Author: Denis Avetisyan
New research explores how combining the strengths of artificial intelligence can unlock deeper insights from lengthy financial reports and earnings calls.
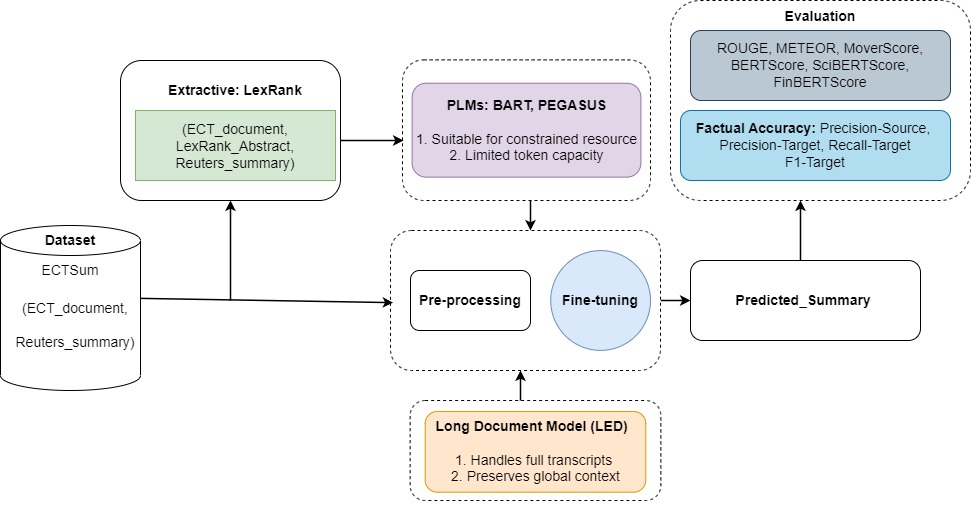
This review investigates hybrid extractive-abstractive transformer models, including Longformer, to improve both the quality and factual consistency of financial document summarization.
Analyzing voluminous financial reports and earnings calls is increasingly inefficient for timely business insights, yet manual review remains prevalent. This paper, ‘Enhancing Business Analytics through Hybrid Summarization of Financial Reports’, introduces a novel framework combining extractive and abstractive transformer models-including Longformer-to automatically generate concise and factually sound summaries from financial texts. Results demonstrate that while long-context models offer superior overall performance, a hybrid approach effectively balances quality and computational demands, improving factual consistency. Could these findings pave the way for more robust and scalable summarization systems capable of distilling critical information from complex financial data?
The Illusion of Insight: Why Summaries Still Need Humans
For investors navigating today’s rapidly evolving financial landscape, efficiently processing information from sources like earnings calls is paramount, yet current automated summarization techniques often fall short. These complex documents, rich in quantitative data and qualitative assessments, demand more than simple extraction of key sentences; nuanced understanding of financial terminology and contextual awareness are essential. While automated systems aim to condense lengthy transcripts into digestible briefs, they frequently struggle with both accuracy – ensuring factual correctness in the summary – and conciseness – delivering information without unnecessary verbosity. This presents a significant challenge, as inaccurate or incomplete summaries can lead to poorly informed investment decisions, highlighting the need for advanced methods that balance comprehensive coverage with succinct presentation.
Early attempts at automating financial text summarization relied heavily on extractive methods – identifying and stitching together key sentences directly from the source material. While computationally inexpensive and guaranteeing factual consistency, these techniques often failed to capture the subtle arguments and contextual nuances vital for informed investment decisions. Conversely, abstractive summarization – generating new sentences that convey the meaning of the original text – proved prone to “hallucinations,” introducing inaccuracies or misrepresenting financial data. The inherent complexity of financial language, coupled with the high stakes involved, means that even seemingly minor factual errors can have significant consequences, necessitating a balance between conciseness, accuracy, and the preservation of critical insights.
The sheer scale of modern financial data presents a significant hurdle for effective summarization. Daily, investors are bombarded with earnings reports, regulatory filings, news articles, and analyst commentary – documents often exceeding thousands of words. Processing this volume requires techniques capable of handling exceptionally long sequences of text without succumbing to information loss or computational bottlenecks. Simply shortening these documents isn’t enough; summaries must retain critical financial details and nuanced arguments. Consequently, research focuses on developing models that efficiently compress information while preserving factual accuracy and avoiding the introduction of misleading interpretations, a challenge demanding innovative approaches to sequence modeling and attention mechanisms.
Transformers: Another Layer of Abstraction (and Potential Error)
Transformer models, including BART, PEGASUS, and LED, represent a significant advancement in abstractive summarization techniques. These models utilize the self-attention mechanism, allowing them to weigh the importance of different parts of the input text when generating a summary. This capability is crucial for capturing long-range dependencies within documents, enabling the model to understand the relationships between words and phrases that are far apart. Unlike extractive summarization, which selects and combines existing sentences, abstractive summarization generates new sentences, requiring the model to both understand and rephrase the source material; the self-attention mechanism is key to effectively performing this task.
While transformer-based models demonstrate strong capabilities in generating human-readable summaries, their implementation presents considerable computational demands, requiring substantial processing power and memory. Furthermore, these models are susceptible to factual inconsistencies; despite fluent output, summaries may contain information not present in the source document or misrepresent original details. This issue stems from the generative nature of the models, which prioritizes linguistic coherence over strict adherence to source facts, necessitating ongoing research into methods for improving factual grounding and reliability.
Fine-tuning transformer models, specifically Longformer Encoder-Decoder (LED), has demonstrated performance gains in the task of summarizing financial transcripts; however, results are not uniform across datasets. Quantitative evaluation, as reported by Mukherjee et al., indicates a ROUGE-1 score of 0.467 and a ROUGE-2 score of 0.307 when utilizing a fine-tuned LED model for this application. These ROUGE scores represent recall-oriented understudy for gisting evaluation metrics, assessing the overlap of unigrams (ROUGE-1) and bigrams (ROUGE-2) between generated summaries and reference summaries.
Metrics and Mirage: What Do Those Numbers Actually Mean?
ROUGE and METEOR are established automatic evaluation metrics for text summarization that function by calculating the overlap of n-grams between a generated summary and one or more reference summaries; ROUGE focuses on recall, while METEOR incorporates precision and recall alongside stemming and synonym matching. However, these metrics are limited in their ability to assess semantic similarity because they primarily focus on lexical overlap and do not fully capture paraphrasing or understand the meaning of the text. Consequently, summaries that convey the same information using different wording may receive low scores, and summaries containing factual inaccuracies can be rated highly if they share sufficient lexical overlap with the reference summaries. This reliance on surface-level features makes them susceptible to manipulation and provides an incomplete assessment of summarization quality.
BERTScore and MoverScore represent advancements in summarization evaluation by moving beyond simple lexical overlap to assess semantic similarity. These metrics utilize contextual embeddings – vector representations of words generated by models like BERT – to capture the meaning of text. Instead of directly comparing words, they calculate similarity scores based on the embedding distances between words or phrases in the candidate and reference summaries. This allows for the identification of paraphrases and captures relationships beyond exact matches, providing a more nuanced evaluation of semantic fidelity than traditional metrics like ROUGE. The resulting scores reflect the degree to which the candidate summary conveys the same meaning as the reference, even if different wording is used.
Domain-specific adaptations of contextual embedding-based metrics, such as FinBERTScore for financial text and SciBERTScore for scientific literature, enhance summarization evaluation by accounting for specialized terminology and semantic nuances not captured by general-purpose metrics. However, even these adapted metrics are not without limitations; performance varies depending on the specific dataset and summarization technique employed. Recent evaluations indicate that BERTScore consistently achieves the highest overall scores, demonstrating superior performance in capturing semantic similarity. Conversely, the LED (Longformer Encoder-Decoder) model exhibits strong performance specifically regarding Precision-source and Recall-target metrics, suggesting its effectiveness in preserving source information and accurately capturing target content, respectively.
Datasets and Delusions: Chasing Factual Consistency
The ECTSum dataset is composed of 1,472 earnings call transcripts sourced from publicly available SEC filings, paired with corresponding summaries created by financial analysts. These transcripts represent quarterly earnings announcements from companies across diverse sectors, offering a substantial corpus for training and evaluating financial summarization models. The expert summaries serve as ground truth references, allowing for quantitative assessment of generated summaries through metrics like ROUGE and BERTScore. Notably, the dataset’s structure facilitates both abstractive and extractive summarization tasks, and its focus on a specific financial domain allows for targeted model development and performance analysis relevant to the complexities of financial language and reporting.
Factual consistency represents a significant obstacle in financial text summarization, specifically the tendency of models to generate content not directly supported by, or even contradictory to, the source document – a phenomenon termed “hallucination.” In the context of financial reporting, such inaccuracies can have serious consequences, including misinformed investment decisions and regulatory violations. This issue arises from the inherent complexity of financial language, the need for nuanced understanding of numerical data and qualitative statements, and limitations in current natural language generation techniques. Mitigating hallucination requires both improved model architectures and the development of robust evaluation metrics specifically designed to identify and penalize factually inconsistent summaries.
Effective evaluation of financial text summarization systems necessitates the use of datasets such as ECTSum and metrics that specifically assess factual accuracy. Recent performance benchmarks demonstrate that PEGASUS-large currently achieves the highest F1-target score on ECTSum, indicating its superior capability in generating summaries that align with the source material. The F1-target metric focuses on precision and recall of target-specific factual claims, providing a quantitative assessment of hallucination reduction. Consistent, rigorous evaluation using such metrics is crucial for developing trustworthy summarization models in the financial domain, where the accurate conveyance of information is paramount.
The Promise and Peril of Automated Insight
The accelerating volume of financial data, particularly from earnings calls and corporate reports, often overwhelms investors and analysts seeking critical insights. Automated text summarization offers a powerful solution by efficiently distilling lengthy transcripts and documents into concise, informative summaries. This technology doesn’t merely shorten texts; it identifies and highlights key performance indicators, strategic shifts, and risk factors, enabling quicker, more informed investment decisions. By rapidly processing and synthesizing information, automated summarization promises to level the playing field, allowing both institutional and individual investors to react swiftly to market-moving events and potentially improve portfolio performance. The capacity to efficiently extract salient points from complex financial narratives represents a significant advancement in financial analytics and decision support systems.
The automation of financial document summarization offers substantial benefits to regulatory reporting and compliance. Currently, these processes are often labor-intensive, requiring significant time and resources to manually sift through lengthy financial disclosures. Enhanced summarization technologies can dramatically reduce these costs by automatically extracting and organizing key data points required for compliance filings. This not only accelerates reporting timelines but also minimizes the potential for human error, improving the overall accuracy and reliability of submitted information. Furthermore, the increased transparency resulting from readily accessible, concise summaries can facilitate more effective oversight by regulatory bodies, fostering a more stable and trustworthy financial ecosystem.
Advancing financial text summarization necessitates a shift towards models exhibiting heightened robustness and factual accuracy. Current systems often struggle with nuanced language and the potential for misinterpreting critical financial data, demanding research into techniques that verify information against source documents and minimize the generation of unsupported claims. Furthermore, integrating domain-specific knowledge – encompassing accounting principles, economic indicators, and industry jargon – promises to significantly improve the relevance and utility of summaries. Exploration into reasoning capabilities, allowing models to not merely extract information but also infer relationships and draw conclusions, represents a crucial next step in creating summarization tools that truly augment-rather than simply replicate-human financial analysis.
The pursuit of automated financial summarization, as detailed in this work, inevitably invites a certain pragmatism. It’s tempting to champion the elegance of abstractive models, their capacity to reimagine information. However, the emphasis on factual consistency, particularly when dealing with earnings calls, suggests a healthy skepticism. Grace Hopper famously said, “It’s easier to ask forgiveness than it is to get permission.” This sentiment rings true; chasing perfect abstraction risks introducing inaccuracies that require painstaking correction. Better a concise, reliably extractive summary, even if less artful, than a beautifully worded fabrication. The logs, as always, will tell the tale of which approach survives contact with production data.
The Road Ahead
The pursuit of automated financial summarization, as demonstrated by this work, inevitably bumps against the limitations of current transformer architectures. Longformer offers a temporary reprieve from context-length constraints, but the underlying problem persists: scaling model size does not equate to scaling understanding. The insistence on factual consistency, while laudable, merely highlights how easily these systems can fabricate plausible-sounding, yet entirely spurious, details. It’s a familiar pattern; elegant diagrams promising ‘knowledge graphs’ eventually devolve into tangled webs of assertions with questionable provenance.
Future efforts will likely focus on incorporating external knowledge sources – a tactic employed, with varying degrees of success, since the dawn of knowledge-based systems. The real challenge, however, isn’t adding more data, but discerning signal from noise. The current obsession with ‘abstractive’ summarization seems particularly prone to this; the ability to rephrase text is often mistaken for genuine comprehension. The benchmarks will, predictably, improve, but the gap between reported metrics and real-world utility will likely widen.
One anticipates a renewed interest in hybrid approaches, not necessarily combining extractive and abstractive techniques, but integrating symbolic reasoning with neural networks. If all tests pass, it’s because they test nothing of practical consequence. The true test will come when these systems are deployed in production, forced to grapple with the messy, ambiguous, and often deliberately misleading nature of financial reporting. The elegance of the theory will, as always, be the first casualty.
Original article: https://arxiv.org/pdf/2601.09729.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Games That Faced Bans in Countries Over Political Themes
- Gold Rate Forecast
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- The Best Directors of 2025
2026-01-17 06:09