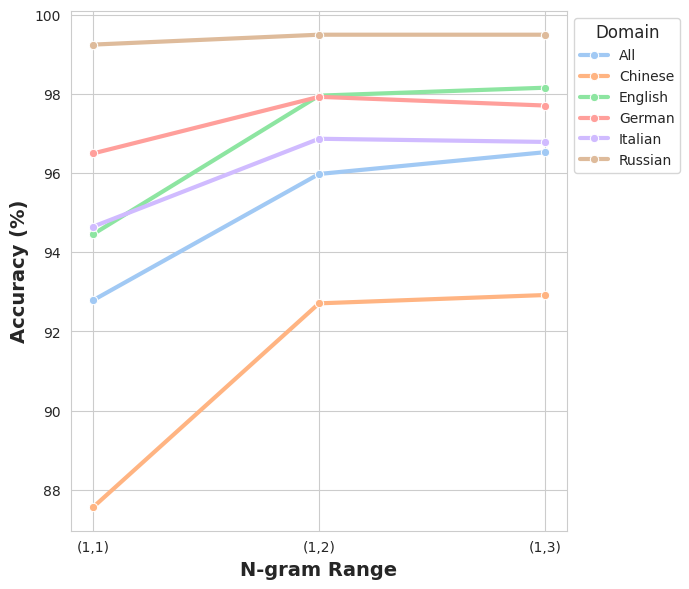
DependencyAI exhibits a notable capacity for accurate dependency relation detection, as evidenced by its performance on the challenging M4GT-Bench Dataset. This benchmark rigorously tests a model’s ability to generalize across both multiple languages and diverse text domains, including areas not encountered during training. The system achieved an overall accuracy of 88.85% in multi-way detection when evaluated on these previously unseen domains, demonstrating a robust level of adaptability. Complementing this, DependencyAI secured an F1 score of 88.94% under the same conditions, indicating a strong balance between precision and recall in identifying dependency relationships – a key metric for natural language understanding and a promising indicator of its potential for real-world application in various linguistic contexts.
DependencyAI demonstrates a remarkable capacity to process varied linguistic structures and languages, positioning it as a versatile tool for practical deployment. Evaluations on multilingual detection tasks reveal exceptional performance, with the system achieving both 99.50% accuracy and a 99.50% F1 score when applied to the Russian language. This high level of proficiency extends beyond individual languages, suggesting the method’s robustness in handling the inherent complexities of diverse textual data, and promising reliable operation across a broad spectrum of real-world applications where linguistic variation is commonplace.
DependencyAI demonstrates a notable capacity for domain generalization, a critical attribute for real-world deployment of dependency parsing tools. Performance on the Multilingual Detection Task confirms the model’s reliability across varied text types and linguistic structures, exceeding expectations when tested on unseen domains. Notably, expanding the analysis from individual dependency relations – unigrams – to consider pairs, or bigrams, yielded approximately a 5 percentage point increase in accuracy specifically for the Chinese language, suggesting that capturing relational context significantly enhances the model’s ability to generalize beyond training data and maintain robust performance in diverse scenarios.
The pursuit of identifying artificially generated text, as detailed in DependencyAI, benefits from a focus on underlying structure rather than superficial characteristics. This aligns with a principle of elegant design – removing extraneous elements to reveal the core functionality. The method’s reliance on dependency parsing, discerning how words relate grammatically, embodies this philosophy. Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” DependencyAI doesn’t seek to create detection; it meticulously analyzes the existing structure, revealing the fingerprints of the generative process through a rigorous, systematic approach. It clarifies, rather than complicates, the task of identification.
What Lies Ahead?
DependencyAI isolates a signal. Syntactic structure, it argues, betrays the machine. But abstractions age, principles don’t. The current work demonstrates detection; it does not explain why these structures differ. Future effort must probe the generative models themselves. What constraints, if any, do they impose on dependency relations? Are observed differences inherent limitations, or emergent artifacts of training data?
Multilingual capability is presented, yet true universality remains elusive. Language is not merely statistical variation. Each grammar encodes a unique worldview. DependencyAI’s success across languages suggests underlying principles, but every complexity needs an alibi. Thorough investigation of typologically diverse languages is crucial.
Ultimately, this is a game of cat and mouse. Generative models will adapt. Detection methods must evolve. The long-term goal isn’t simply to label text as “human” or “machine.” It’s to understand the very nature of linguistic creativity – and what it means to be an author.
Original article: https://arxiv.org/pdf/2602.15514.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Top 20 Dinosaur Movies, Ranked
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- The Best Directors of 2025
- Gold Rate Forecast
2026-02-18 12:37