Author: Denis Avetisyan
A new framework intelligently selects and incorporates relevant evidence to improve the accuracy of multimodal fake news detection.
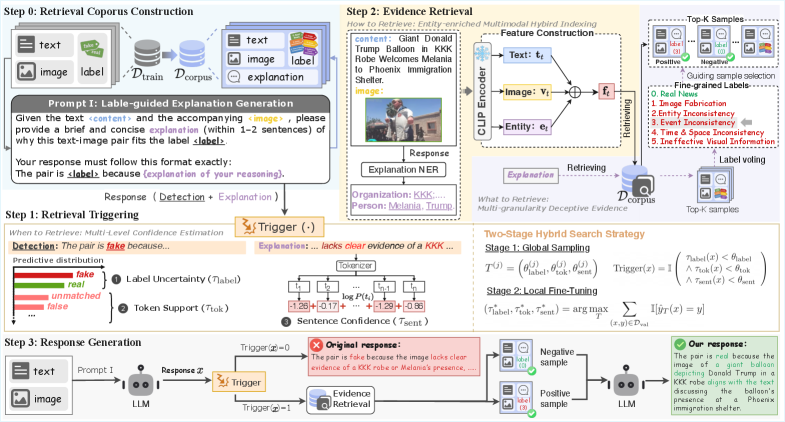
ExDR leverages explanation-driven dynamic retrieval to enhance performance and efficiency using large vision-language models.
The increasing sophistication of multimodal fake news presents a significant challenge to existing detection methods, often hampered by redundant information and irrelevant evidence. To address this, we introduce ‘ExDR: Explanation-driven Dynamic Retrieval Enhancement for Multimodal Fake News Detection’, a novel framework that intelligently leverages model-generated explanations to refine both when and what evidence is retrieved. By assessing triggering confidence from multiple dimensions, constructing entity-aware indices, and prioritizing contrastive evidence, ExDR demonstrably improves retrieval accuracy and overall detection performance on benchmark datasets. Could this explanation-driven approach represent a crucial step towards building more robust and reliable systems for combating the spread of online misinformation?
The Illusion of Understanding: Why Current Systems Fall Short
The proliferation of multimedia content online presents a significant challenge to automated fake news detection, as increasingly sophisticated manipulations bypass simplistic pattern recognition. Traditional methods often focus on textual cues or superficial image analysis, proving inadequate against fabricated content that skillfully mimics authentic sources. Identifying disinformation now requires models capable of dissecting the interplay between visual and textual elements, assessing contextual consistency, and understanding the implied meaning beyond surface-level features. These systems must move beyond merely identifying keywords or obvious visual distortions and instead emulate the critical thinking skills humans employ when evaluating the veracity of information – a process demanding a deeper comprehension of both content and context to avoid being misled by cleverly crafted deceptions.
Current methods employing Large Vision-Language Models (LVLMs) frequently struggle with the intricate task of detecting subtle manipulations within multimedia content. While adept at recognizing overt discrepancies, these models often falter when faced with nuanced deceptions-altered details, misleading contextual cues, or cleverly disguised forgeries. The core issue lies in a reliance on correlational patterns rather than a genuine understanding of the underlying semantics and physical plausibility of the visual and textual data. Consequently, LVLMs may misinterpret cleverly crafted misinformation, failing to identify inconsistencies that a human observer would readily recognize as problematic. This limitation underscores the need for models capable of performing more sophisticated reasoning, moving beyond simple pattern matching to achieve a deeper, more robust comprehension of multimodal information.
Current multimodal models often struggle with the complexities of real-world data because they lack the capacity for targeted knowledge integration. These systems frequently process information broadly, attempting to discern meaning without specifically accessing and applying relevant external knowledge – a process akin to solving a puzzle without all the necessary pieces. This inefficient approach leads to increased computational demands and, crucially, elevates the risk of inaccuracies, particularly when faced with subtle manipulations or nuanced contexts. The inability to pinpoint and utilize precise knowledge resources hinders the model’s capacity for robust reasoning, ultimately impacting its ability to reliably interpret and validate the authenticity of multimedia content.
ExDR: A Pragmatic Approach to Knowledge Integration
The ExDR framework leverages Retrieval-Augmented Generation (RAG) by integrating information retrieved from external knowledge sources into the generative process. This is achieved by first formulating a query based on the input text, then retrieving relevant documents or data snippets from a designated knowledge base. These retrieved elements are then incorporated as context alongside the original input, providing the language model with supplementary evidence to inform its reasoning and output generation. This approach allows ExDR to go beyond the limitations of the model’s pre-trained parameters, enabling it to access and utilize current, factual information during decision-making, and ultimately improve the reliability and accuracy of its responses.
Traditional Static Retrieval-Augmented Generation (RAG) systems perform information retrieval for every input, regardless of necessity. In contrast, the ExDR framework implements Dynamic RAG by incorporating a gating mechanism that assesses the need for external knowledge before initiating retrieval. This selective retrieval process is based on an evaluation of the input query; if the model determines sufficient internal knowledge exists to formulate a response, retrieval is bypassed. Consequently, external data is only accessed when the input necessitates it, optimizing processing efficiency and concentrating computational resources on instances where external evidence directly contributes to informed decision-making.
By selectively retrieving external evidence only when required for decision-making, the ExDR framework reduces computational expense associated with Retrieval-Augmented Generation. This dynamic approach contrasts with static RAG systems which retrieve information regardless of relevance, leading to unnecessary processing. Focusing retrieval on critical information directly relevant to the claim being evaluated enhances the accuracy of fake news detection, as the model is less likely to be influenced by extraneous or misleading data. This targeted strategy optimizes both efficiency and performance in identifying false information.

Measuring Confidence: Knowing What You Don’t Know
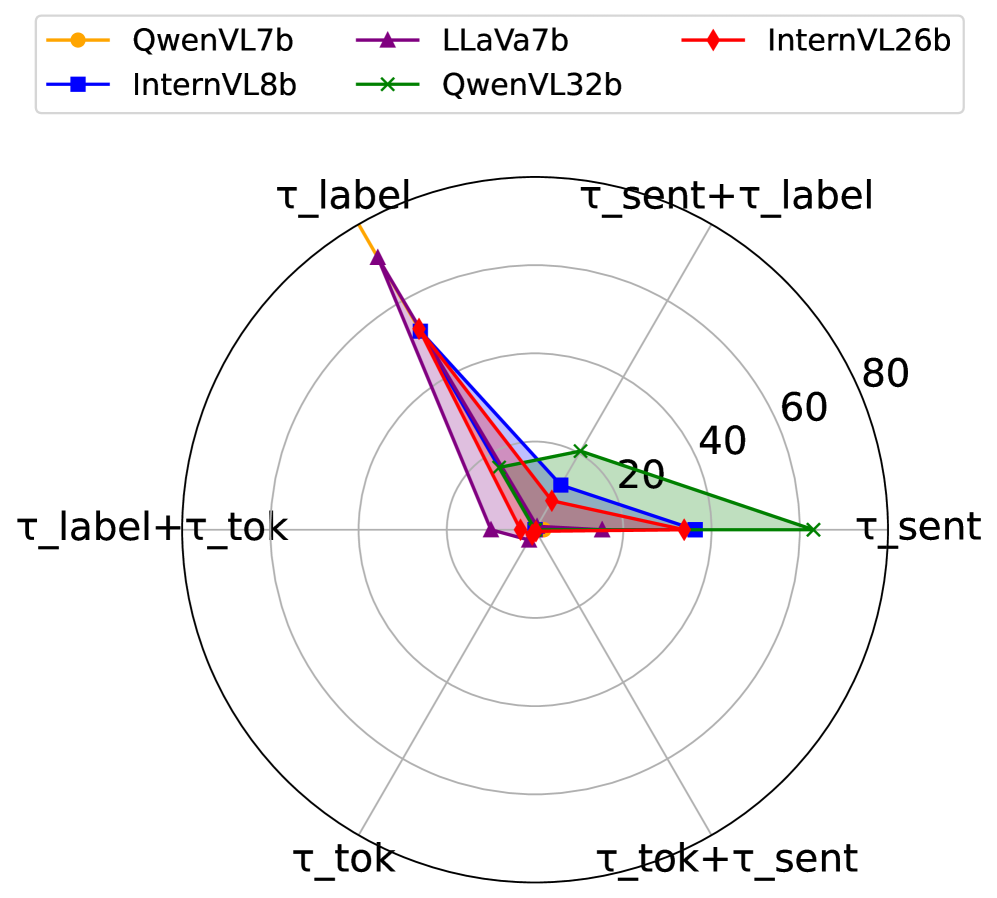
ExDR’s Confidence Estimation process utilizes a multi-faceted approach to assess prediction reliability. Sentence-level Confidence quantifies the model’s certainty regarding the overall response. Label-level Uncertainty measures the ambiguity associated with the assigned label, indicating potential misclassification risk. Token-level Support evaluates the degree to which individual tokens within the retrieved evidence corroborate the prediction, providing granular insight into the evidence’s relevance. These metrics are combined to generate a comprehensive confidence score, enabling the system to discern high-quality predictions from those requiring further scrutiny or refinement.
ExDR’s confidence estimation process directly contributes to system robustness by evaluating the validity of both the generated prediction and the supporting evidence used to reach that prediction. This dual assessment involves quantifying uncertainty at multiple levels – sentence, label, and token – allowing the framework to identify potentially unreliable outputs. By flagging predictions with low confidence scores or insufficient supporting evidence, ExDR can mitigate the risk of propagating inaccurate information and improve the overall dependability of the system’s responses, even when faced with ambiguous or challenging inputs.
Evaluations conducted using the AMG and MR2 datasets demonstrate that the ExDR framework achieves improvements in both Retrieval Efficiency and Retrieval Identification Rate. Specifically, when paired with the LLaVA-1.6-Mistral-7B model and utilizing contrastive evidence retrieval, ExDR attained an accuracy of 83.7%. Furthermore, performance benchmarks against the MGCA baseline on the AMG dataset indicate a 2.9% increase in accuracy when using ExDR.
The Value of Doubt: Why Considering Opposing Evidence Matters
The ExDR system distinguishes itself through a deliberate approach to evidence gathering, actively seeking not only information that supports a claim, but also evidence that challenges it. This contrastive evidence retrieval is founded on the principle that a truly robust understanding requires acknowledging and addressing counterarguments. By presenting a balanced perspective, the system encourages a more nuanced and critical evaluation of the claim at hand, moving beyond simple confirmation bias. This method allows for a deeper analysis, identifying potential weaknesses or limitations that might otherwise be overlooked, ultimately leading to more reliable and well-supported conclusions. The practice mirrors the hallmarks of sound reasoning, where acknowledging opposing viewpoints strengthens, rather than diminishes, the validity of an argument.
The system achieves robust evidence retrieval through entity-enriched multimodal indexing, a process that moves beyond simple keyword searches. This technique identifies and catalogues information not just by the words used, but by the underlying entities – people, places, concepts – discussed within text, images, and other data formats. By connecting these entities across diverse sources, the system can pinpoint relevant evidence even when expressed using different phrasing or presented in varied media. This nuanced approach allows for a more comprehensive and efficient search, retrieving information that a traditional system might miss, and ultimately strengthening the ability to evaluate complex claims with a broader range of supporting and contrasting perspectives.
The system’s capacity for adaptive knowledge integration represents a substantial leap beyond traditional, static retrieval methods. Instead of simply gathering information that confirms a hypothesis, it selectively incorporates both supporting and refuting evidence, fostering a more comprehensive understanding of the subject matter. This nuanced approach doesn’t merely enhance the accuracy of conclusions; it also dramatically improves explainability, allowing for a clearer articulation of why a particular answer is justified. Empirical results confirm this advantage, with metrics like Retrieval Identification Rate – the ability to pinpoint relevant information – and overall Retrieval Effectiveness consistently demonstrating superior performance compared to systems reliant on fixed knowledge bases. This dynamic process enables more robust reasoning and provides a transparent audit trail for its conclusions.
The pursuit of increasingly sophisticated retrieval mechanisms, as demonstrated by ExDR, feels less like progress and more like accruing technical debt. This framework attempts to intelligently select evidence, dynamically retrieving only what’s needed for multimodal fake news detection. It’s a noble effort, yet one built on the assumption that perfect information retrieval is achievable. The system estimates confidence based on contrastive evidence, a neat trick, but production environments have a habit of introducing edge cases that shatter such elegant confidence scores. It recalls Alan Turing’s observation: “There is no pleasure in ease, only in overcoming.” The complexity of discerning truth from falsehood isn’t lessened by clever algorithms; it’s merely shifted, creating new failure modes and a constant need for adaptation.
What’s Next?
The pursuit of explanation-driven retrieval, as exemplified by ExDR, inevitably encounters the limits of explicitness. Every elegantly constructed rationale will, in production, be challenged by data that simply is, devoid of convenient justification. The framework rightly focuses on when to retrieve, acknowledging that not all evidence strengthens a case – a lesson often learned the hard way. The real challenge isn’t building a better retriever, but anticipating the adversarial nature of the information landscape itself.
Current confidence estimation methods, even those leveraging contrastive evidence, treat uncertainty as a bug rather than a feature. The field will likely move toward models that not only detect falsehoods, but quantify their undetectability – recognizing that some manipulations are designed to bypass any automated system. The illusion of complete verification is a costly one.
Ultimately, the architecture isn’t a diagram of intent, but a compromise that survived deployment. ExDR, and systems like it, will be iteratively refined by the endless process of identifying what failed, not what succeeded. Everything optimized will one day be optimized back, and the cycle continues. The goal isn’t to eliminate fake news, but to build systems resilient enough to degrade gracefully in its presence.
Original article: https://arxiv.org/pdf/2601.15820.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Silver Rate Forecast
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Transformers Under the Microscope: What Graph Neural Networks Reveal
2026-01-24 03:14