Author: Denis Avetisyan
A new self-reflection framework helps graph neural networks identify and eliminate misleading correlations, leading to more reliable and consistent explanations.
This work introduces a method for refining edge importance masks in graph neural networks to mitigate spurious correlations and improve explanation consistency without retraining the model.
Despite advances in interpretable graph learning, reliably discerning truly salient graph structures remains challenging, particularly when spurious correlations obscure meaningful patterns. This work, ‘Combating Spurious Correlations in Graph Interpretability via Self-Reflection’, addresses this limitation by introducing a novel self-reflection framework inspired by techniques used in large language models. Our approach iteratively refines edge importance masks, effectively mitigating the influence of misleading correlations and enhancing the consistency of graph explanations without requiring additional training. Could this self-reflective paradigm unlock more robust and trustworthy graph neural network interpretations across diverse application domains?
Unmasking the Fragility of Graph Intelligence
Despite the demonstrated power of Graph Neural Networks (GNNs) in analyzing interconnected data, their predictive capabilities aren’t always as robust as they appear. Recent research reveals a susceptibility to what’s termed ‘brittleness’ – meaning seemingly accurate predictions can be easily disrupted by minor, often imperceptible, changes in the input graph. This fragility stems from the models’ tendency to latch onto spurious correlations – patterns in the training data that coincidentally appear predictive but lack genuine causal connection to the outcome. Consequently, a GNN might confidently predict a relationship based on a coincidental feature of the graph’s structure, rather than a meaningful underlying principle, highlighting a critical limitation in their reliability and generalizability.
Graph Neural Networks, despite their predictive power, can suffer from a curious flaw: explanation-level hallucination. This phenomenon occurs when the network’s attempt to justify a prediction focuses on features within the graph that are, in reality, entirely unrelated to the decision-making process. Essentially, the explanation appears plausible, highlighting connections that seem relevant, but is fundamentally misleading. This isn’t merely a cosmetic issue; it directly erodes trust in the model’s reasoning. If a system designed to, for example, identify fraudulent transactions justifies its assessment based on spurious correlations – like highlighting a shared hobby between parties – it renders the prediction unverifiable and unreliable. Consequently, explanation-level hallucination presents a significant obstacle to deploying GNNs in high-stakes domains where transparency and accountability are paramount, demanding research into more faithful and robust interpretability methods.
The opacity of Graph Neural Networks presents a significant obstacle to their implementation in domains demanding accountability, such as healthcare, finance, and criminal justice. Without a clear understanding of why a GNN arrives at a particular prediction, verifying the soundness of its reasoning becomes impossible. This is particularly concerning when decisions impact individuals or require adherence to strict regulatory standards. Consequently, the inability to trace the logic behind GNN outputs erodes confidence and limits their usefulness in applications where transparency and justifiable outcomes are paramount; a model’s predictive power is insufficient without the ability to demonstrate the validity of its conclusions through interpretable evidence.
Dissecting the Black Box: L2X for Transparent Reasoning
The L2X architecture addresses the challenge of interpreting Graph Neural Networks (GNNs) by explicitly separating predictive performance from the identification of influential graph features. Traditional GNNs often conflate these two aspects, making it difficult to determine which edges or nodes genuinely contribute to a model’s decision. L2X achieves disentanglement through a two-stage process: an upstream module assesses the importance of each edge independently of the final prediction task, and a downstream module leverages this importance information to make predictions. This modularity allows for the isolation and analysis of explanatory signals, enabling researchers to understand why a GNN makes a particular prediction, beyond simply observing what it predicts.
The L2X architecture segregates functionality into two sequential modules: an upstream importance evaluator and a downstream prediction module. The upstream module operates on the graph structure to assign an importance score to each edge, quantifying its contribution to the reasoning process. This evaluation is performed independently of the final prediction task. Subsequently, the downstream module receives the graph with edge importances and generates predictions based on this weighted graph structure. This modular design allows for explicit analysis of which edges the model deems critical for its decisions, facilitating interpretability and robustness assessments.
Edge masking within the L2X architecture operates by selectively removing connections from the graph based on importance scores generated by the upstream module. This process compels the downstream prediction module to base its outputs solely on the remaining, highly-ranked edges. By eliminating less influential connections, the model is prevented from utilizing spurious correlations or redundant pathways, thereby isolating the genuinely critical relationships within the graph structure and enhancing the interpretability of its reasoning process. The degree of masking can be controlled, allowing for a trade-off between performance and the stringency of reliance on key connections.
Self-Reflection: Forging Reliable Explanations Through Iteration
The self-reflection mechanism implemented within the explanation generation process involves an iterative refinement loop where the model actively critiques and revises its initial explanations. This is achieved by repeatedly generating explanations, evaluating their internal consistency, and then using that evaluation to refine the explanation generation parameters for subsequent iterations. Each iteration builds upon the previous, allowing the model to progressively improve the quality and reliability of its explanations through self-assessment and correction. This contrasts with single-pass explanation methods and aims to produce more robust and trustworthy results by addressing potential shortcomings identified during the iterative process.
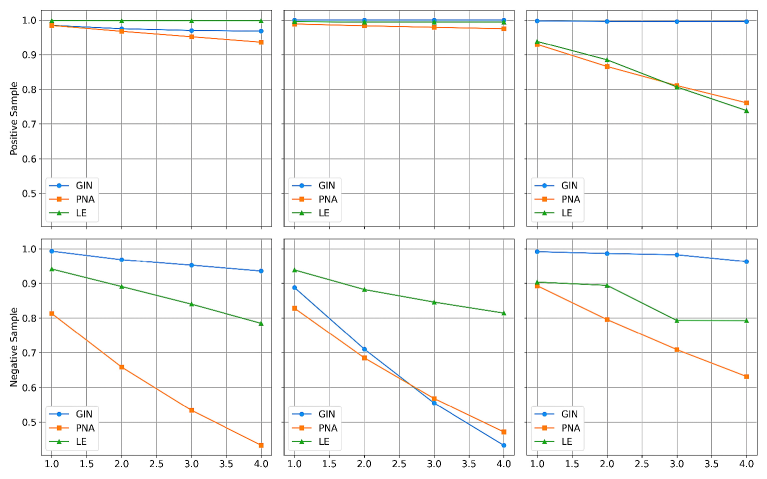
The mask consistency loss functions as a regularization term within the self-reflection mechanism, penalizing significant fluctuations in edge importance scores between iterative refinement steps. Specifically, it calculates the difference between edge masks generated in successive iterations, minimizing this difference to enforce stability. This encourages the model to produce explanations where the identified important edges remain consistent across revisions, leading to more reliable and trustworthy results. By reducing variance in edge importance, the mask consistency loss contributes to the overall robustness of the explanation process and mitigates the risk of spurious or transient edge selections.
The explanation generation process utilizes the Greedy Search Algorithm for Topological ordering (GSAT) to maintain critical information within the graph structure. GSAT operates by iteratively masking edges and then optimizing for maximal ‘mutual information’ between the resulting masked graph and the original, unmasked graph. This optimization process prioritizes the retention of edges that contribute most to the preservation of the original graph’s information content, ensuring that the explanation does not inadvertently remove crucial relationships. By maximizing mutual information, GSAT effectively identifies and preserves the most salient edges for a faithful and informative explanation, mitigating the risk of generating explanations that are disconnected from the underlying model behavior.
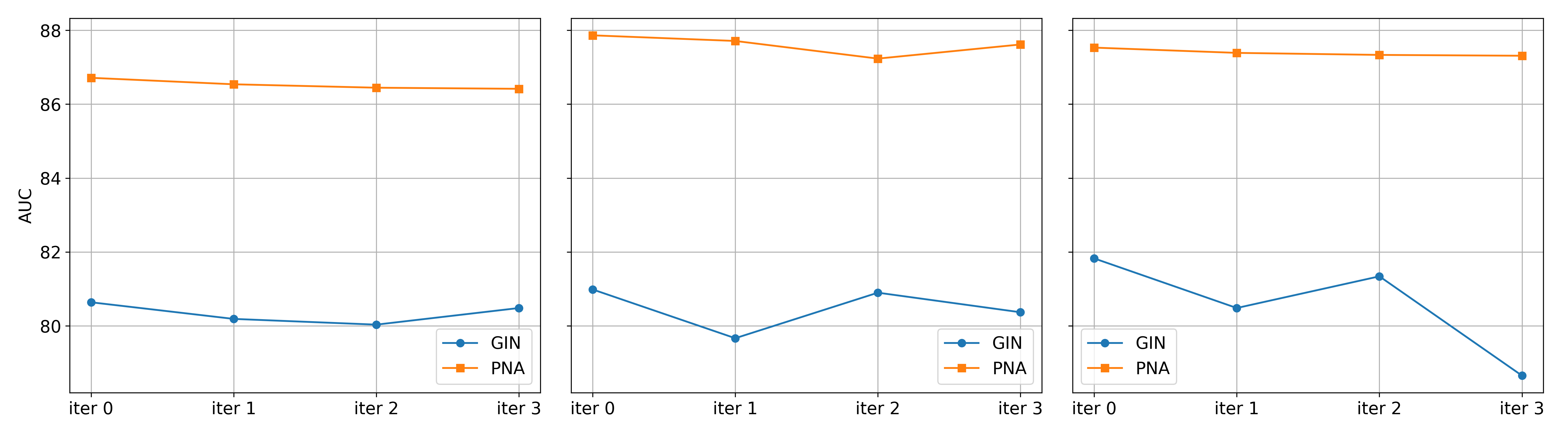
The self-reflection mechanism implemented encourages monotonicity in edge importance scores during explanation generation. This means that as the model iteratively refines its explanations, the assigned importance to each edge tends to consistently increase or decrease, rather than fluctuate. This consistent trend in edge importance provides a measurable signal of stability and reliability; edges consistently ranked as important across multiple self-reflection iterations are more likely to genuinely contribute to the model’s decision, thereby increasing confidence in the fidelity of the generated explanations. A monotonic trend allows for easier interpretation and validation of the explanation process itself.
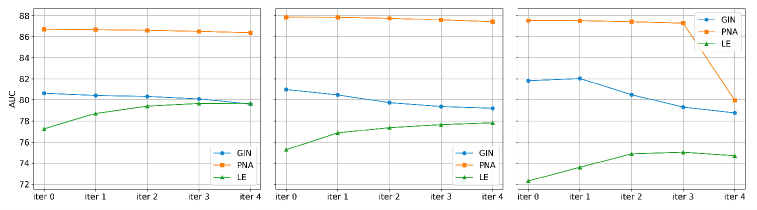
The Spurious-Motif Benchmark: Stress-Testing for Robust Intelligence
The L2X model underwent rigorous testing using the ‘Spurious-Motif Benchmark,’ a carefully constructed synthetic dataset explicitly designed to challenge a model’s susceptibility to spurious correlations-features that appear predictive but are ultimately unrelated to the true underlying relationships. This benchmark presents scenarios where models can easily achieve high accuracy by exploiting these misleading cues, effectively masking a lack of genuine understanding. By evaluating L2X’s performance on this dataset, researchers aimed to isolate its ability to discern meaningful signals from deceptive correlations, pushing beyond simple accuracy metrics to assess the robustness and reliability of its learned representations. The results highlight L2X’s capacity to avoid being misled by these spurious features, indicating a more faithful and generalizable approach to graph-based reasoning.
Evaluations on the ‘Spurious-Motif Benchmark’ reveal that the L2X methodology demonstrably surpasses established Graph Neural Networks – specifically GIN, PNA, and LE – in both identifying and reducing the impact of misleading correlations within data. This enhanced capability stems from L2X’s capacity to discern genuine predictive features from those that merely appear correlated, leading to more robust and reliable model predictions. The performance gains aren’t simply statistical; they translate directly into a model less susceptible to being misled by spurious patterns, and therefore, more likely to generalize effectively to unseen data and real-world scenarios. This represents a significant advancement in building trustworthy graph neural networks, particularly in applications where accurate reasoning, rather than superficial pattern matching, is crucial.
The enhanced performance of L2X extends beyond simple accuracy gains, yielding explanations that more accurately reflect the true drivers of a graph neural network’s predictions. By mitigating the influence of spurious correlations – misleading patterns unrelated to the underlying phenomenon – the model’s reasoning becomes more transparent and understandable for users. This fidelity in explanation is critical; instead of highlighting irrelevant features, L2X focuses attention on the genuinely influential aspects of the graph structure, offering a clearer insight into why a particular prediction was made. Consequently, users can gain increased confidence in the model’s decisions and more effectively leverage its insights, particularly in sensitive applications where interpretability is as important as predictive power.
Evaluations across diverse datasets and graph neural network architectures – including both LE and GIN backbones – reveal a consistent trend of improved predictive accuracy with the implemented approach. Notably, analysis of the MolHIV dataset demonstrated a substantial reduction in the discrepancy between training and testing performance. This narrowed gap suggests a diminished reliance on spurious correlations during model learning, indicating the system generalizes more effectively to unseen data. By mitigating overfitting to misleading patterns, the approach not only enhances the reliability of predictions but also fosters a more robust and trustworthy model capable of sound reasoning beyond the training set.
The enhanced interpretability offered by this approach is not merely an academic benefit, but a fundamental requirement for the successful integration of Graph Neural Networks (GNNs) into critical real-world applications. As GNNs increasingly influence decisions in fields like drug discovery, financial modeling, and social network analysis, understanding why a model arrives at a specific conclusion becomes as important as the prediction itself. This transparency fosters trust among stakeholders, allowing for validation of the model’s reasoning and identification of potential biases or errors. Furthermore, in contexts demanding accountability – such as medical diagnoses or loan approvals – the ability to clearly articulate the basis for a decision is often legally or ethically mandated. Consequently, a GNN capable of providing faithful explanations isn’t simply more informative; it’s essential for responsible deployment and building confidence in these powerful systems.
The pursuit of interpretable graph learning, as detailed in this work, inherently demands a willingness to challenge established methods. This paper doesn’t simply accept the initial outputs of graph neural networks; instead, it actively probes for weaknesses – spurious correlations – through iterative refinement of edge masks. It’s a process of controlled dismantling, much like reverse-engineering a complex system to truly understand its functionality. As Vinton Cerf aptly stated, “Any sufficiently advanced technology is indistinguishable from magic.” This research strips away the ‘magic’ of black-box models by revealing the underlying mechanisms, forcing a reckoning with potentially misleading correlations and bolstering explanation consistency – a direct application of testing the boundaries of what is accepted as truth.
Beyond the Surface: Where Next for Graph Interpretability?
The presented self-reflection framework offers a compelling demonstration: one can probe for, and diminish, spurious correlations in graph neural networks without the usual computational expense of retraining. Yet, the very act of iteratively refining importance masks begs a fundamental question. Are these refinements genuinely uncovering ‘true’ relationships, or simply exchanging one set of convenient fictions for another? The system declares improvement based on consistency, but consistency is merely a pattern – a rule – and rules, as anyone familiar with reverse-engineering knows, are made to be broken.
Future work must move beyond assessing explanation consistency in isolation. A truly robust evaluation demands the deliberate introduction of known confounders – actively trying to fool the network and its interpretability method. The current paradigm often assumes a ‘good’ graph; what happens when the underlying structure itself is deliberately misleading, or contains hidden adversarial elements? Testing the limits of self-reflection, pushing it to fail spectacularly, will reveal the true depth of understanding-or lack thereof-within these systems.
Ultimately, the goal isn’t simply to produce explanations that appear consistent, but to build networks that are inherently less susceptible to spurious correlations in the first place. Perhaps the most fruitful avenue lies not in post-hoc interpretability, but in designing learning algorithms that prioritize causal reasoning from the outset. If one cannot dismantle the mechanism, one hasn’t truly understood it.
Original article: https://arxiv.org/pdf/2601.11021.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- The Best Directors of 2025
2026-01-19 12:07