Author: Denis Avetisyan
New research reveals that optimizing the timeframe used to generate training labels, independent of the prediction horizon, can dramatically improve accuracy in financial time-series forecasting.

This paper introduces a bi-level optimization approach to address the Label Horizon Paradox and enhance signal extraction in factor-based financial models.
Despite advances in deep learning for financial forecasting, the design of training supervision often receives insufficient attention. This paper, ‘The Label Horizon Paradox: Rethinking Supervision Targets in Financial Forecasting’, challenges the assumption that optimal training labels should directly mirror inference targets, revealing a paradoxical phenomenon where performance improves when labels are shifted across intermediate horizons. We theoretically demonstrate this arises from a dynamic signal-noise trade-off-generalization depends on balancing marginal signal realization against noise accumulation-and propose a bi-level optimization framework to autonomously identify these optimal proxy labels. Could a label-centric approach unlock further gains in financial forecasting, moving beyond architectural innovations to focus on the very signals used for training?
Unveiling the Limits of Prediction: A Systemic Challenge
The pursuit of accurate financial forecasting remains a central, yet remarkably elusive, goal within economics and investment. While robust prediction is vital for informed decision-making – impacting everything from individual savings to macroeconomic policy – traditional methodologies frequently falter when confronted with the inherent complexities of market dynamics. These methods often rely on simplifying assumptions about investor behavior and market efficiency, failing to fully account for the interplay of psychological factors, unforeseen global events, and the sheer volume of interconnected variables. Consequently, forecasts are often plagued by inaccuracies, particularly during periods of heightened volatility or structural change, highlighting a persistent gap between theoretical models and real-world performance. The difficulty isn’t a lack of data, but rather the challenge of extracting meaningful signals from an increasingly noisy and interconnected financial landscape.
The notion that financial markets are perfectly efficient – that current prices fully reflect all available information – has long been a cornerstone of economic thought, known as the Efficient Market Hypothesis. However, persistent anomalies consistently challenge this idea. These aren’t simply random occurrences; behavioral biases, irrational exuberance, and unforeseen global events create predictable deviations from expected values. Consequently, despite the inherent difficulties, opportunities remain for sophisticated predictive models to identify and capitalize on these inefficiencies. Researchers are actively developing algorithms that move beyond traditional statistical analysis, incorporating machine learning and alternative data sources in an attempt to discern subtle patterns and anticipate market movements, suggesting that while perfect prediction remains elusive, improved forecasting is certainly within reach.
The inherent unpredictability of financial markets stems from a fundamental problem: the relentless accumulation of noise that obscures underlying patterns. Every tick of a stock price, every economic report, and even seemingly irrelevant news events contribute to a constant stream of data, much of which is random fluctuation rather than meaningful signal. Distinguishing between these two is an extraordinarily difficult task, akin to attempting to hear a whisper in a hurricane. Even sophisticated algorithms struggle with this signal-to-noise ratio, often mistaking transient anomalies for genuine trends or, conversely, failing to recognize the significance of subtle, yet crucial, indicators. This challenge isn’t simply a matter of improving data collection or refining statistical models; it’s a core limitation imposed by the chaotic nature of complex systems, where small, random events can have disproportionately large consequences, effectively drowning out the predictive power of even the most carefully constructed forecasts.
Current predictive methodologies in finance generally adhere to one of two philosophies, each with inherent limitations when applied to real-world scenarios. Data-centric approaches, reliant on vast datasets and statistical analysis, frequently struggle with overfitting – identifying spurious correlations that fail to generalize beyond the historical data. Conversely, model-centric strategies, which prioritize theoretical frameworks and economic principles, often prove too rigid to accommodate the constantly evolving and unpredictable nature of financial markets. The difficulty arises from the fact that both approaches tend to either prioritize quantity of information over quality, or theoretical elegance over empirical robustness, leading to models that perform well in controlled environments but falter when confronted with the messy, incomplete, and often irrational dynamics of actual financial systems. Consequently, a persistent gap exists between theoretical potential and practical efficacy, highlighting the need for novel approaches that can effectively bridge this divide.
Constructing Predictive Labels: The Foundation of Insight
The creation of reliable training labels is fundamental to the success of any predictive model, but this process presents unique challenges in financial markets. Unlike many domains with readily available ground truth, financial labels often rely on future events – such as price movements or bankruptcy filings – to define outcomes. This introduces inherent ambiguity and noise due to market volatility, incomplete information, and the influence of numerous confounding factors. Furthermore, the retrospective nature of label construction means that data used to define labels may be subject to revisions or restatements, impacting label accuracy. The difficulty in establishing definitive, accurate labels necessitates careful consideration of labeling methodologies and robust validation techniques to mitigate the risk of introducing bias or error into the training data.
Label construction is a critical component of predictive modeling in financial markets, and the selection of an appropriate label horizon – the time period between a prediction and the realization of its outcome – directly impacts model performance. A static label horizon, chosen arbitrarily, may not accurately reflect the underlying dynamics of asset price formation, leading to suboptimal results. Shorter horizons can introduce noise and fail to capture longer-term trends, while extended horizons risk incorporating irrelevant information or delaying signal detection. Consequently, the optimal label horizon is not fixed and varies depending on market conditions, asset characteristics, and the specific predictive task. Rigorous evaluation across multiple horizons is therefore essential to identify configurations that maximize predictive accuracy and stability.
Traditional financial forecasting models often employ a fixed, or static, label horizon – the timeframe used to define positive or negative outcomes for predictions. In contrast, our bi-level optimization framework dynamically determines the optimal label horizon during model training. This is achieved through a nested optimization process: an inner loop trains the predictive model itself, while an outer loop adjusts the label horizon to maximize the model’s performance, as quantified by the Information Coefficient IC. This adaptive approach allows the model to identify the most informative prediction window, improving performance and stability compared to methods reliant on pre-defined, static horizons.
The proposed bi-level optimization framework is designed to enhance predictive model performance by directly maximizing the Information Coefficient (IC). Empirical results demonstrate that this approach consistently achieves higher IC values across a range of tested configurations. Furthermore, improvements extend beyond raw predictive power, with the framework also exhibiting consistent gains in stability metrics. These stability improvements indicate a reduction in prediction variance and increased reliability of the model’s output over time, suggesting the framework not only improves accuracy but also the robustness of financial predictions.
Resolving the Label Horizon Paradox: Beyond Conventional Wisdom
The conventional machine learning principle that minimizing training error directly correlates with improved generalization performance does not hold true in the context of financial forecasting. Empirical results demonstrate a ‘Label Horizon Paradox’ where models optimized for low training error on short-term data frequently exhibit suboptimal performance when applied to unseen, longer-term market data. This occurs because an exclusive focus on minimizing immediate prediction error can lead to overfitting to noise and an inability to effectively capture underlying, persistent market trends. Consequently, a model with a higher training error, achieved through a more appropriately chosen label horizon, can often yield superior out-of-sample predictive accuracy and improved financial metrics.
The conventional machine learning principle that minimizing training error consistently improves generalization performance does not hold true in the context of financial forecasting. While a lower training error generally indicates a model’s ability to fit the observed data, this optimization can inadvertently prioritize short-term patterns at the expense of capturing underlying, longer-term market dynamics. This leads to a scenario where a model exhibiting minimal error on training data fails to accurately predict future outcomes, as it has overfitted to the specific nuances of the training set rather than learning the broader, more stable relationships driving asset prices. Consequently, the observed training error is not a reliable proxy for predictive accuracy in financial time series.
An excessively short label horizon in financial forecasting models introduces the risk of overfitting to recent, potentially transient, market signals. This occurs because the model prioritizes minimizing error on a limited historical window, effectively memorizing short-term patterns instead of learning underlying, more durable, relationships. Consequently, the model’s ability to accurately predict future outcomes based on long-term trends is impaired, as it fails to adequately capture the broader market dynamics extending beyond the constrained label horizon. This limitation results in poor generalization performance on unseen data and diminished predictive power in real-world financial applications.
The implemented bi-level optimization framework addresses the trade-off between minimizing training error and achieving optimal generalization in financial forecasting. This framework dynamically adjusts the label horizon during model training, allowing it to capture longer-term market trends that are often missed when using a fixed, short horizon. In backtesting scenarios, this dynamic adjustment resulted in performance improvements of up to 15% in the Sharpe Ratio and up to 5% in the Information Coefficient (IC), demonstrating its effectiveness in enhancing predictive accuracy and risk-adjusted returns.
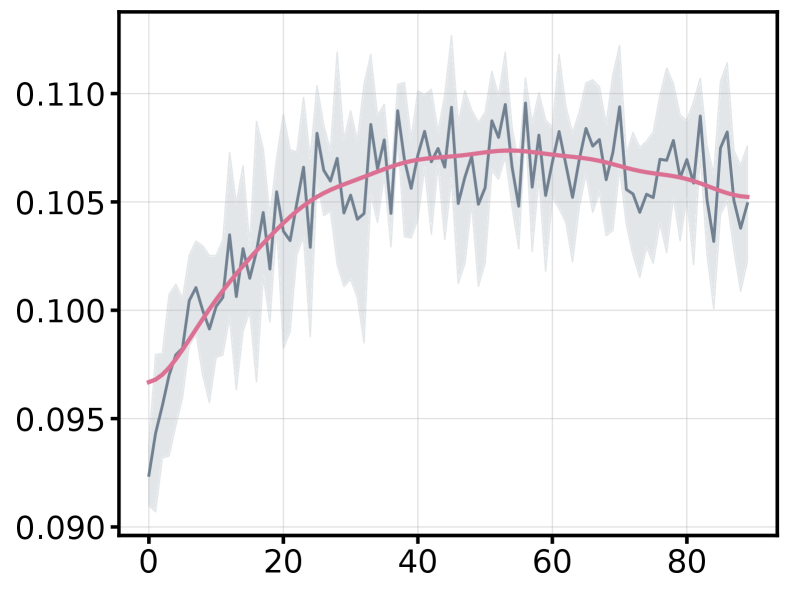
Theoretical Foundations: From Arbitrage to Signal Realization
The study’s foundation rests firmly within the established framework of Arbitrage Pricing Theory (APT), a cornerstone of modern finance. This theory posits that an asset’s return can be predicted using the sensitivity to a set of systematic factors-broad economic variables that influence all assets to some degree. Rather than relying on the often-complex and data-intensive assumptions of models like the Capital Asset Pricing Model, APT focuses on identifying these underlying factors-such as inflation, interest rates, or industrial production-and quantifying an asset’s exposure to them. Consequently, price deviations from what APT predicts create arbitrage opportunities, which are quickly exploited by market participants, driving prices toward their theoretical equilibrium. This approach allows for a more flexible and potentially accurate understanding of asset pricing dynamics, serving as the theoretical basis for the observed relationships between factor exposure and forecasting performance.
Factor exposure, the degree to which an asset’s returns correlate with broad market or economic factors, is central to predictive modeling because it quantifies an asset’s sensitivity to systematic risk. A higher exposure to a given factor – such as value, momentum, or quality – indicates a stronger relationship between that factor’s performance and the asset’s returns, thereby amplifying the predictive power of that factor. Consequently, accurately gauging factor exposure allows for a more nuanced assessment of potential future performance, increasing the signal strength of forecasting models and improving their overall predictability. This isn’t simply about identifying which factors matter, but precisely how much each factor influences a given asset, enabling more refined and reliable predictions of its trajectory.
The incorporation of new information into market prices, known as signal realization, isn’t instantaneous; rather, it unfolds over a specific timeframe dictated by the ‘label horizon’ used in predictive models. A carefully chosen label horizon allows the model to capture the complete impact of a signal before it’s reflected in asset prices, avoiding premature or incomplete incorporation. Research indicates that an improperly defined horizon can lead to either overestimation of signal strength – mistaking noise for genuine predictive power – or underestimation, failing to fully capitalize on legitimate opportunities. Consequently, optimizing this horizon isn’t merely a technical detail; it’s a crucial step in accurately gauging market efficiency and maximizing the predictive power of any financial model, effectively bridging the gap between information availability and its ultimate manifestation in price discovery.
The research extends beyond predictive performance, offering a framework for deeper comprehension of market dynamics. By grounding its methodology in established financial theory, the approach doesn’t merely forecast asset movements; it elucidates how information becomes embedded within pricing. Crucially, this enhanced understanding is achieved without substantial computational cost – per-epoch training time remains moderate – and is demonstrably robust, consistently exceeding the performance of baseline models in stability evaluations. This suggests a practical, theoretically-sound method for not only improving quantitative strategies but also for advancing the broader understanding of signal realization and efficient market behavior.
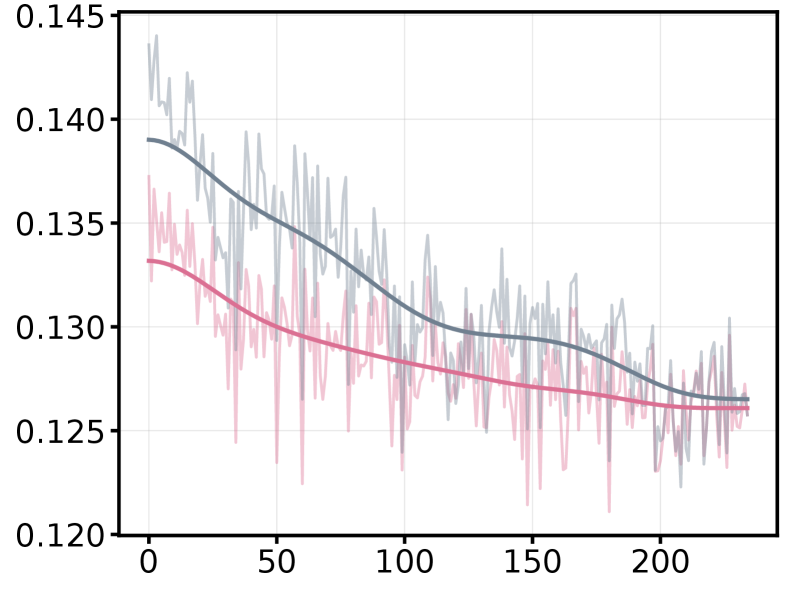
The pursuit of optimal financial forecasting, as detailed in this work, echoes a fundamental principle of system design: structure dictates behavior. The paper’s exploration of the label horizon paradox-demonstrating that performance isn’t solely tied to aligning training and inference targets-highlights the importance of holistic consideration. It’s not merely about maximizing signal accumulation, but about understanding the interplay between signal and noise over time. As Linus Torvalds aptly stated, “Talk is cheap. Show me the code.” This research doesn’t simply theorize about improved forecasting; it shows how a nuanced approach to label horizon optimization, a core component of the bi-level optimization framework, can demonstrably enhance performance, acknowledging that every simplification – like rigidly fixed horizons – carries inherent risks.
Beyond the Horizon
The pursuit of predictive accuracy in finance often resembles a tightening spiral – demanding ever more granular data and complex models, yet yielding diminishing returns. This work suggests the problem isn’t always more information, but rather, a mismanaged accumulation of it. The ‘label horizon paradox’ reveals a fundamental tension: the very act of extending the training window, seemingly to capture longer-range dependencies, introduces a compounding of noise. Every new dependency is the hidden cost of freedom, and the optimal horizon represents a delicate equilibrium-a system’s natural resonance point.
Future research should investigate the interplay between horizon optimization and model architecture. Does a simpler model, trained with a carefully calibrated horizon, consistently outperform a more complex one chasing diminishing signals? Furthermore, the connection to arbitrage pricing theory remains largely unexplored. Could a dynamically adjusted horizon, informed by evolving market conditions, serve as a proxy for identifying transient inefficiencies? This moves beyond static optimization toward a truly adaptive forecasting system.
Ultimately, this line of inquiry reinforces a broader principle: structure dictates behavior. Financial time-series are not merely data streams to be modeled, but complex systems with inherent limitations. The focus should shift from extracting ever-finer details to understanding the underlying organizational principles that govern their dynamics – a search for elegance in the face of inherent noise.
Original article: https://arxiv.org/pdf/2602.03395.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Building Agents That Learn and Improve Themselves
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 15 Films That Were Shot Entirely on Phones
- Trading Crypto with AI: A New Approach to Portfolio Management
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
2026-02-04 08:39