Author: Denis Avetisyan
New research challenges large language models to move beyond following instructions and demonstrate genuine data exploration skills.
This paper introduces DDR-Bench, a novel benchmark for evaluating the investigatory intelligence of agentic language models through open-ended data research.
While large language models excel at answering defined queries, truly intelligent agency requires autonomous exploration and insight generation. This need is addressed in ‘Hunt Instead of Wait: Evaluating Deep Data Research on Large Language Models’, which introduces Deep Data Research (DDR) – a framework and benchmark, DDR-Bench, designed to assess an LLM’s ability to independently extract key insights from databases. Results demonstrate that while frontier models exhibit emerging agency, sustained, long-horizon exploration remains a significant challenge. Can we develop agentic strategies that move beyond mere scaling to unlock the full potential of investigatory intelligence in large language models?
The Erosion of Execution: Beyond Task Completion
Large language models currently demonstrate remarkable executional intelligence, effortlessly completing tasks when provided with clear instructions and defined parameters. However, this proficiency sharply contrasts with their limited capacity for independent thought and open-ended discovery. While adept at following directives – summarizing text, translating languages, or generating code – these models falter when faced with ambiguity or the need to formulate their own research questions. The core limitation isn’t a lack of processing power, but rather an inability to move beyond task completion towards genuine insight generation; they excel at what is asked, but struggle with determining what should be asked, hindering their potential as true investigative tools.
Current large language models, while proficient at performing tasks they are explicitly instructed to do, often falter when confronted with the need for independent inquiry. The crucial missing component is the capacity to formulate relevant questions and proactively seek out information – a skill fundamental to genuine discovery. Without this ability to autonomously define investigative pathways, these models remain largely confined to processing existing data rather than expanding the boundaries of knowledge. This limitation prevents them from identifying novel connections, challenging assumptions, or pursuing unexpected lines of reasoning – essentially restricting their potential beyond mere task completion and towards true intellectual exploration.
The limitations of large language models in autonomously formulating research questions and pursuing independent data investigation highlight a critical need for novel evaluation metrics and research approaches. Current benchmarks primarily assess performance on pre-defined tasks, failing to capture the crucial ability to identify knowledge gaps and proactively seek relevant information. Addressing this necessitates the development of methodologies that move beyond simply measuring task completion to evaluating the quality of inquiry – the relevance of questions asked, the efficiency of data sources explored, and the novelty of insights generated. Consequently, researchers are actively exploring benchmarks that reward LLMs not just for answering questions, but for intelligently deciding what questions deserve answering, paving the way for truly exploratory artificial intelligence.

Charting the Course: DDR-Bench and the Pursuit of Deep Data Research
DDR-Bench represents a shift in LLM evaluation from traditional task completion – such as question answering or text summarization – to assessing capabilities in deep data research. This involves not simply retrieving information, but autonomously formulating research questions, designing investigative procedures, and ultimately generating novel insights from complex datasets. The benchmark prioritizes the LLM’s ability to independently identify potentially meaningful patterns and relationships within data, rather than responding to externally defined prompts. This approach aims to measure an LLM’s capacity for genuine discovery, mirroring the iterative process of a human data scientist exploring a new information space and building a coherent narrative from unstructured data.
DDR-Bench utilizes a multi-dataset approach to evaluate LLMs against the complexities of real-world data research. The benchmark incorporates MIMIC-IV, a large, publicly available database comprising de-identified health data from intensive care units; the 10-K Database, consisting of annual reports filed with the U.S. Securities and Exchange Commission, providing financial and business information; and GLOBEM, a database of macroeconomic data from numerous countries. These datasets were selected to present varied data types, scales, and inherent noise levels, forcing LLMs to handle the challenges of data heterogeneity, missing values, and complex relationships commonly encountered in authentic research scenarios. The datasets collectively represent a broad spectrum of domains – healthcare, finance, and economics – increasing the generalizability requirements for successful LLM performance.
DDR-Bench distinguishes itself from conventional LLM benchmarks by eschewing pre-defined queries or prompts. Instead, LLMs operating within the DDR-Bench framework are required to independently identify research avenues within the provided datasets – MIMIC-IV, the 10-K Database, and GLOBEM – and articulate a rationale for their chosen investigative paths. This necessitates not only data retrieval and analysis capabilities, but also the ability to synthesize hypotheses and present a coherent justification for the selected research direction, effectively simulating the initial stages of an autonomous data research project. Performance is therefore evaluated on the quality of the research question formulated and the logical support provided for its pursuit, rather than simply answering a given prompt.
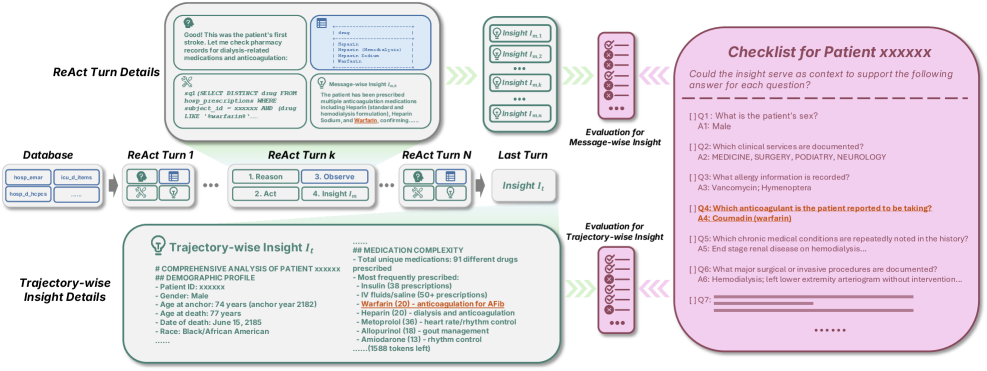
Validating the Trajectory: Rigorous Evaluation of Insight
Checklist-Based Evaluation within DDR-Bench utilizes a predefined set of criteria to systematically assess the factual accuracy and completeness of generated insights. This method involves constructing a checklist of essential elements or facts that should be present in a correct response. The LLM’s output is then evaluated against this checklist, with each item marked as present or absent. Scoring is typically based on the percentage of checklist items fulfilled, providing a quantifiable measure of accuracy and completeness. This approach allows for a granular assessment, identifying specific areas where the LLM’s response is deficient and facilitating targeted improvements to the data exploration process.
Trajectory Analysis in DDR-Bench involves a detailed examination of the sequence of actions an LLM undertakes during data exploration to derive insights. This analysis doesn’t focus solely on the final output, but rather on the process the LLM used – the specific data sources accessed, the queries formulated, and the intermediate steps taken. By logging and reviewing this action sequence, researchers can identify potential biases, inefficiencies, or flawed reasoning patterns within the LLM’s approach. The resulting trajectory provides a granular record of the LLM’s decision-making process, allowing for a more nuanced understanding of how insights are generated and facilitating targeted improvements to the exploration strategy.
The DDR-Bench validation process incorporates both LLM-as-a-Checker and Hallucination Detection to rigorously evaluate generated insights. LLM-as-a-Checker utilizes a separate language model to independently verify the factual correctness of claims made by the primary LLM, providing an external assessment. Complementing this, Hallucination Detection specifically identifies instances where the LLM presents information not supported by the underlying data sources. These techniques are crucial for quantifying the reliability of insights and mitigating the risk of generating inaccurate or fabricated content, ultimately ensuring the trustworthiness of the data exploration process.
The ReAct (Reason + Act) agent framework structures LLM-driven data exploration by iteratively interleaving reasoning steps with action steps. This approach contrasts with traditional methods where the LLM first plans a complete sequence of actions before execution. In ReAct, the LLM generates a thought explaining its reasoning, followed by an action it will take, and then observes the outcome of that action before proceeding. This cycle of thought-action-observation allows the agent to dynamically adjust its plan based on new information, leading to more robust and verifiable exploration. The explicit separation of reasoning and action steps also facilitates tracing the LLM’s decision-making process, improving transparency and enabling easier identification of potential errors or biases.

The Emergence of Agency: Towards Autonomous Scientific Partners
The emergence of benchmarks like DDR-Bench signals a pivotal evolution in large language models, moving beyond their traditional role as task executors to become genuinely agentic researchers. These new methodologies aren’t simply assessing a model’s ability to complete a given instruction, but rather its capacity to independently formulate research questions, explore information landscapes, and synthesize findings – effectively mimicking the scientific process. This shift necessitates evaluation frameworks that measure not just accuracy on pre-defined tasks, but also the quality and density of information gathered during extended, unguided exploration. DDR-Bench, therefore, represents a crucial step towards building AI systems capable of autonomous discovery, potentially accelerating innovation across diverse fields by leveraging the power of LLMs to independently investigate complex problems.
The emergence of agentic large language models hinges critically on a capacity known as Long-Horizon Interaction – the ability to maintain coherent reasoning and purposeful exploration across extended sequences of actions and information gathering. Unlike traditional models designed for single-turn responses, these advanced systems must effectively manage a ‘cognitive horizon,’ retaining context and refining goals over many steps to address complex challenges. This sustained interaction isn’t simply about processing more data; it demands robust internal mechanisms for self-assessment, error correction, and knowledge integration. The ability to navigate this long horizon allows the model to not only formulate initial hypotheses but also to iteratively refine them through continuous investigation, much like a human researcher pursuing a complex problem. Consequently, Long-Horizon Interaction is becoming a key benchmark for evaluating the potential of LLMs to function as truly autonomous agents in fields requiring deep, sustained inquiry.
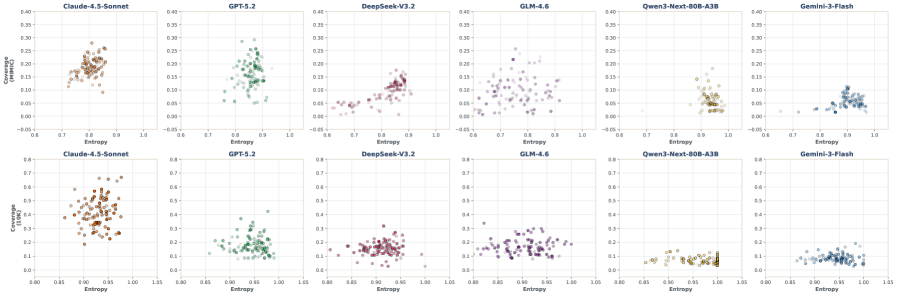
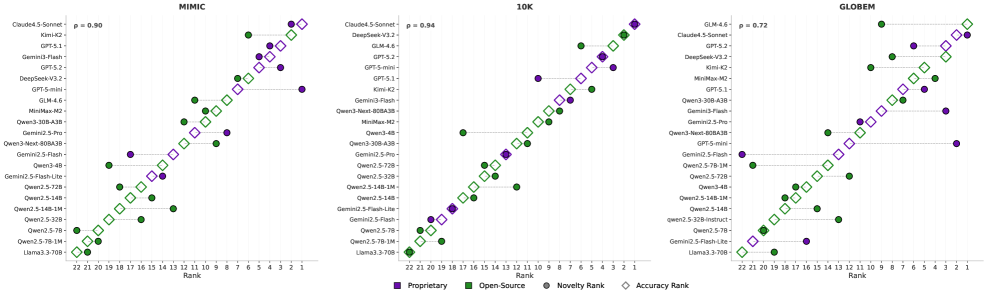
Recent evaluations utilizing the DDR-Bench-a demanding benchmark for autonomous research-reveal significant advancements in large language model capabilities, notably demonstrated by Claude 4.5 Sonnet. This model achieved up to 40% accuracy in completing complex research tasks, substantially exceeding the performance of other tested models. This result isn’t merely a numerical improvement; it signals a shift towards models capable of sustained, independent investigation, moving beyond simple task completion to genuine exploratory intelligence.
Recent evaluations reveal that leading large language models-including Claude, DeepSeek, and GLM-exhibit a remarkable capacity for sustained, insightful exploration during autonomous research. These models aren’t simply processing information; they consistently generate a high ratio of valid insights throughout extended investigative processes. This suggests these LLMs effectively condense and retain relevant knowledge, demonstrating a high degree of information density as they navigate complex tasks. Unlike models prone to quickly diverging into irrelevant tangents, these stronger performers maintain a focus on meaningful discovery, consistently producing useful and verifiable findings even as exploration extends over numerous steps. This sustained validity is a key indicator of their potential as truly agentic systems capable of independent research and problem-solving.
Recent investigations into agentic Large Language Models (LLMs) reveal a surprising resilience to inaccuracies; the rate at which these models generate factually incorrect statements, or “hallucinations,” demonstrated a remarkably weak correlation with overall performance on complex research tasks. Analysis of 10,000 trials yielded a correlation coefficient of just 0.125, accompanied by a statistically insignificant p-value of 0.8779, suggesting that even with a degree of fabricated information, the models can still effectively navigate investigatory processes. This finding challenges conventional assumptions about the necessity of absolute factual correctness for achieving high-level reasoning and problem-solving, and implies that the process of exploration and insight generation may be more critical than the complete absence of error in the context of autonomous research.
A crucial component of evaluating agentic LLMs lies in robust assessment methodologies, and recent work has established the “LLM-as-a-Checker” as a remarkably stable and reliable option. This evaluation technique consistently produced results with a low coefficient of variation – remaining under 5% across a diverse range of scenarios. Such consistency suggests the method offers a dependable metric for gauging an LLM’s investigatory capabilities, minimizing the influence of random variation and providing confidence in performance comparisons. The demonstrated stability is particularly important as these models transition toward autonomous research, where objective and repeatable evaluation becomes paramount for tracking progress and ensuring trustworthiness.
The advancement of investigatory intelligence within large language models promises transformative applications across diverse fields. In scientific discovery, these models can autonomously formulate hypotheses, design experiments, and analyze data, accelerating the pace of research and potentially uncovering novel insights. Financial analysis stands to benefit from LLMs capable of sifting through vast datasets, identifying market trends, and assessing risk with greater efficiency. Perhaps most profoundly, personalized medicine could be revolutionized by AI agents that synthesize patient data, medical literature, and genomic information to tailor treatments and predict health outcomes with unprecedented accuracy. This capability extends beyond mere data processing; it represents a shift toward AI systems capable of independent inquiry and knowledge generation, ultimately augmenting human expertise and driving innovation across critical sectors.
Ongoing research prioritizes bolstering the reliability and adaptability of these investigatory methods, aiming to move beyond benchmark performance towards genuinely autonomous AI researchers. Current efforts center on developing techniques that allow these models to consistently produce valid insights across diverse and unpredictable scenarios, reducing dependence on curated datasets and specific task formulations. This includes exploring methods for self-correction, knowledge integration from varied sources, and the capacity to identify and mitigate inherent biases. Successfully achieving this level of robustness and generalizability will not only refine the ability of LLMs to conduct research but also unlock their potential to contribute meaningfully to complex problem-solving across disciplines, effectively functioning as collaborative scientific partners.
The pursuit of investigatory intelligence, as detailed in this study with DDR-Bench, echoes a fundamental truth about all complex systems: improvement is fleeting. G.H. Hardy observed, “The essence of mathematics lies in its elegance and its inherent tendency towards simplification.” This applies equally to data science; a model achieving peak performance on a benchmark rapidly faces diminishing returns as data evolves and complexities mount. The benchmark isn’t a destination, but a snapshot-a temporary elegance before decay sets in. The work highlights that agentic LLMs must not merely execute tasks but hunt for knowledge, acknowledging that any initial insight ages faster than expected, necessitating continuous exploration and adaptation-a journey back along the arrow of time, as it were.
The Long View
The introduction of DDR-Bench represents a subtle but significant shift in how large language models are assessed. The field has largely focused on measuring performance against known quantities-on confirming expected answers. This work, however, begins to probe a more elusive quality: the capacity for genuinely open-ended exploration. It acknowledges that systems, even those built on static datasets, learn to age gracefully by navigating the unexpected. The true measure isn’t speed, but the elegance with which a system encounters the inevitable noise inherent in any investigatory process.
Unresolved remains the question of defining ‘insight’ itself. DDR-Bench offers a framework, but the very notion implies a subjective judgment, even within a rigorously defined benchmark. As these models grow in complexity, the challenge won’t be maximizing quantifiable outputs, but discerning meaningful signals from the ever-increasing volume of data they process. Sometimes observing the process-the subtle shifts in investigative strategy-is better than trying to accelerate the arrival at a pre-defined conclusion.
The limitations are, of course, inherent. Any benchmark is a simplification of a far more complex reality. But the value lies not in achieving a perfect score, but in illuminating the boundaries of current capabilities. The long view suggests that the future of agentic LLMs isn’t about conquering data, but about learning to coexist with its inherent ambiguity-to find patterns not by force, but by patient observation.
Original article: https://arxiv.org/pdf/2602.02039.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Gold Rate Forecast
- Silver Rate Forecast
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Building Agents That Learn and Improve Themselves
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 15 Films That Were Shot Entirely on Phones
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Games That Faced Bans in Countries Over Political Themes
- 20 Films Where Black Directors Subverted Hollywood’s White Savior Tropes
2026-02-03 12:30