Author: Denis Avetisyan
A massive analysis of 100 trillion tokens reveals a surprising shift in how artificial intelligence models are deployed, moving past simple tasks toward complex, agentic workflows.
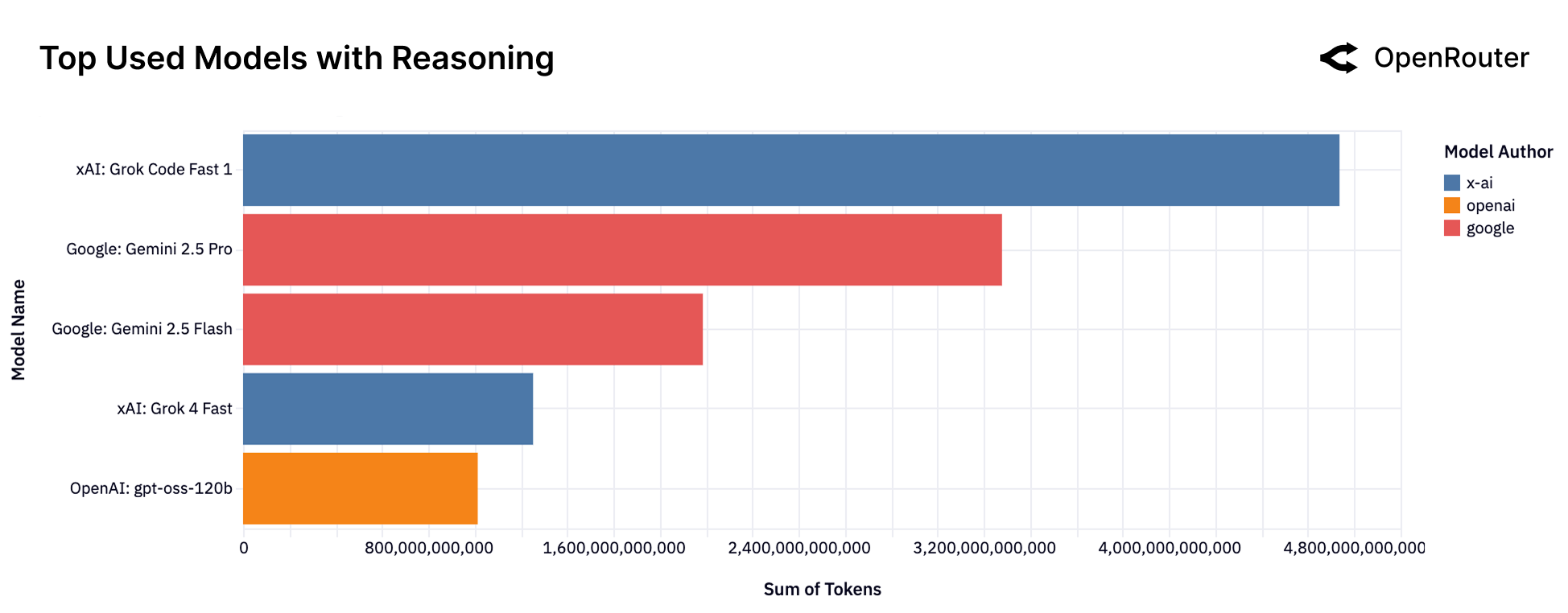
Empirical analysis of real-world usage patterns using OpenRouter data highlights the growing prominence of open-source models and the need for nuanced performance evaluation.
Despite rapid advancements in large language models (LLMs), a comprehensive understanding of their real-world application has lagged behind development. This is addressed in ‘State of AI: An Empirical 100 Trillion Token Study with OpenRouter’, which analyzes over 100 trillion tokens of LLM interactions to reveal emerging usage patterns. Our findings demonstrate substantial adoption of open-weight models, a surprising prevalence of creative applications alongside coding, and the rise of agentic inference-challenging assumptions about LLM deployment. How can these data-driven insights inform the design and optimization of future LLM systems and better align them with evolving user needs?
The Inevitable Shift: Beyond Prediction to Agency
Initial large language models demonstrated remarkable proficiency in identifying and replicating patterns within vast datasets, essentially functioning as sophisticated text completion engines. However, this capability was fundamentally limited by an inability to perform complex reasoning that requires multiple sequential steps or the application of abstract concepts. While adept at predicting the next word in a sequence, these early models struggled with tasks demanding planning, problem-solving, or the integration of diverse information – hallmarks of genuine intelligence. The absence of such multi-step reasoning capabilities meant they often produced outputs that, while grammatically correct and contextually relevant, lacked depth, originality, or the ability to navigate nuanced situations effectively. This limitation spurred research into architectures capable of moving beyond simple pattern matching towards more robust and adaptable cognitive processes.
The evolution from predictive language models to agentic systems necessitates a fundamental rethinking of artificial intelligence architecture. Traditional models, proficient at identifying patterns and generating continuations, fall short when confronted with tasks requiring deliberate planning, sequential execution, and iterative refinement. Agentic inference – the capacity to formulate goals, decompose them into actionable steps, utilize external tools, and critically evaluate progress – demands architectures that move beyond simple feedforward processing. Current research explores incorporating elements of reinforcement learning, memory networks, and hierarchical planning to enable models to not only respond to prompts, but to proactively pursue objectives and adapt strategies based on observed outcomes. This shift represents a move towards artificial intelligence capable of autonomous problem-solving, pushing the boundaries of what’s possible with machine intelligence.
The progression beyond text generation necessitates that modern AI systems become adept at leveraging external tools to enhance their capabilities. Current research demonstrates a shift where large language models are no longer confined to producing linguistic output; instead, they are being designed to interact with – and ultimately control – a variety of resources. This includes accessing databases for information retrieval, utilizing APIs to perform specific actions like sending emails or making calculations, and even controlling physical devices. This ‘tool-use’ isn’t simply about adding functionality; it fundamentally alters the nature of the AI, enabling it to solve problems that require real-world interaction and complex, multi-step reasoning beyond the scope of its training data. The ability to effectively orchestrate these tools is becoming a defining characteristic of advanced AI, marking a move towards systems that do things, rather than merely talk about them.
Architectural Undercurrents: Enabling Agentic Reasoning
Recent large language models, including OpenAI’s o1 (Strawberry) and Anthropic’s Sonnet 2.1 & 3, are significantly advancing agentic reasoning capabilities by leveraging increased computational resources and extended deliberation time. These models move beyond simple response generation by incorporating the capacity for more complex, multi-step problem solving. The expansion of computational scale allows for the processing of larger contexts and the execution of more intricate reasoning chains. Increased deliberation time enables these models to iteratively refine their approaches and evaluate potential solutions before arriving at a final output, resulting in demonstrably improved performance on tasks requiring planning and complex decision-making.
Modern large language models are incorporating internal planning and refinement capabilities to enhance agentic performance. This is achieved through multi-step reasoning, where the model outlines a sequence of actions before execution. A critical enabler of this functionality is the use of structured tool-planning tokens, as exemplified by Cohere’s Command R model. These tokens allow the model to explicitly represent and manipulate plans – defining which tools to use and in what order – before interacting with external systems. The model can then iteratively refine these plans based on the results of each step, leading to more robust and accurate outcomes compared to single-step execution.
Recent large language models (LLMs) exhibit enhanced performance capabilities through the implementation of Retrieval-Augmented Generation (RAG) and advanced tool utilization. RAG improves accuracy and reduces hallucination by grounding responses in external knowledge sources retrieved during the generation process. Sophisticated tool use extends model functionality beyond text generation, enabling interaction with APIs and external services to perform tasks like calculations, data analysis, or accessing real-time information. This combination allows LLMs to move beyond simple information recall and engage in more complex reasoning and action-oriented tasks, resulting in demonstrably improved performance across a range of benchmarks and applications.
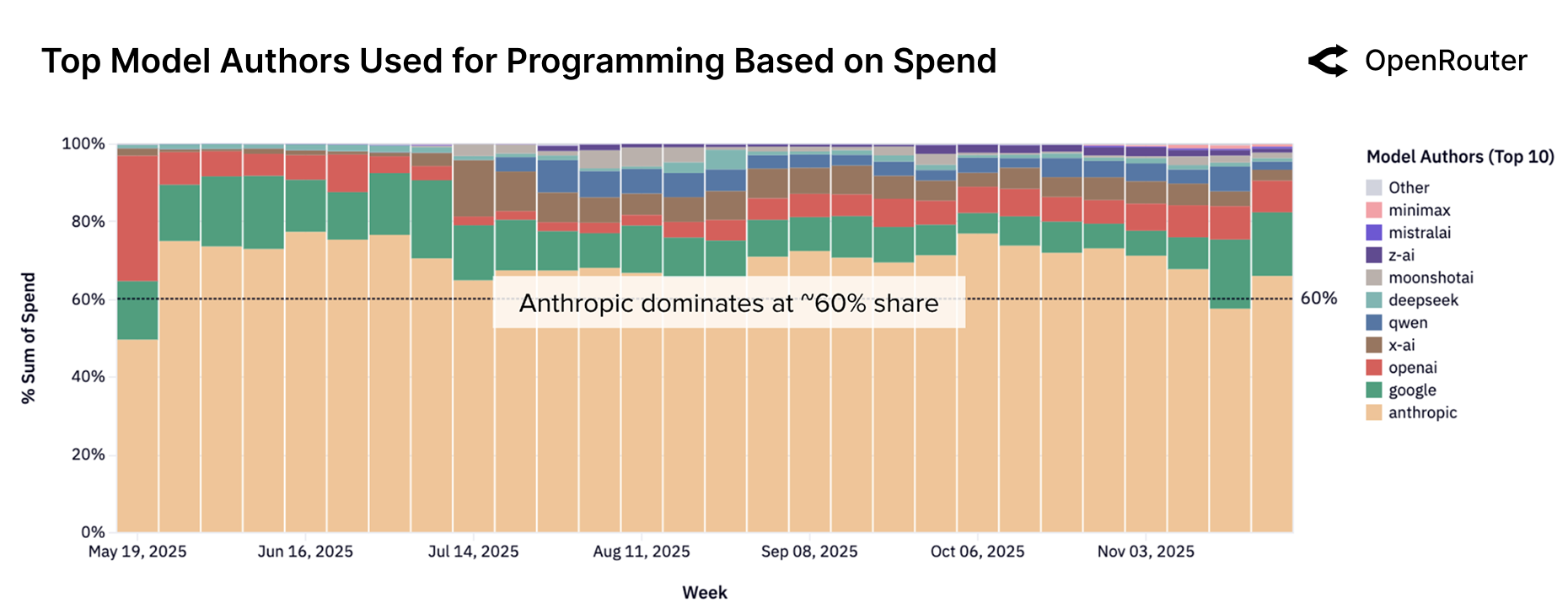
Observed Patterns: The Landscape of Real-World Usage
The OpenRouter platform, aggregating usage data across multiple large language models, demonstrates that Programming Tasks and Roleplay Tasks constitute the majority of token consumption. Analysis of platform data indicates these two categories consistently account for over 70% of all tokens processed. Programming tasks encompass code generation, debugging, and related functionalities, while Roleplay Tasks involve interactive scenarios and character simulations. This data is derived from millions of requests processed through the OpenRouter API, providing a statistically significant view of real-world LLM application trends and highlighting the prevalent use cases driving demand for LLM resources.
The OpenRouter platform utilizes GoogleTagClassifier to categorize both incoming prompts and generated completions, enabling granular analysis of LLM application types. This classification system identifies specific task categories, such as code generation, question answering, creative writing, and roleplaying, allowing for detailed tracking of usage patterns. By tagging prompts and completions, OpenRouter can quantify the distribution of different task types, measure token consumption per category, and identify emerging trends in LLM application development. The resulting data facilitates a deeper understanding of how developers are utilizing the platform and which use cases are driving the majority of LLM inference requests.
Data from the OpenRouter platform demonstrates a rising trend in the utilization of Agentic Inference across both programming and roleplaying applications. This paradigm, where language models are used as agents to perform tasks autonomously, is contributing significantly to overall token consumption. Recent analysis indicates that programming tasks, specifically leveraging Agentic Inference, now account for over 50% of total tokens consumed on the platform, exceeding the contribution from all other use cases. This shift validates the increasing importance of Agentic Inference as a key driver of language model workload and suggests a growing demand for autonomous agent capabilities.
Analysis of OpenRouter platform data demonstrates a substantial increase in average prompt token length, rising from 1.5 thousand tokens to over 6 thousand tokens. This trend indicates a move towards more elaborate and detailed prompts, suggesting users are providing significantly more context and instructions to language models. The increase in token usage per prompt correlates with the growing prevalence of complex tasks, such as agentic workflows and sophisticated programming requests, which require extensive input to achieve desired outcomes. This shift necessitates increased computational resources and highlights the growing demand for models capable of processing lengthy input sequences.
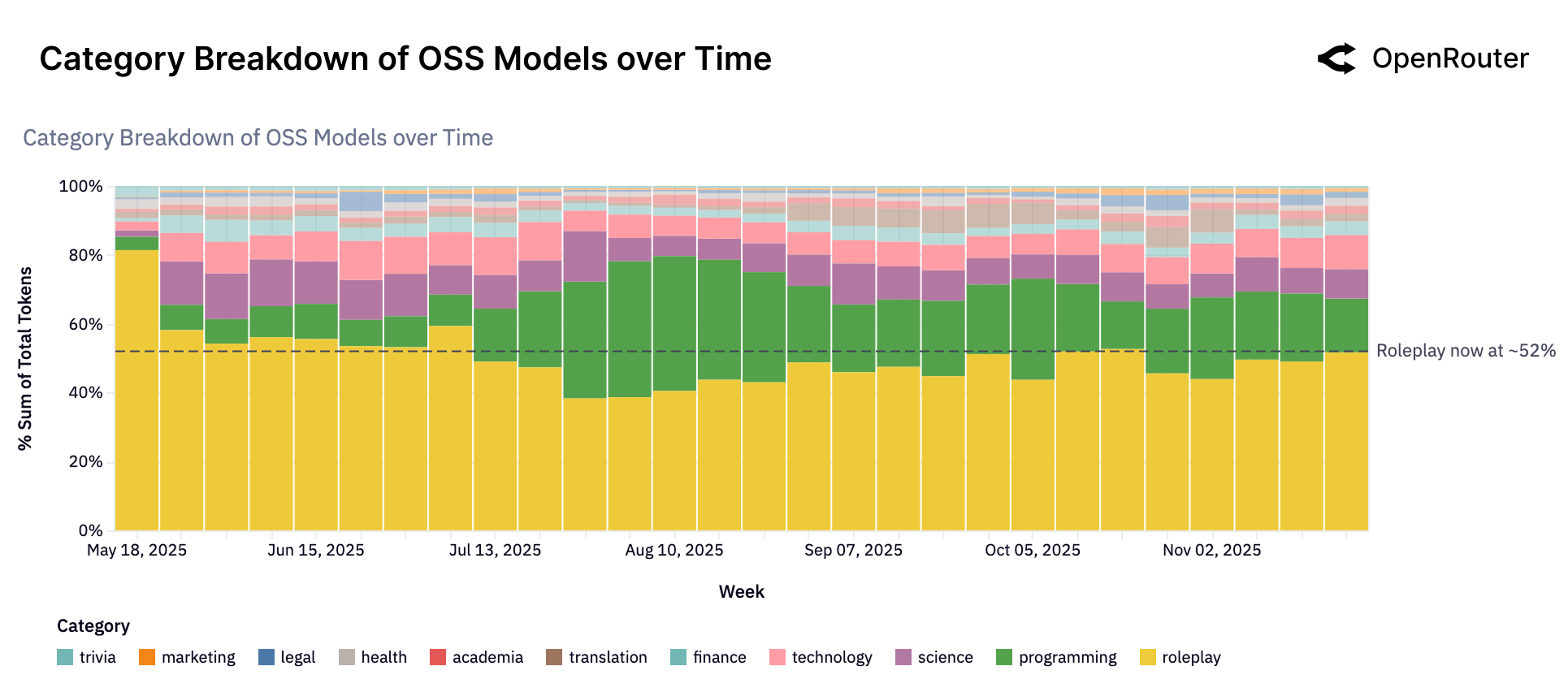
Echoes of Scale: Economic Currents and Distributional Shifts
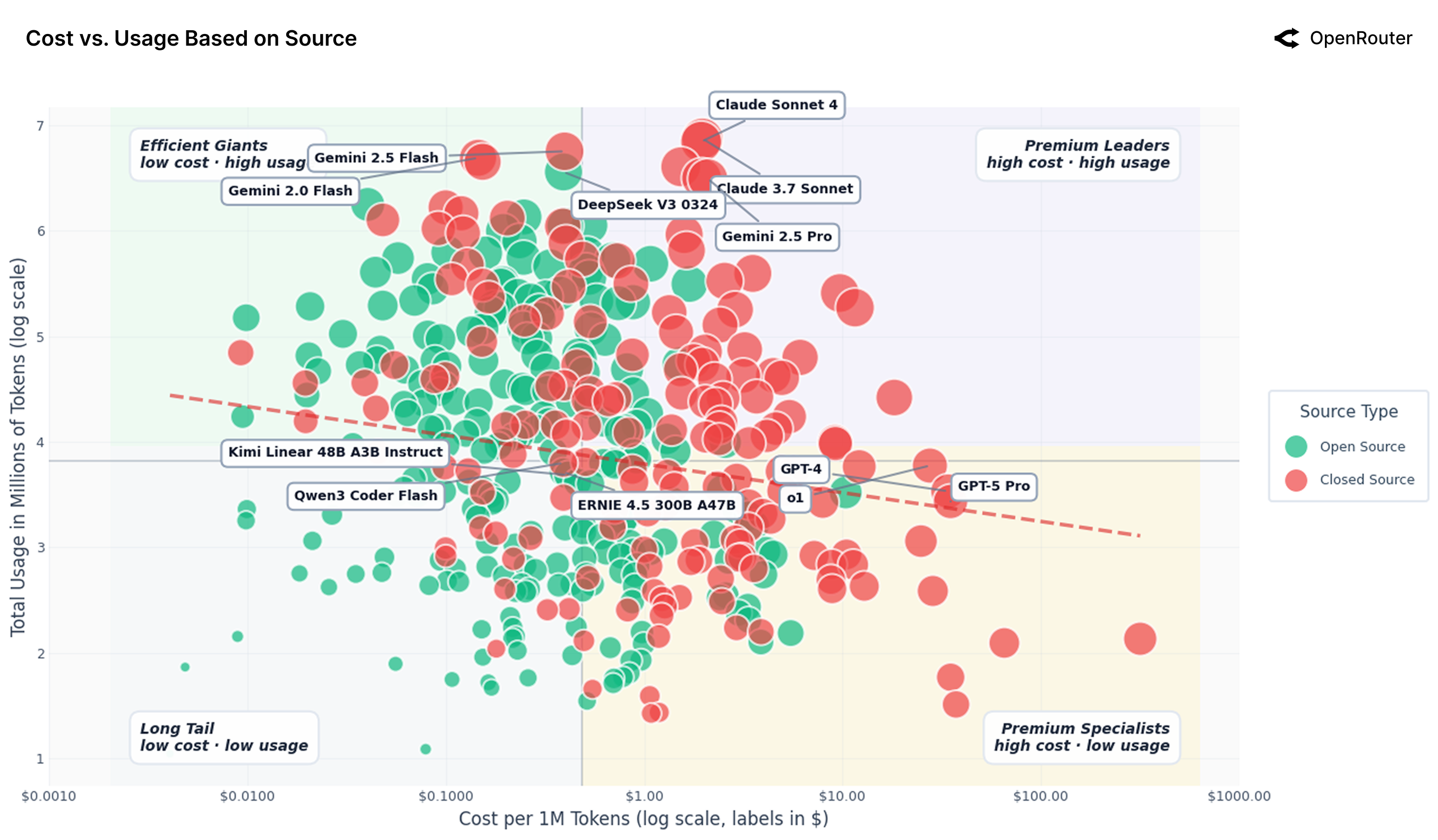
Analysis of data from the OpenRouter platform reveals a compelling correlation between the cost of utilizing large language models and their rate of usage. This relationship suggests diminishing returns as demand increases, prompting concerns about the long-term economic viability of current growth patterns. As more users access these models, the cost per token processed rises, potentially creating a feedback loop where increasing costs limit accessibility and hinder further expansion. This dynamic challenges the assumption of perpetually decreasing costs associated with technological advancement and necessitates a critical examination of pricing models, resource allocation, and the potential for sustainable scaling within the rapidly evolving LLM landscape. The observed trends indicate that continued, unchecked growth may not be economically feasible without significant innovation in model efficiency or alternative funding mechanisms.
The increasing efficiency of large language models, while promising, introduces the risk of a Jevons Paradox – a phenomenon where technological progress actually increases resource consumption. As models become cheaper and more capable – requiring less computational power per task – demand is likely to surge, potentially offsetting any gains made through efficiency improvements. This isn’t simply about electricity; it encompasses the energy required for data storage, network transmission, and the manufacturing of hardware. Without careful consideration of usage patterns and the implementation of strategies to mitigate increased demand – such as incentivizing responsible AI practices or exploring alternative computing paradigms – the environmental benefits of more efficient models could be negated, leading to unsustainable resource utilization and hindering long-term progress in the field.
The proliferation of open-weight large language models is reshaping the geographic landscape of artificial intelligence development and access. While offering unprecedented opportunities for community-driven innovation – allowing researchers and developers in regions historically excluded from AI leadership to participate directly – the distribution remains uneven. Initial analyses reveal a concentration of activity around established tech hubs, raising concerns that existing digital divides may be exacerbated. This disparity isn’t simply about access to computational resources; it also reflects variations in data availability, linguistic diversity in training datasets, and the presence of skilled AI practitioners. Consequently, while open-weight models hold the potential to democratize AI, realizing this promise requires deliberate strategies to foster inclusive participation and mitigate the risk of creating new forms of technological inequality, ensuring benefits extend beyond already privileged locations.
Recent data from the OpenRouter platform demonstrates a significant shift in the landscape of large language models, with open-source models now accounting for over 30% of total token volume processed. This figure signifies a substantial and rapidly expanding presence within the LLM ecosystem, challenging the dominance of previously closed-source alternatives. The increasing adoption suggests a democratization of access to powerful AI technologies, driven by factors such as cost-effectiveness, customizability, and community-led innovation. This trend isn’t merely incremental; it indicates a fundamental restructuring of how language models are developed, deployed, and utilized, potentially fostering a more diverse and resilient AI future.
Future Trajectories: Expanding Context and Sustainable Growth
The pursuit of increasingly expansive Long Context Windows represents a pivotal advancement in artificial intelligence, directly enabling more sophisticated agentic workflows and reasoning. These expanded windows allow models to process and retain information from significantly larger inputs – effectively extending their ‘memory’ and contextual understanding. This capability is not merely about handling greater volumes of text; it facilitates complex tasks requiring the integration of information spread across lengthy documents, multi-turn conversations, or extended sequences of actions. Consequently, models equipped with long context windows can perform nuanced analyses, generate more coherent and relevant responses, and autonomously manage tasks demanding sustained reasoning – moving beyond simple pattern recognition towards genuine cognitive abilities. The development of these windows promises to unlock AI’s potential in fields like legal document analysis, complex scientific research, and personalized education, where retaining and synthesizing large amounts of contextual information is paramount.
Sustained utility hinges on understanding how users interact with the model over time, making ongoing Retention Analysis paramount. Initial studies focusing on foundational user cohorts reveal approximately 40% continued engagement at the five-month mark, a crucial baseline for gauging long-term viability. This metric isn’t simply a count of active users; detailed behavioral data captured through this analysis provides actionable insights into feature utilization, identifies areas for model refinement, and ultimately informs strategies to enhance user experience and ensure continued value. By closely tracking these patterns, developers can proactively address potential drop-off points, optimize performance based on real-world usage, and foster a more robust and enduring relationship between users and the AI system.
The proliferation of open-weight models represents a pivotal shift in artificial intelligence development, moving beyond closed, proprietary systems to encourage widespread participation and accelerate innovation. By making model weights publicly available, researchers and developers gain unprecedented access to the foundational building blocks of AI, fostering a collaborative environment for experimentation, refinement, and the creation of novel applications. This open approach not only democratizes access to advanced AI technologies, empowering smaller organizations and individual creators, but also enhances model robustness and trustworthiness through community-driven auditing and improvement. A thriving ecosystem built around these open-weight models promises to unlock a far broader range of AI-powered solutions, addressing diverse needs and accelerating the realization of AI’s potential benefits for all.
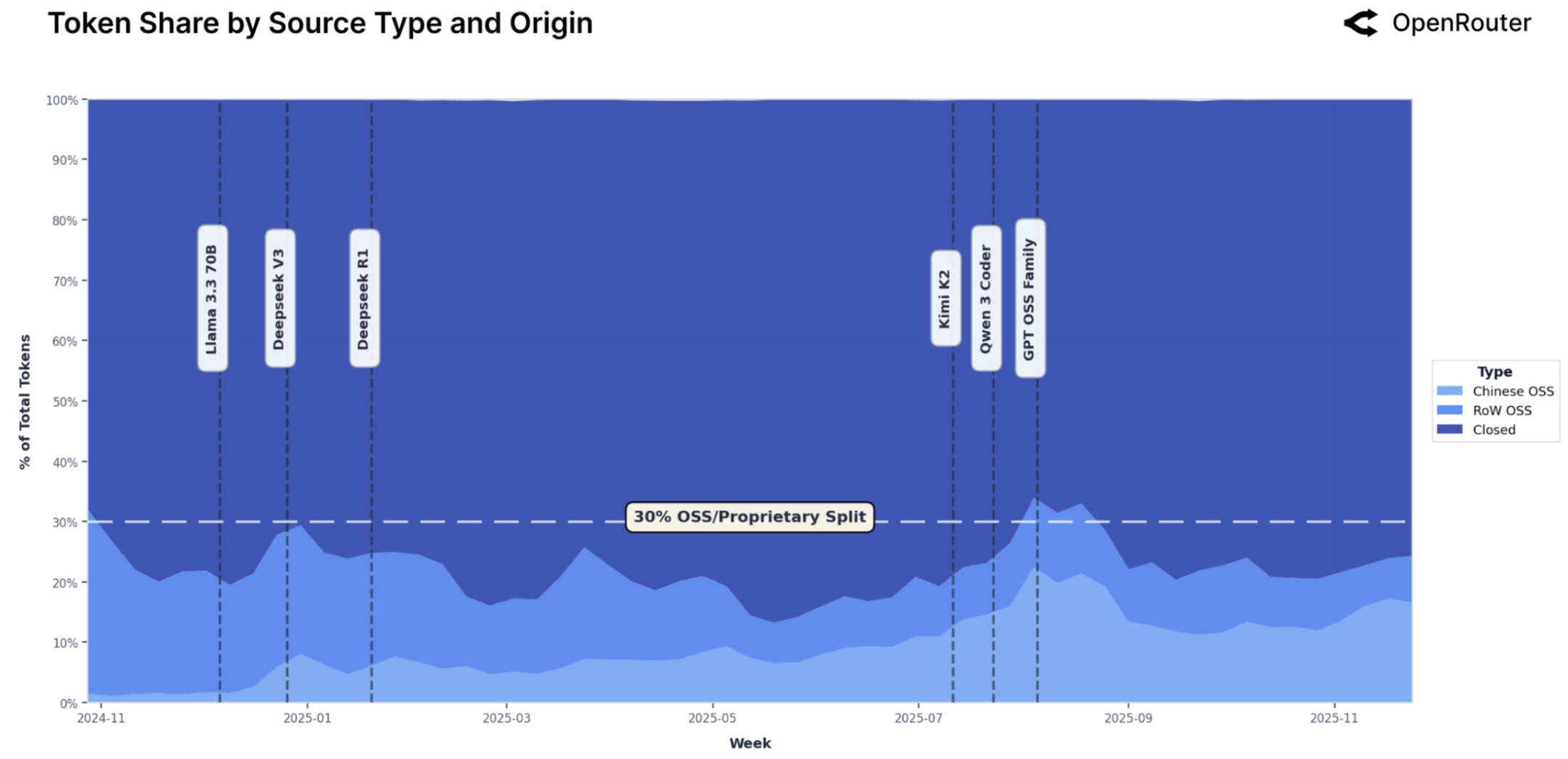
The study illuminates a predictable trajectory: systems, even those built on the ostensibly modular architecture of large language models, inevitably accrue dependencies. As agentic inference gains prominence – the models acting less as passive responders and more as autonomous agents – these interconnections multiply, increasing systemic risk. This echoes Henri Poincaré’s observation: “It is through science that we arrive at certainty, but it is through art that we learn to live with uncertainty.” The research demonstrates that simple benchmarks fail to capture the complexities of real-world LLM usage, and therefore, evaluation must embrace the inherent unpredictability of these growing ecosystems. The shift towards open-source models, while democratizing access, merely redistributes the points of potential failure within the larger, interconnected system.
What Lies Ahead?
The accumulation of tokens – one hundred trillion, in this instance – does not reveal a destination, but a drift. This work demonstrates, yet again, that metrics conceived in isolation quickly become archaeological artifacts. The shift towards agentic inference wasn’t predicted, merely observed – a reminder that systems reveal their purpose through use, not design. Architecture isn’t structure – it’s a compromise frozen in time, and the ice is always thinning.
The rising prominence of open-source models suggests a fracturing, a move away from centralized prediction. This is not necessarily progress. Dependencies, like entropy, simply redistribute. The cost-performance curves will continue to shift, of course, but the fundamental problem remains: evaluating intelligence requires observing it in situ, embedded within the messy, unpredictable environment it inhabits. Benchmarks are echoes in a cave; they tell one nothing of the landscape beyond.
Further analysis will undoubtedly refine the granularity of these observations. Yet, the deeper question persists: are these models solving problems, or merely rearranging them? The study of usage patterns is valuable, but it’s a cartography of symptoms, not causes. The true frontier lies not in building better systems, but in understanding the ecosystems they inevitably become.
Original article: https://arxiv.org/pdf/2601.10088.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- The Best Directors of 2025
2026-01-17 09:34