Author: Denis Avetisyan
A new approach to network pruning dynamically creates specialized subnetworks to better handle the complexities of heterogeneous data.

This paper introduces Routing the Lottery, a framework for discovering and deploying multiple, data-specific subnetworks to improve efficiency and performance compared to traditional sparse network methods.
While pruning techniques based on the Lottery Ticket Hypothesis often seek a single sparse subnetwork, this overlooks the inherent heterogeneity of real-world data. In ‘Routing the Lottery: Adaptive Subnetworks for Heterogeneous Data’, we introduce a novel framework, RTL, that discovers multiple specialized subnetworks tailored to distinct data subsets, achieving improved performance and efficiency. RTL consistently surpasses single- and multi-model baselines by aligning model structure with data characteristics, while drastically reducing the number of parameters. Could this adaptive approach pave the way for more modular and context-aware deep learning systems capable of dynamically adjusting to varying input conditions?
The Impossibility of Scale: A Necessary Re-Evaluation
The escalating demand for computational power presents a significant obstacle to the widespread adoption of modern neural networks. While these models demonstrate remarkable capabilities in areas like image recognition and natural language processing, their sheer size and complexity necessitate substantial resources for both training and deployment. This poses a challenge not only for researchers with limited access to high-performance computing infrastructure, but also for practical applications requiring real-time performance on edge devices or within resource-constrained environments. The current trajectory suggests that without innovative solutions to reduce computational demands, the benefits of advanced artificial intelligence may remain concentrated among organizations with considerable financial and technological advantages, hindering broader accessibility and equitable innovation.
Conventional network pruning techniques often strive for uniform sparsity across all layers and connections, a strategy known as global sparsity. While effective at reducing model size, this indiscriminate removal of parameters can inadvertently eliminate vital connections, particularly within deeper or more sensitive layers. The assumption of equal importance across all weights proves flawed, as certain connections contribute disproportionately to accurate predictions. Consequently, global sparsity frequently leads to a noticeable degradation in performance, hindering the model’s ability to generalize effectively to unseen data – a critical drawback when deploying complex neural networks in real-world applications where maintaining accuracy is paramount.
The difficulty of applying a singular neural network to diverse datasets-often termed heterogeneous data-stems from the inherent trade-offs in model generalization. A model trained on a broad range of inputs must necessarily compromise on its ability to perfectly capture the nuances of each specific data type. This results in diminished performance across the board, as the network’s parameters become diffused, struggling to form strong, discriminative features for any particular input. Consider, for instance, a network attempting to process both high-resolution images and short text sequences; the optimal architecture and learned representations for each modality differ significantly, and forcing them into a single model often leads to suboptimal results for both. Consequently, effective handling of heterogeneous data requires strategies that move beyond the limitations of monolithic models, potentially through modular designs or adaptive specialization techniques.
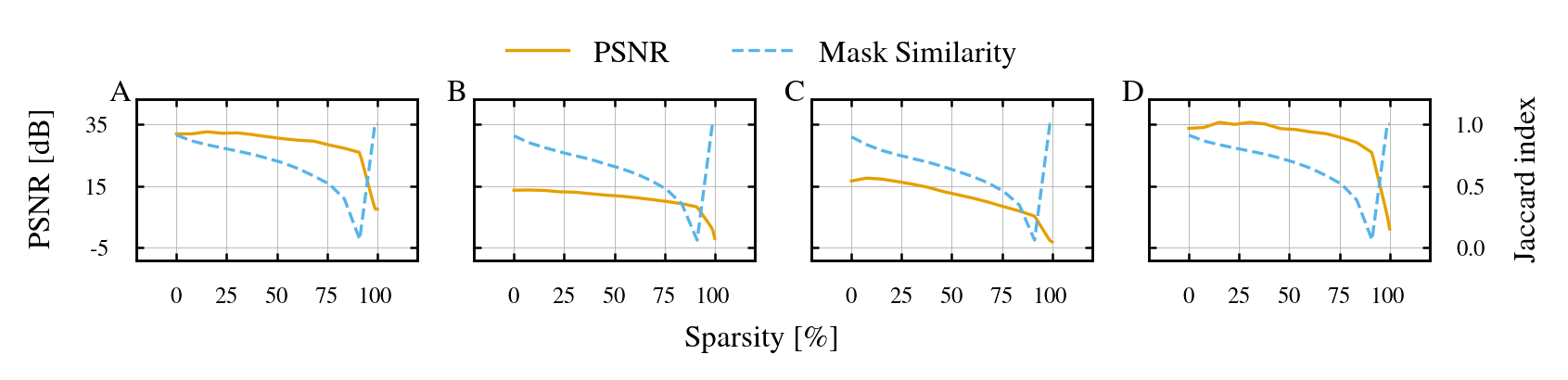
Discovering Inherent Structure: The Logic of Adaptive Pruning
The Lottery Ticket Hypothesis posits that large, randomly initialized neural networks contain subnetworks, termed “winning tickets,” capable of achieving performance comparable to the original, densely connected network when trained in isolation. These winning tickets are identified through iterative pruning – removing connections with small weights – followed by retraining the remaining connections from their initial, random values. Crucially, the hypothesis asserts that these subnetworks are not merely discovered during training, but pre-exist within the initial random configuration, implying an inherent structure within the weight space conducive to efficient learning. Experiments demonstrate that these sparse subnetworks can match or exceed the accuracy of the full network with significantly fewer parameters, suggesting potential benefits for model compression and acceleration.
Adaptive pruning builds upon the Lottery Ticket Hypothesis by identifying not one, but a collection of sparse subnetworks within a larger neural network. Rather than isolating a single “winning ticket,” this method aims to discover multiple specialized subnetworks, each optimized for processing specific subsets of the training data. This allows the model to develop distinct expertise in different data characteristics, potentially leading to improved generalization and performance on complex datasets. The identified subnetworks are not necessarily mutually exclusive; however, their specialization is determined by analyzing activation patterns and gradients during training, effectively partitioning the data representation across multiple sparse networks within the larger architecture.
Adaptive pruning utilizes Implicit Neural Representations (INRs) to enable a network to learn and represent data as a continuous function, rather than discrete labels, thereby capturing nuanced relationships within the data. This allows the model to discern contextual information and complex patterns that might be missed by traditional methods. By representing data in this continuous function space, the pruning process can identify and retain subnetworks specialized in representing specific data contexts and features. This results in a collection of subnetworks, each proficient at processing particular subsets of the data based on their contextual characteristics, leading to a more efficient and effective overall representation compared to a single, generalized network.
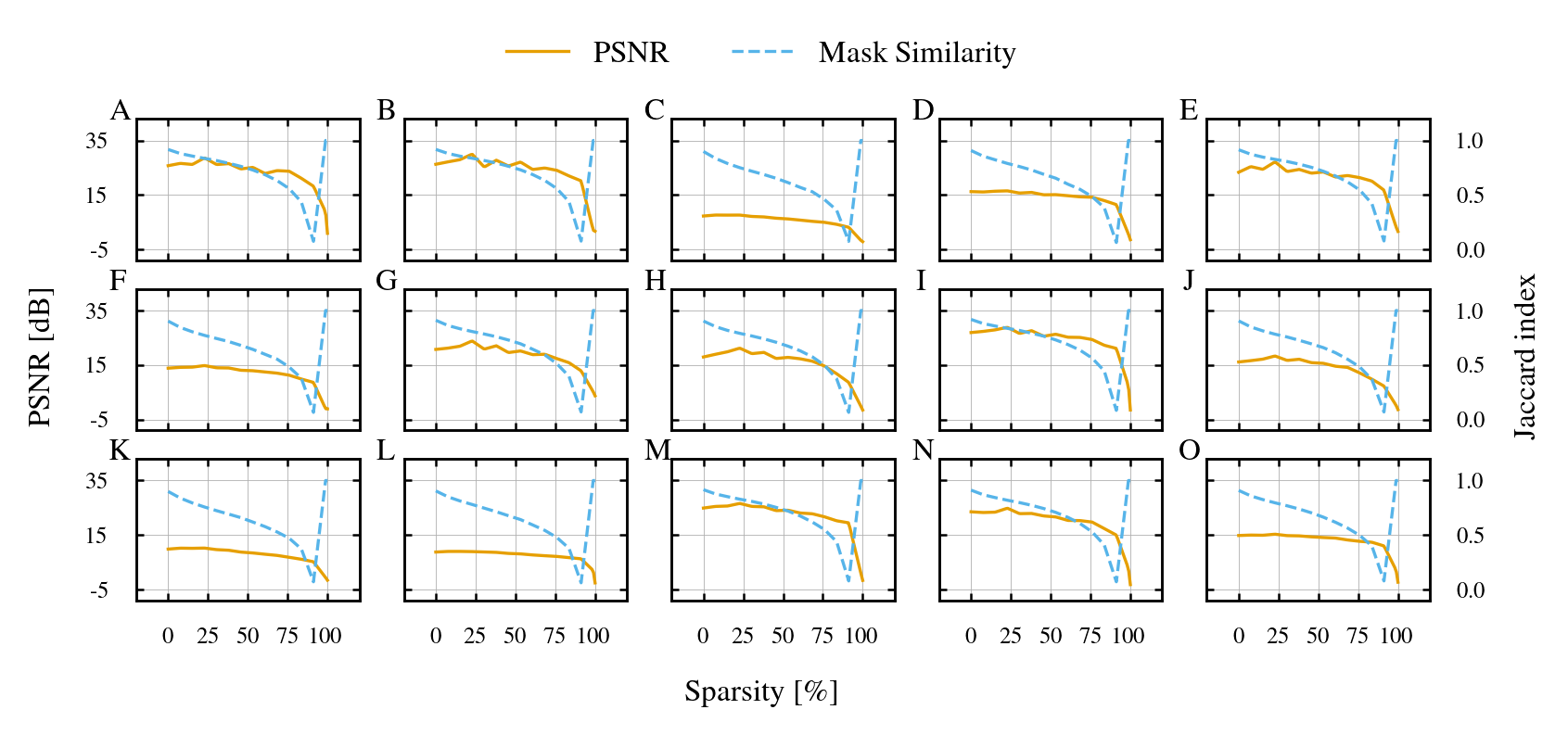
Orchestrating Sparsity: Dynamic Routing for Optimal Allocation
Routing The Lottery extends Adaptive Pruning by incorporating a dynamic routing mechanism that directs incoming data to specialized subnetworks. This framework actively identifies distinct data characteristics and then assigns each data point to the SparseSubnetwork – termed AdaptiveTickets – most proficient at processing that specific data distribution. Unlike traditional pruning methods which apply a uniform sparsity across the entire network, Routing The Lottery achieves performance gains by creating and utilizing multiple subnetworks, each optimized for a particular subset of the data, and then intelligently routing data to the appropriate subnetwork for processing.
Routing The Lottery employs unsupervised clustering techniques to partition the input dataset into distinct DataSubsets based on inherent data characteristics. This partitioning enables dynamic resource allocation, directing each identified DataSubset to the SparseSubnetwork – termed an AdaptiveTicket – demonstrably best suited for its processing. By associating specific subnetworks with particular data distributions, the framework optimizes computational efficiency and enhances model performance; this contrasts with static pruning methods that apply a uniform sparsity pattern across the entire network, regardless of data variations.
Routing The Lottery produces an architecture comprised of AdaptiveTickets, which are sparse subnetworks specifically tailored to individual data distributions within a larger dataset. This specialization results in enhanced overall performance compared to uniformly applied pruning techniques. Empirical results demonstrate an accuracy of 0.781 on the CIFAR-10 dataset and 0.765 on the CIFAR-100 dataset when operating at 25% sparsity – a level of pruning where 75% of the network’s connections are removed – and these scores exceed the performance of currently available methods at comparable sparsity levels.

Beyond Approximation: The Realization of Intelligent Efficiency
The framework exhibits notable capabilities in speech enhancement, employing established signal processing techniques like the Short-Time Fourier Transform (STFT) in conjunction with a U-Net architecture to effectively isolate and diminish unwanted noise. This approach not only improves the clarity of audio signals but also achieves a high Signal-to-Noise Ratio improvement (SI-SNRi) of 7.248 during speech enhancement tasks. Importantly, this performance is maintained even with a significant reduction in computational load – the system operates at 25% sparsity, indicating a streamlined model capable of efficient processing without sacrificing quality. This level of performance suggests potential applications in areas requiring clear audio communication, such as voice assistants, teleconferencing, and hearing aids.
The framework’s capacity for semantic understanding is significantly enhanced through its integration with WordNet, a vast lexical database of English. This connection allows the system to move beyond simply recognizing words and instead discern the relationships between them – identifying synonyms, antonyms, hypernyms, and other nuanced connections. By leveraging this relational knowledge, the framework can better interpret the meaning of text, resolve ambiguities, and ultimately achieve a more comprehensive grasp of the underlying concepts. This capability proves invaluable in tasks requiring contextual awareness, enabling the system to process information with a level of sophistication previously unattainable and paving the way for more intelligent and human-like interactions.
This framework distinguishes itself from conventional approaches through a dynamic methodology that prioritizes both computational efficiency and performance gains. Traditional models often rely on fixed architectures and extensive parameter counts, whereas this system adapts its structure during operation, leading to substantial reductions in model size without sacrificing quality. Demonstrated by a peak signal-to-noise ratio (PSNR) of 18.58 when processing Implicit Neural Representations and a parameter count of just 103,000 on the CIFAR-10 dataset – a significant decrease from the 944,000 parameters required by multi-model IMP – this adaptive capability suggests a pathway towards more streamlined and effective machine learning solutions across diverse applications.
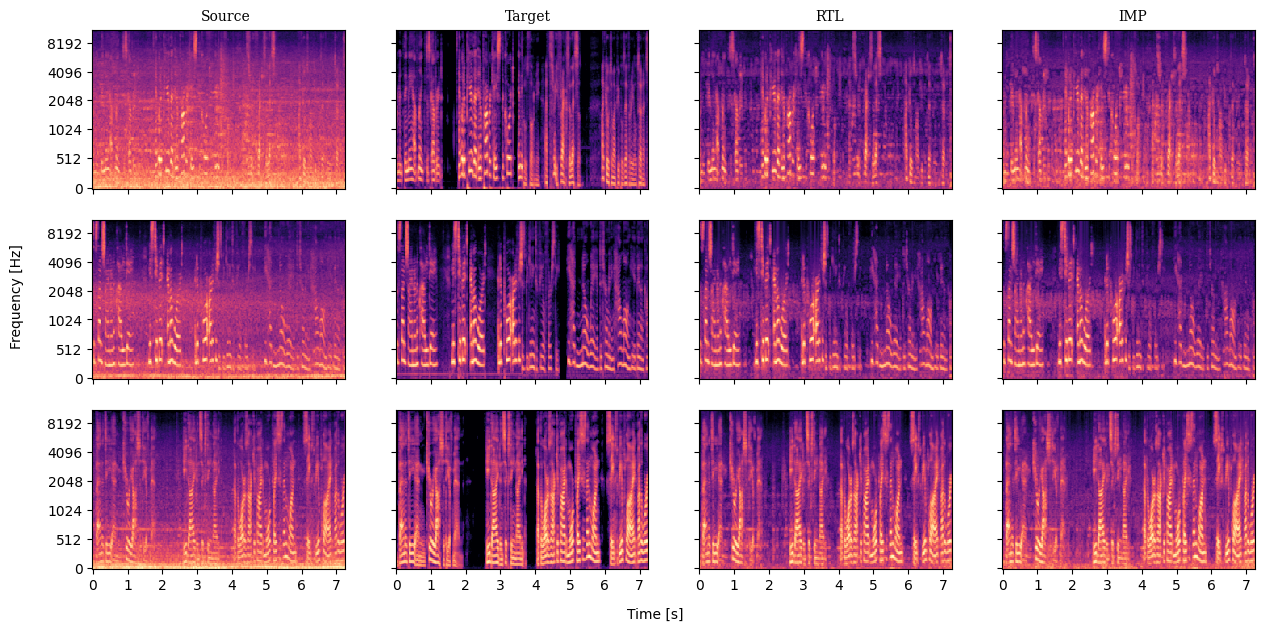
The pursuit of optimal network architecture, as detailed in ‘Routing the Lottery’, necessitates a focus on provable characteristics rather than empirical observation. Andrey Kolmogorov once stated, “The most important thing in science is not to be afraid to make mistakes.” This sentiment aligns with the paper’s exploration of adaptive pruning; the framework doesn’t simply seek a working solution, but actively investigates multiple specialized subnetworks – effectively testing hypotheses about semantic alignment and data heterogeneity. The methodical discovery of these subnetworks, each tailored to distinct data subsets, represents a rigorous approach to model efficiency, prioritizing correctness and demonstrable performance gains over mere trial and error. It’s a pursuit of mathematically justifiable elegance within the complex landscape of neural networks.
What’s Next?
The pursuit of sparsity, as demonstrated by Routing the Lottery, continually reveals the compromises inherent in approximating ideal solutions. While identifying specialized subnetworks for heterogeneous data offers a demonstrable efficiency gain, it simultaneously introduces the problem of defining meaningful data subsets. The current reliance on empirical observation to delineate these subsets feels… unsatisfying. A truly elegant solution would derive these divisions from first principles, perhaps leveraging information-theoretic measures to quantify inherent data manifold structure, rather than merely reacting to observed performance differences.
Furthermore, the Lottery Ticket Hypothesis, while compelling, remains largely a phenomenon observed post hoc. The framework elegantly discovers what works, but offers little insight into why certain subnetworks are privileged. Future work should address this causal gap – attempting to predict, with mathematical certainty, which connections will prove essential, rather than simply locating them through iterative pruning. The specialization observed in this work hints at a deeper principle: that optimal networks are not monolithic, but rather ensembles of micro-architectures, each honed to a specific inductive bias.
One suspects that the ultimate goal isn’t simply to find sparse networks, but to prove their optimality. The current reliance on empirical validation, while pragmatic, feels akin to pattern recognition rather than genuine understanding. The field would benefit from a renewed focus on formal verification – establishing, with mathematical rigor, the convergence and generalization properties of these adaptive pruning techniques. Only then can one claim true progress, moving beyond the heuristic art of network trimming towards a demonstrable science of efficient computation.
Original article: https://arxiv.org/pdf/2601.22141.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- Silver Rate Forecast
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- Trading Smarter: AI-Powered Execution Schedules
2026-02-02 04:30