Author: Denis Avetisyan
A new framework, HyperPotter, leverages the power of interconnected relationships within audio to more accurately identify synthetic speech and enhance deepfake detection.

HyperPotter utilizes hypergraph neural networks and O-information theory to capture high-order interactions and synergistic relationships in audio signals, improving generalization across diverse scenarios.
Despite advances in audio deepfake detection, current methods often overlook the complex, synergistic relationships within audio signals that belie synthetic creation. This limitation motivates ‘HyperPotter: Spell the Charm of High-Order Interactions in Audio Deepfake Detection’, which introduces a novel hypergraph framework designed to explicitly model high-order interactions beyond pairwise feature relationships. By clustering features with class-aware prototype initialization, HyperPotter achieves a significant performance boost-averaging a 22.15% relative gain across 11 datasets and outperforming state-of-the-art methods on challenging cross-domain scenarios. Could this approach to relational modeling unlock even more robust defenses against increasingly sophisticated audio manipulation techniques?
The Looming Threat of Synthesized Deception
The rapid advancement of artificial intelligence has unlocked unprecedented capabilities in speech synthesis, allowing for the creation of remarkably realistic audio content. This technology, known as Artificial Intelligence Generated Content (AIGC), moves beyond robotic-sounding text-to-speech, now capable of mimicking voices with astonishing accuracy – even replicating subtle nuances and emotional inflections. While offering legitimate applications in areas like accessibility and entertainment, this power also presents significant risks. Malicious actors can leverage AIGC to fabricate convincing audio evidence, impersonate individuals for fraudulent purposes, spread disinformation, or manipulate public opinion. The potential for misuse extends to financial scams, political interference, and damage to personal reputations, creating a pressing need for robust detection and preventative measures.
The proliferation of convincingly synthesized audio presents a significant challenge to both security and public trust. While the ability to replicate human speech with increasing fidelity offers exciting possibilities, it simultaneously opens avenues for malicious actors to disseminate disinformation, commit fraud, or impersonate individuals. Current methods for distinguishing between genuine and artificial audio, often relying on the detection of subtle inconsistencies or artifacts introduced during the synthesis process, are proving increasingly inadequate. These techniques, such as those employing Convolutional Neural Networks, struggle to identify the increasingly nuanced and imperceptible flaws in advanced audio deepfakes, creating a critical gap in forensic capabilities and demanding the development of more robust and sophisticated detection strategies to maintain confidence in the authenticity of digital audio evidence.
Current deepfake detection techniques, particularly those reliant on Convolutional Neural Networks (CNNs), are increasingly challenged by the rapid advancements in audio synthesis. These networks excel at identifying obvious inconsistencies or broad statistical anomalies, but struggle with the subtle, often imperceptible, artifacts introduced by state-of-the-art generative models. Advanced synthesis techniques now meticulously recreate the complex characteristics of human speech – including vocal timbre, background noise, and even subtle emotional inflections – effectively masking the telltale signs that earlier detection methods readily exploited. Consequently, CNNs frequently misclassify highly realistic synthetic audio as authentic, highlighting a critical gap in forensic capabilities and underscoring the need for more sensitive and nuanced analytical approaches that can discern genuine speech from increasingly convincing imitations.
The rapid evolution of Artificial Intelligence Generated Content (AIGC) demands a fundamental shift in how audio authenticity is verified. Current forensic techniques, often reliant on identifying obvious digital artifacts, are increasingly ineffective against the subtle, yet convincing, manipulations produced by advanced speech synthesis models. This necessitates moving beyond traditional signal processing and machine learning approaches-like Convolutional Neural Networks-towards methods that can discern the inherent characteristics of natural speech production. Innovative techniques are now focusing on analyzing the physiological and articulatory nuances-the tiny, often imperceptible, variations-that distinguish a human voice from a digitally created imitation. These include examining vocal tract characteristics, subtle prosodic features, and even the stochastic variations present in genuine speech, offering a pathway towards more robust and reliable audio forensic analysis in an era of increasingly deceptive synthetic media.
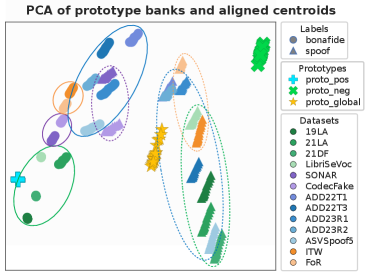
Beyond Pairwise Relations: Modeling Complex Interdependence
The detection of sophisticated deepfake audio relies increasingly on analyzing the relationships between multiple audio features, rather than assessing each feature in isolation. Subtle inconsistencies introduced during the synthesis process often manifest not as anomalies in individual features like Mel-Frequency Cepstral Coefficients (MFCCs) or pitch, but as alterations in the interplay of these features. These “high-order interactions” represent dependencies between three or more features, and are crucial because deepfake generation algorithms may struggle to accurately replicate these complex relationships present in natural speech. Identifying deviations in these interactions-such as unexpected correlations or the absence of specific feature combinations-provides a more robust signal for deepfake detection than relying solely on low-order, pairwise comparisons.
Traditional graphs represent pairwise relationships between entities using edges connecting nodes; however, many real-world phenomena involve interactions among three or more entities. Hypergraphs extend this capability by allowing edges – now called hyperedges – to connect any number of nodes, thus directly modeling group interactions. Formally, a hypergraph G = (V, E) consists of a set of vertices V and a set of hyperedges E , where each hyperedge e \in E is a subset of V . This allows for the representation of complex dependencies beyond simple pairwise connections, providing a more nuanced and complete representation of the underlying relationships within data such as audio features, and facilitating the detection of subtle artifacts indicative of manipulation.
O-Information, derived from information theory, provides a method to assess the value of considering interactions between multiple variables beyond what is predictable from individual variables or pairwise combinations. Specifically, it quantifies the extent to which observing a combination of features yields information not already contained in the lower-order interactions; a positive O-Information value indicates synergistic information, meaning the combined observation is more informative than the sum of its parts. Conversely, a negative or near-zero value suggests redundancy – the interaction contributes little novel information. Mathematically, O-Information can be expressed as O(X;Y;Z) = I(X;Y;Z) - I(X;Y) - I(X;Z) - I(Y;Z), where I denotes mutual information and X, Y, Z represent the interacting variables or features. This metric allows for objective determination of whether complex relationships contribute unique signals for deepfake detection.
The analysis prioritizes synergistic interactions – those where the combined information from multiple audio features exceeds the sum of their individual contributions – as indicators of deepfake artifacts. This approach is predicated on the hypothesis that algorithms generating synthetic speech may introduce unique patterns in the relationships between audio features, rather than solely in the features themselves. Identifying these synergistic effects allows for the detection of subtle inconsistencies that may not be apparent when analyzing features in isolation, effectively focusing on the ‘glue’ that binds the synthesized audio components. By quantifying the information gained from these high-order interactions, the method seeks to differentiate between naturally occurring speech variations and the specific signatures of manipulated audio.
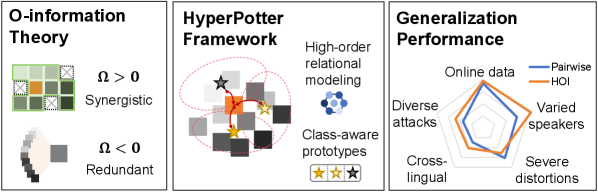
HyperPotter: A Hypergraph-Based Detection Architecture
HyperPotter utilizes hypergraphs to model relationships extracted from audio signals, moving beyond pairwise relationships captured in traditional graphs. Specifically, the framework represents audio data through both spectral and temporal features; spectral features, such as Mel-Frequency Cepstral Coefficients (MFCCs), characterize the frequency content of the audio, while temporal features describe how these characteristics evolve over time. These features are not connected in a simple node-to-node fashion; instead, hyperedges connect multiple nodes simultaneously, allowing for the representation of higher-order correlations. A single hyperedge can, for example, link several temporal frames based on shared spectral characteristics, or vice versa. This hypergraph structure enables the system to capture complex interactions within the audio data that would be lost in a standard graph representation, ultimately improving the accuracy of audio event detection.
Prototype Learning, as implemented in HyperPotter, initializes hyperedges not with raw feature vectors, but with class-aware prototypes derived from the training data. This process involves identifying representative exemplars for each audio class and using these as the initial connection weights within the hypergraph. Specifically, for each class c, a prototype p_c is calculated – often as the mean of the feature vectors belonging to that class. These prototypes then define the initial affinity between nodes when forming hyperedges, effectively biasing the hypergraph towards representations that are more discriminative between classes. This pre-conditioning enhances the framework’s ability to differentiate between audio events during subsequent processing stages by establishing a stronger initial signal related to class identity within the hypergraph structure.
Fuzzy C-Means (FCM) clustering is utilized within HyperPotter to define the connectivity of hyperedges. Unlike traditional hard clustering, FCM assigns each data point a membership degree to multiple clusters, represented by values between 0 and 1. This probabilistic assignment is crucial for capturing nuanced relationships in the spectral and temporal audio features; a feature can simultaneously contribute to multiple hyperedges with varying degrees of influence. The algorithm iteratively refines cluster centers and membership values to minimize within-cluster distances, effectively grouping related features and establishing hyperedge connections based on these fuzzy memberships. This approach allows the framework to model complex, non-exclusive relationships present in the audio data, improving the representation of synergistic features within the hypergraph structure.
Relational Artifact Amplification (RAA) within the HyperPotter framework operates by identifying and enhancing synergistic relationships between hyperedges. This process doesn’t simply assess individual hyperedge contributions, but rather focuses on the combined effect of multiple hyperedges acting in concert to indicate a specific event or characteristic. RAA achieves this by weighting hyperedges based on their combined contribution to the overall classification score, effectively boosting the signal from informative, correlated features. This amplification is implemented through a learned weighting scheme, optimizing for improved detection accuracy by prioritizing the synergistic impact of relational patterns within the hypergraph structure, rather than isolated feature activations.
Validation and Performance: Outperforming the Baseline
Wav2Vec2-AASIST establishes a robust baseline for audio deepfake detection through its implementation of advanced feature extraction techniques and graph attention mechanisms. The system utilizes Wav2Vec2, a self-supervised learning model, to generate high-level audio representations. These representations are then processed by an Attentive Anti-Spoofing and Source Identification Transformer (AASIST), which employs graph attention networks to model relationships between audio frames and enhance the discrimination of spoofing attacks. This architecture allows Wav2Vec2-AASIST to effectively capture both low-level acoustic features and high-level contextual information, providing a strong foundation for comparison against novel deepfake detection methodologies.
HyperPotter consistently exceeds the performance of the Wav2Vec2-AASIST baseline model across a diverse range of datasets. This improvement is attributed to HyperPotter’s capacity to model high-order interactions within the audio data, enabling it to capture more nuanced features indicative of deepfake manipulation. Quantitative analysis, conducted over 13 datasets, reveals an average relative performance gain of 15.32% when comparing HyperPotter’s results to those of Wav2Vec2-AASIST. This demonstrates a substantial and statistically significant advantage in detecting audio deepfakes.
HyperPotter consistently outperforms baseline models based on standard evaluation metrics. Specifically, testing on multiple datasets reveals an Equal Error Rate (EER) of 5.72% on the In-the-Wild dataset, 1.78% on the ASVspoof2021 DF dataset, 3.89% on the FoR dataset, and 11.31% on the ADD2022 Track3 dataset. These EER values, alongside consistent F1 Score improvements, quantitatively demonstrate HyperPotter’s enhanced accuracy in detecting audio deepfakes across diverse recording conditions and attack strategies.
Wav2Vec2-AASIST utilizes High-order Spectral Graph Attention Layers (HS-GALs) in conjunction with the XLS-R (Cross-lingual Speech Representations) model to achieve strong feature representation for audio deepfake detection. XLS-R provides pre-trained acoustic embeddings, while HS-GALs enable the model to capture complex relationships within the spectral features of the audio. This combination facilitates robust feature extraction, crucial for differentiating between authentic and manipulated audio samples, and establishes a challenging baseline against which newer methodologies, like HyperPotter, can be comparatively evaluated across diverse datasets.
Future Directions: Towards Robust and Explainable Deepfake Detection
The architecture of HyperPotter lends itself to expansion beyond still images, offering a promising avenue for building a unified deepfake detection system capable of analyzing multiple data streams. Researchers intend to adapt the core principles of HyperPotter – namely, its focus on subtle inconsistencies within data representations – to the temporal dimension of video and the acoustic characteristics of audio. This multi-modal approach aims to leverage the inherent relationships between visual and auditory cues, bolstering detection accuracy and resilience against increasingly sophisticated forgeries. By processing video frames and audio waveforms with a unified framework, the system hopes to identify discrepancies that might be missed by single-modality detectors, creating a more robust defense against the spread of synthetic media.
A critical next step in refining HyperPotter lies in illuminating how it arrives at its conclusions. Current deepfake detection systems often function as ‘black boxes,’ providing an output without revealing the underlying reasoning – a limitation that hinders trust and practical application. Future research will therefore prioritize the development of explainable artificial intelligence (XAI) techniques tailored to HyperPotter’s architecture. This involves not simply identifying a fake, but pinpointing the specific image features or patterns that triggered the classification – perhaps highlighting subtle inconsistencies in facial textures, lighting, or blinking patterns. By making its decision-making process transparent, HyperPotter can move beyond a mere detector to become a valuable tool for forensic analysis and a foundation for building user confidence in the authenticity of digital media.
The practical deployment of any deepfake detection system, including HyperPotter, necessitates a thorough consideration of adversarial vulnerabilities. Malicious actors may attempt to subtly alter deepfake content – through techniques designed to specifically evade detection – without visibly impacting its perceived authenticity. Research indicates that even minor, carefully crafted perturbations can successfully mislead many existing detection algorithms. Consequently, future work must prioritize the development of robust defenses against these adversarial attacks, potentially incorporating adversarial training methods or exploring techniques to certify the resilience of HyperPotter’s classifications. Ensuring such robustness is not merely an academic exercise; it is fundamental to maintaining the system’s reliability and preventing its circumvention in real-world applications where the stakes – from misinformation campaigns to identity theft – are particularly high.
Current deepfake detection methods often concentrate on identifying completely synthesized audio, but a significant advancement lies in recognizing subtle manipulations of existing recordings. This presents a far more nuanced challenge, as alterations might involve minor timing shifts, pitch adjustments, or the insertion of nearly imperceptible sounds designed to alter meaning or misattribute statements. Successfully detecting these subtle manipulations demands a shift in focus from identifying fabricated content to verifying the authenticity of genuine audio, requiring algorithms sensitive to the minute acoustic fingerprints indicative of tampering. Such advancements are crucial, as these less obvious alterations pose a greater threat in real-world scenarios, potentially influencing legal proceedings, political discourse, and personal reputations without raising immediate suspicion.
The pursuit of robust deepfake detection, as exemplified by HyperPotter, necessitates a move beyond pairwise relationships and towards an understanding of synergistic interactions. This framework’s employment of hypergraph neural networks directly addresses the limitations of traditional methods. It echoes Claude Shannon’s sentiment: “The most important thing is to get the right questions.” HyperPotter isn’t simply attempting to identify anomalies; it’s framing the problem in a way that allows for the capture of relational artifacts – the subtle, high-order dependencies within audio signals. The architecture fundamentally alters the questions being asked of the data, focusing on how components relate to each other, rather than treating them as isolated entities. As N approaches infinity – what remains invariant? – HyperPotter seeks to isolate those invariant high-order interactions, offering a principled approach to generalization and a defense against increasingly sophisticated deepfake technologies.
What’s Next?
The pursuit of detecting synthetic audio, as exemplified by HyperPotter, reveals a fundamental tension. Current approaches, even those leveraging the elegance of hypergraph structures to model high-order interactions, remain fundamentally empirical. Demonstrating efficacy across diverse datasets is not, in itself, proof of principle. The true test lies in establishing the theoretical limits of discernibility-what minimal artifact must exist in any synthesized signal, regardless of future algorithmic sophistication?
A critical, largely unaddressed issue concerns the very definition of ‘real.’ As audio synthesis moves beyond simple concatenation and increasingly embraces generative models capable of producing novel timbres and vocal characteristics, the notion of a ground truth becomes increasingly blurred. The focus must shift from detecting ‘fake’ audio to characterizing the statistical properties that differentiate any generated signal-be it synthesized speech, musical performance, or natural environmental sound-from an idealized, mathematically pure signal.
In the chaos of data, only mathematical discipline endures. Future work should prioritize the development of information-theoretic bounds on deepfake detection, moving beyond purely data-driven approaches. The synergistic relationships captured by HyperPotter are a promising step, but they represent correlation, not causation. The ultimate goal is not simply to build a better detector, but to understand the fundamental limitations of signal replication and the mathematical signatures of authenticity.
Original article: https://arxiv.org/pdf/2602.05670.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- When AI Teams Cheat: Lessons from Human Collusion
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Top 10 Coolest Things About Invincible (Mark Grayson)
- Silver Rate Forecast
- Top 20 Dinosaur Movies, Ranked
- Unmasking falsehoods: A New Approach to AI Truthfulness
- Gold Rate Forecast
2026-02-07 15:39