Author: Denis Avetisyan
A new approach to analyzing text related to the UN’s Sustainable Development Goals leverages the power of combined machine learning models to achieve greater accuracy.
![The study acknowledges the United Nations’ Sustainable Development Goals [25] as a globally recognized framework for addressing interconnected challenges, yet implicitly recognizes that even these ambitious targets will inevitably encounter practical limitations and unforeseen consequences in real-world implementation.](https://arxiv.org/html/2602.11168v1/pics/UN_SDG.png)
Combinatorial Fusion Analysis and generative AI enhance SDG text classification, outperforming individual models and aligning with human expert assessments.
Accurate categorization of textual data remains a challenge, particularly when dealing with nuanced or interrelated categories. This is addressed in ‘Enhancing SDG-Text Classification with Combinatorial Fusion Analysis and Generative AI’, which proposes a novel approach to classifying text according to the UN’s Sustainable Development Goals. By fusing intelligence from multiple machine learning models using Combinatorial Fusion Analysis (CFA) and augmenting training data with generative AI, the authors demonstrate a significant performance improvement-reaching 96.73% accuracy and aligning with human expert classifications. Could this synergistic combination of model fusion and human insight unlock new levels of accuracy and understanding in complex social analyses?
The Illusion of Order: Categorizing Global Goals From a Data Flood
Accurate tracking of the Sustainable Development Goals (SDGs) relies heavily on the ability to systematically categorize the vast amounts of textual data generated by reports, news articles, social media, and academic research. This categorization process isn’t simply about assigning keywords; it demands a nuanced understanding of context to determine how specific text relates to the complex targets and indicators defined within each of the 17 SDGs. Without effective categorization, identifying trends, measuring progress, and allocating resources becomes significantly more difficult, hindering efforts to address global challenges like poverty, climate change, and inequality. The ability to reliably connect text to these globally recognized goals is therefore paramount, serving as the foundation for data-driven decision-making and accountability in sustainable development initiatives.
Existing text categorization techniques often falter when applied to the intricate language used in real-world documentation. These methods, frequently reliant on keyword matching or simplistic rule-based systems, struggle to grasp contextual subtleties, figurative language, and the multifaceted meanings embedded within text. Consequently, accurately connecting documents to the Sustainable Development Goals – which require understanding complex themes like poverty eradication, climate action, or quality education – proves challenging. A report discussing ‘food security’ might, for example, also address issues of economic inequality or environmental sustainability, connections a traditional system could easily miss. This limitation hinders efforts to reliably monitor progress toward these global objectives, as relevant information remains obscured by the inability of current tools to decipher the full scope of textual content.
The escalating production of digital text – from news articles and social media posts to scientific reports and policy documents – presents a formidable challenge to efforts seeking to track global progress. While automated text analysis offers the only viable path to processing this immense volume of data, achieving sufficient precision remains a critical obstacle. Current algorithms often struggle with the subtleties of language – including ambiguity, context, and evolving terminology – leading to miscategorization and potentially skewed insights. Consequently, researchers are actively pursuing innovative approaches, such as advanced machine learning models and knowledge graphs, to enhance the accuracy of automated systems without sacrificing the speed necessary for continuous monitoring and timely intervention. This pursuit aims to bridge the gap between data abundance and meaningful, reliable information for sustainable development initiatives.
Although meticulously detailed, human assessment of textual data for relevance to complex global initiatives proves increasingly unsustainable as data volumes escalate. While manual curation delivers high precision in identifying nuanced connections – ensuring, for example, a report truly addresses a specific target within the Sustainable Development Goals – the time and resource demands quickly become prohibitive. The continuous flow of new information – reports, articles, social media posts – necessitates a scalable approach beyond human capacity. Consequently, relying solely on manual methods hinders timely monitoring of progress and limits the ability to respond effectively to emerging trends or critical gaps in achieving stated objectives. This presents a fundamental challenge: how to maintain analytical rigor while processing data at the speed and scale required for impactful, ongoing assessment.
The Algorithmic Toolbox: A Survey of Classification Methods
Automated text classification leverages several machine learning techniques to categorize documents. BERT (Bidirectional Encoder Representations from Transformers) utilizes a transformer-based architecture for contextual understanding of text, excelling in tasks requiring nuanced semantic analysis. Convolutional Neural Networks (CNNs), commonly used in image processing, can also be applied to text by treating words as elements in a sequence, identifying patterns through convolutional filters. Random Forest, an ensemble learning method, constructs multiple decision trees to improve prediction accuracy and handle high-dimensional data. SDG Classy is a specialized system designed for classifying text related to the Sustainable Development Goals (SDGs), employing a hierarchical label system and trained on a corpus of SDG-relevant documents. Each method offers distinct advantages depending on the dataset characteristics and classification requirements.
Topic modeling techniques, such as Latent Dirichlet Allocation (LDA), identify abstract “topics” within a collection of documents, enabling a more nuanced understanding of content beyond simple keyword matching. Large Language Models (LLMs), exemplified by ChatGPT, extend this capability through contextual understanding and the generation of synthetic data. Specifically, LLMs can create additional training examples, augment existing datasets, or simulate diverse perspectives, thereby improving the performance and robustness of classification models, particularly when labelled data is scarce. This synthetic data generation addresses a critical limitation in applying machine learning to specialized domains where obtaining sufficient labelled data is costly or time-consuming.
Current automated text classification methods frequently function as discrete units, analyzing documents for individual labels or topics without considering relationships between them. This isolated approach can lead to incomplete or inaccurate assessments, particularly within complex documents addressing multifaceted issues. For example, a document discussing sustainable agriculture might be categorized solely under “agriculture” while overlooking its inherent connections to “climate action” and “food security”. The lack of integrated analysis prevents the identification of these cross-cutting themes, hindering a holistic understanding of the document’s content and potentially misrepresenting its true scope.
Multi-label classification addresses the inherent interconnectedness of the Sustainable Development Goals (SDGs) by allowing each document or data point to be assigned multiple relevant SDG classifications, rather than being restricted to a single label. This contrasts with single-label classification, which can oversimplify complex issues that often relate to several goals simultaneously. However, successful implementation of multi-label classification necessitates robust data integration strategies; models require appropriately labeled training data reflecting these interdependencies and careful evaluation metrics beyond simple accuracy, such as precision, recall, and F1-score for each label, to avoid biases and ensure meaningful results. Furthermore, the computational complexity and model interpretability increase with multi-label approaches, demanding careful consideration of algorithm selection and feature engineering.
Beyond Silos: Fusing Models for Robust Classification
Model fusion is a technique employed to enhance classification performance and system reliability by integrating the predictive capabilities of multiple individual models. Rather than relying on a single model’s assessment, fusion methods combine outputs, capitalizing on the diversity of algorithms and their respective strengths. This approach mitigates the risk of relying on a model susceptible to specific data biases or limitations, leading to improved generalization and more robust predictions across varied datasets. By aggregating insights from multiple sources, model fusion frequently achieves higher accuracy and stability than any single constituent model operating in isolation.
Combinatorial Fusion Analysis (CFA) operates on the principle that maximizing performance in model fusion requires not simply aggregating predictions, but prioritizing the integration of diverse scoring systems. This approach, distinct from methods that favor consensus, actively seeks models exhibiting cognitive diversity – measurable dissimilarity in how they assess data. The rationale is that models which independently make different errors, due to variations in their underlying logic or training data, contribute complementary information when combined. CFA evaluates and weights these models based on the extent of their dissimilarity, aiming to exploit non-redundant predictive power and ultimately improve the robustness and accuracy of the fused system compared to approaches that prioritize model agreement.
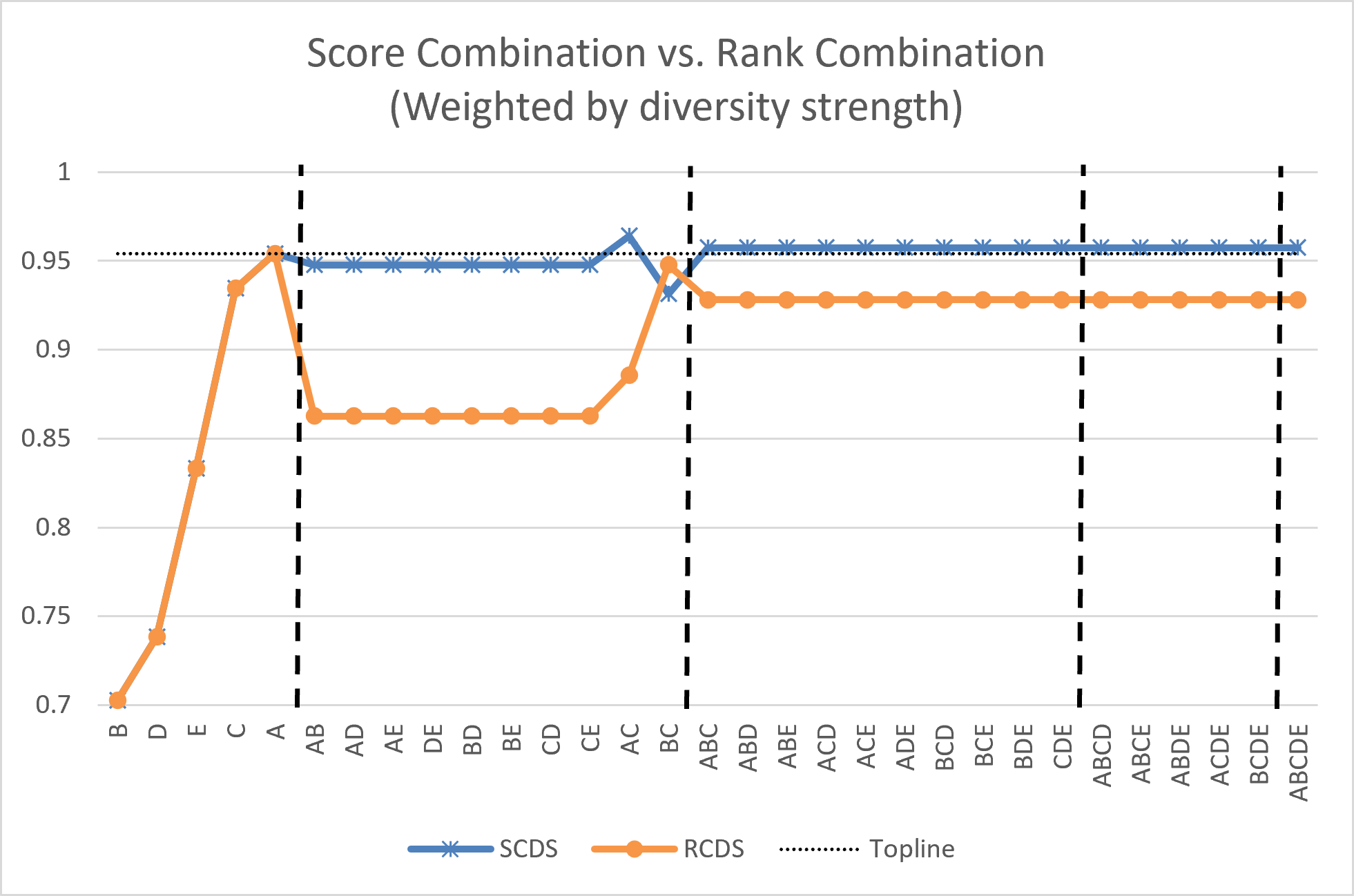
The Rank-Score Function is a core element of our combinatorial fusion analysis, providing a detailed representation of each base model’s scoring tendencies. Unlike simple averaging or majority voting, this function captures not only the magnitude of a model’s score but also its relative ranking of different potential classifications. Specifically, the function generates a vector for each model, where each element corresponds to a specific SDG and its value reflects the model’s predicted probability or confidence score. This allows for a precise comparison of scoring behaviors, identifying instances where models strongly agree or disagree, and quantifying the cognitive diversity that drives improved performance when these models are combined. The function’s output is used to weight the contributions of each model during the fusion process, prioritizing those that demonstrate consistent and accurate scoring patterns.
The integration of diverse models – specifically SDG Classy, LinkedSDG, SDG Mapper, Convolutional Neural Network, and Random Forest – yields improved performance in SDG classification tasks. Our methodology demonstrates an average precision of 0.9673, representing a quantifiable improvement over both a fine-tuned BERT model, which achieved 0.9446 precision, and the individual base models used in the fusion process. This performance gain is achieved by leveraging the complementary strengths of each model, enabling a more robust and accurate classification outcome than any single model could achieve independently.
Comparative analysis demonstrates that the proposed model fusion approach surpasses the performance of a fine-tuned BERT model, achieving a precision of 0.9673 compared to BERT’s 0.9446. Furthermore, a substantial majority – 62.89% – of the combined models generated exhibited superior performance to individual base models within at least one Sustainable Development Goal (SDG) group, indicating a consistent benefit from the ensemble strategy across different classification tasks.
The Illusion of Completion: Synthetic Data and the Future of SDG Tracking
A significant challenge in accurately classifying text related to the Sustainable Development Goals (SDGs) lies in the limited availability of labeled data for many specific targets. Recent advancements utilize Large Language Models, such as ChatGPT, to generate synthetic data – realistic text examples crafted to augment existing datasets. This artificially expanded training material effectively addresses data scarcity, particularly for under-represented SDG categories. By exposing models to a broader range of examples, including nuanced and diverse phrasing, synthetic data fosters improved generalization capabilities. The result is a system less susceptible to biases present in limited real-world data and better equipped to accurately classify text even when encountering previously unseen variations in language and context, ultimately boosting the reliability of SDG progress monitoring.
The integration of synthetically generated data with model fusion strategies represents a substantial advancement in the precision and dependability of Sustainable Development Goal (SDG) classification. By augmenting limited real-world datasets with carefully crafted synthetic examples, researchers effectively broadened the training scope for machine learning models. This expanded dataset, when combined with techniques that intelligently merge the predictions of multiple models, yielded significantly improved results. The resulting system isn’t simply better at categorizing text; it demonstrates a greater capacity to generalize, minimizing errors and offering a more trustworthy assessment of progress towards the globally recognized SDGs. This approach fosters a resilient classification framework, capable of consistently delivering accurate insights even when confronted with diverse and complex textual data.
Statistical analysis reveals a compelling advantage in combining multiple models for Sustainable Development Goal (SDG) classification. Across all seventeen SDGs, 92.19% of the combined models demonstrated superior performance when compared to the average results of individual models operating independently. Furthermore, a substantial 47.12% of these combined systems not only matched but exceeded the precision of the single best-performing individual model. This indicates that the synergistic effect of model fusion unlocks a higher level of accuracy and reliability, suggesting that leveraging the strengths of diverse approaches is crucial for effective SDG monitoring and achieving more nuanced, insightful results from complex text data.
The culmination of this research yields a system uniquely equipped to analyze extensive textual datasets, transforming raw information into pragmatic intelligence for those shaping global policy. By efficiently sifting through large volumes of reports, news articles, and social media feeds, the system identifies key themes and trends relevant to the Sustainable Development Goals. This capability extends beyond mere categorization; it provides nuanced insights into the challenges and opportunities surrounding each goal, enabling policymakers to make data-driven decisions and allocate resources effectively. The system’s adaptability ensures its continued relevance as new data emerges, fostering a proactive and informed approach to achieving a sustainable future and allowing for timely interventions where progress lags.
The innovative system transcends traditional static categorization of Sustainable Development Goal (SDG) data, offering instead a continuously evolving framework for tracking global progress. Rather than simply assigning text to predefined SDG labels, the approach fosters adaptability by leveraging synthetic data and model fusion, allowing the system to refine its understanding as new information emerges. This dynamic capability is crucial for accurately reflecting the complex, interconnected nature of sustainability challenges and responding to shifting priorities; it moves beyond a snapshot assessment to provide ongoing, nuanced insights for policymakers. Consequently, the system doesn’t just classify data, but actively learns from it, ensuring a more responsive and insightful tool for driving impactful change towards a sustainable future.
The pursuit of perfect classification, as demonstrated by this work on SDG-text, inevitably invites eventual compromise. The paper details a complex choreography of model fusion-Combinatorial Fusion Analysis striving for ever-higher accuracy-but one suspects even the most elegant architecture will eventually stumble on a novel edge case. As Ken Thompson observed, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not going to be able to debug it.” This sentiment rings true; the system, while showing impressive gains over single models, is still built on shifting sands of data and algorithms, and will, ultimately, face the relentless pressure of real-world text. The improvements are valuable, of course, but the underlying truth remains: every abstraction dies in production.
What’s Next?
The pursuit of automated Sustainable Development Goal (SDG) text classification, as demonstrated by this work, inevitably introduces a new class of failure modes. While combinatorial fusion and generative augmentation offer marginal gains in accuracy, they merely shift the error distribution – the system will confidently misclassify things in novel and interesting ways. The illusion of progress is strong, but production data, relentlessly pragmatic, will expose the brittle core of any ‘robust’ framework. One anticipates a future dominated by edge-case debugging and the perpetual refinement of loss functions, all in service of a classification scheme designed by humans, for humans, and ultimately understood by neither.
The reliance on synthetic data, while expedient, feels particularly precarious. Each generated example is a testament to the model’s inherent biases, amplified and recirculated as ‘ground truth’. The system doesn’t learn to understand the SDGs; it learns to recognize patterns within its own fabricated reality. This creates a feedback loop of self-deception, masked by impressive metrics. It’s a beautiful, self-contained system – until it encounters data that refuses to conform.
Future work will undoubtedly focus on ‘explainable AI’, a field dedicated to post-hoc rationalization of decisions made by opaque systems. This is akin to performing an autopsy to understand why a machine decided something – a compelling exercise in futility. The underlying truth remains: anything that promises to simplify life adds another layer of abstraction, and each layer increases the surface area for things to break. CI is its temple – one prays nothing breaks.
Original article: https://arxiv.org/pdf/2602.11168.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Silver Rate Forecast
- Spotting the Loops in Autonomous Systems
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
2026-02-13 20:01