Author: Denis Avetisyan
This review examines how integrating topological data analysis, Bayesian methods, and graph neural networks can create more robust and reliable artificial intelligence systems.
A comprehensive analysis of advancements in neural networks for improved uncertainty quantification and performance in complex data environments.
Despite advances in artificial intelligence, robust performance under real-world uncertainty remains a critical challenge, particularly in high-stakes applications. This work, ‘From Classical to Topological Neural Networks Under Uncertainty’, investigates a novel integration of artificial neural networks, Bayesian methods, and topological data analysis – including graph neural networks – to address this limitation. By leveraging topological features and quantifying uncertainty, the authors demonstrate enhanced robustness, interpretability, and generalization across diverse data modalities relevant to military domains. Could these techniques unlock a new generation of resilient and trustworthy AI systems capable of operating effectively in complex, unpredictable environments?
The Evolving Landscape of Intelligence: Foundations in Neural Networks
The pursuit of artificial intelligence centers on constructing computational models capable of replicating facets of human cognition – learning, problem-solving, and decision-making. This ambition isn’t about creating perfect replicas of the human brain, but rather about designing systems that perform cognitive tasks. These systems achieve this through algorithms and data structures that mimic, at varying levels of abstraction, the processes believed to underpin human intelligence. From simple rule-based systems to complex machine learning models, each approach represents an attempt to capture and formalize aspects of how humans perceive, reason, and interact with the world. The success of these models is measured not by their internal workings, but by their ability to achieve comparable results on specific cognitive tasks, ultimately pushing the boundaries of what machines can accomplish.
The architecture of modern intelligent systems fundamentally relies on neural networks, computational models deliberately structured to mimic the human brain. These networks consist of interconnected nodes, or “neurons,” organized in layers; each connection possesses a weight representing its strength, and information flows through these connections as signals. This design allows the network to learn from data by adjusting these weights – a process known as training – enabling it to recognize patterns, make predictions, and ultimately perform complex tasks. While vastly simplified compared to biological brains, this bio-inspired approach has proven remarkably effective, forming the basis for advancements in areas like image recognition, natural language processing, and game playing, and continues to drive innovation in the field of artificial intelligence.
The initial triumphs of Convolutional Neural Networks in image recognition and Recurrent Neural Networks in sequential data processing, such as natural language, quickly established deep learning as a powerful tool. However, these architectures, while excelling at pattern recognition within structured data, began to reveal inherent limitations when confronted with information demanding an understanding of relationships between entities. For instance, accurately interpreting scenarios requiring common-sense reasoning – knowing that a ‘cup’ is typically held, or that ‘fire’ is dangerous – proved challenging. This stems from their foundational design; early neural networks primarily focused on extracting features from raw data, lacking the explicit mechanisms to represent and reason about the complex, interconnected knowledge that characterizes much of the real world. Consequently, research shifted toward architectures capable of capturing and utilizing relational information, aiming to move beyond pattern recognition to true cognitive understanding.
Beyond Euclidean Space: Modeling Relationships with Graph Neural Networks
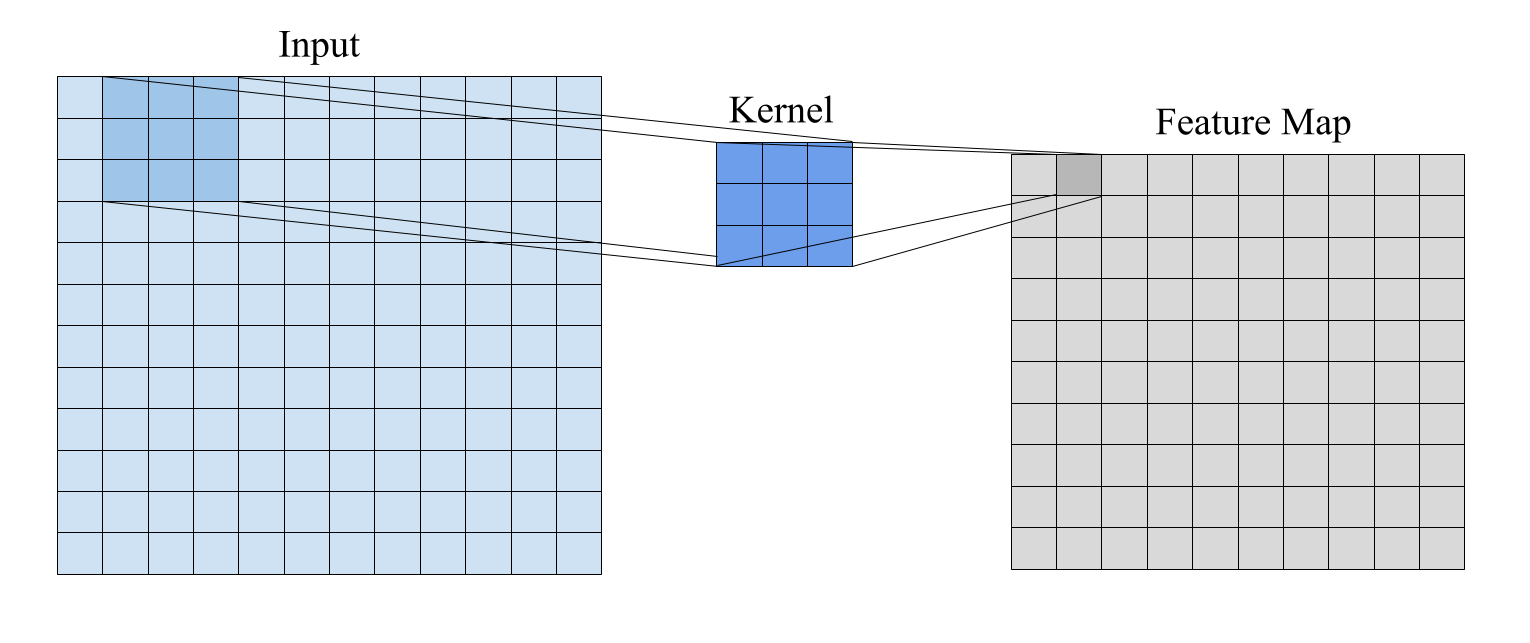
Graph Neural Networks (GNNs) represent a significant advancement beyond traditional neural networks by enabling direct processing of data organized as graphs. Unlike conventional networks which typically require data to be represented in Euclidean space, GNNs operate on non-Euclidean structures comprising nodes and edges. This capability allows GNNs to explicitly model relationships between entities – represented as nodes – through the edges connecting them. The network learns representations for each node by aggregating feature information from its neighbors, effectively capturing structural dependencies within the graph. This is crucial for applications where relationships between data points are as important as the data points themselves, such as social networks, knowledge graphs, and molecular structures.
Graph Convolutional Networks (GCNs) utilize spectral graph theory to perform convolution operations directly on graph structures. The core principle involves defining convolution in the spectral domain by decomposing the graph Laplacian into eigenvectors and eigenvalues. A filter, represented as a function of the Laplacian eigenvalues \tilde{Θ}(λ) , is applied to these eigenvalues. The aggregated information from a node’s neighborhood is then computed by transforming the filter back to the spatial domain and multiplying it with the node’s feature vector. This process effectively smooths node features based on the graph connectivity, allowing the network to learn representations that consider both node attributes and their relationships within the graph. The mathematical formulation enables efficient parallelization and captures non-Euclidean data dependencies inherent in graph structures.
Addressing the computational demands of applying Graph Neural Networks (GNNs) to large graphs, GraphSAGE and GraphSAINT introduce sampling techniques to mitigate scalability issues and reduce bias. Traditional GNNs require processing the entire graph, leading to quadratic complexity with the number of nodes. GraphSAGE addresses this by learning to aggregate features from a fixed-size neighborhood, sampled randomly, instead of using the entire adjacency. GraphSAINT further improves efficiency by performing importance sampling on both node neighborhoods and feature dimensions, allowing for stochastic mini-batch training. These methods reduce computational cost and memory requirements, enabling the application of GNNs to graphs with millions or even billions of nodes, while also mitigating the bias that can arise from processing only a subset of the graph’s connections.
Uncertainty as a Feature: Bayesian Approaches to Deep Learning
Bayesian statistics differs from frequentist approaches by treating model parameters as random variables with associated probability distributions, rather than fixed but unknown values. This allows for the incorporation of prior beliefs about the parameters – expressed as a prior probability distribution – which are then updated based on observed data using Bayes’ theorem to produce a posterior distribution. Quantification of uncertainty is inherent in this process; predictions are not single point estimates but rather probability distributions reflecting the uncertainty in the parameter estimates. This is mathematically represented as p(\theta|D) = \frac{p(D|\theta)p(\theta)}{p(D)}, where p(\theta|D) is the posterior, p(D|\theta) is the likelihood, p(\theta) is the prior, and p(D) is the evidence. The resulting posterior predictive distribution then provides a full probabilistic prediction, including measures of confidence or uncertainty like credible intervals.
Bayesian Neural Networks (BNNs) differ from traditional neural networks by representing model weights and biases as probability distributions rather than single point estimates. This is achieved through techniques like variational inference or Markov Chain Monte Carlo (MCMC) methods to approximate the posterior distribution over the network’s parameters given the observed data. Consequently, predictions are made by averaging over this distribution, effectively integrating over possible parameter values and yielding a more calibrated estimate of uncertainty. This probabilistic treatment of parameters inherently leads to more robust performance, particularly when dealing with noisy or limited datasets, as the model is less likely to overfit to spurious correlations and more capable of generalizing to unseen data. The resulting distribution over predictions allows for quantifying the model’s confidence in its output, providing a measure of reliability crucial for high-stakes applications.
Bayesian Neural Networks (BNNs) generate probabilistic predictions, allowing for the calculation of confidence intervals that reflect the model’s certainty regarding its output. These intervals, derived from the distribution of predicted parameters, provide a quantifiable measure of prediction reliability; wider intervals indicate higher uncertainty. Critically, BNNs can flag predictions falling outside acceptable confidence thresholds as potentially unreliable, which is valuable in high-stakes applications such as medical diagnosis, autonomous driving, and financial modeling. This capability enables informed decision-making by alerting users to predictions where the model expresses low confidence, facilitating human oversight or triggering alternative actions. The quantification of epistemic uncertainty – uncertainty due to lack of knowledge – distinguishes BNNs from standard deep learning models that typically output only point estimates without associated confidence measures.
Revealing Hidden Structure: Topology and Deep Learning
Topological Data Analysis, or TDA, moves beyond traditional data analysis by focusing not on metric measurements, but on shape. It employs tools from algebraic topology – a branch of mathematics concerned with properties preserved through continuous deformations – to reveal the connected components and “holes” within datasets, regardless of their specific coordinates. Imagine a cloud of points; TDA doesn’t just see a collection of locations, but identifies clusters, loops, and cavities – features that might represent meaningful patterns obscured by noise or high dimensionality. This is achieved through techniques like persistent homology, which tracks these topological features as a scale parameter changes, effectively filtering out noise and highlighting the most significant structural characteristics. \text{Persistent homology} provides a robust way to quantify these shapes, offering insights that are invariant to small changes in the data and can reveal underlying relationships previously undetectable by conventional methods.
Topological Deep Learning emerges as a powerful synergy, combining the geometric insights of Topological Data Analysis with the representational capacity of deep neural networks. Traditional deep learning models often struggle with data exhibiting complex, high-dimensional structures, particularly when relevant information is distributed non-locally-that is, across distant data points. By incorporating topological methods, these models gain the ability to identify and leverage these long-range dependencies, effectively ‘seeing’ the bigger picture beyond immediate neighbors. This integration doesn’t simply add another layer of computation; it fundamentally alters how the model perceives data, creating more robust and generalizable representations capable of handling noisy or incomplete information. The result is improved performance in tasks ranging from image recognition and natural language processing to materials discovery and drug design, where understanding the underlying shape and connectivity of data is crucial.
Graph Attention Networks, a powerful class of neural networks, implicitly perform a form of topological analysis by selectively weighting connections between nodes. Rather than treating all relationships equally, these networks learn to assign higher importance – or “attention” – to edges that reveal crucial structural information within the graph. This process mirrors the core principles of topological data analysis, which seeks to identify significant features – such as loops and connected components – that define a dataset’s shape. By focusing on these informative connections, Graph Attention Networks can effectively distill the underlying topology of the graph, enabling them to learn more robust and generalizable representations, even in the presence of noise or incomplete data. This inherent topological reasoning allows the network to capture non-local dependencies and understand the global structure of the graph, improving performance on tasks like node classification and graph prediction.
Towards Intelligent Systems: Robustness, Explainability, and the Future of AI
Conventional Recurrent Neural Networks (RNNs), while designed to process sequential data, often struggle with learning dependencies across extended time intervals due to the ‘vanishing gradient’ problem – where gradients diminish exponentially as they are backpropagated through many time steps. Long Short-Term Memory (LSTM) networks represent a significant advancement, directly addressing this limitation through a sophisticated memory cell architecture. This cell incorporates ‘gates’ – input, forget, and output – that regulate the flow of information, allowing the network to selectively retain or discard data over long sequences. By maintaining a constant error flow, LSTMs effectively mitigate the vanishing gradient, enabling the modeling of long-range dependencies crucial for tasks involving temporal data, such as natural language processing, speech recognition, and time series analysis. This capability allows LSTMs to capture contextual information that would be lost in traditional RNNs, resulting in improved performance and more nuanced understanding of sequential data.
The pursuit of truly intelligent systems necessitates a shift beyond mere accuracy, demanding robustness, explainability, and adaptability. Recent advancements indicate a promising convergence of Bayesian methods and Topological Deep Learning to achieve these goals. By integrating the probabilistic reasoning of Bayesian networks with the geometric understanding of topological data analysis, these hybrid models move beyond pattern recognition to establish a more nuanced comprehension of data. This allows for uncertainty quantification – a critical component of robust AI – and facilitates the generation of human-interpretable explanations for model decisions. Furthermore, the inherent ability of topological methods to capture the underlying structure of data, even in noisy or incomplete datasets, enhances the model’s capacity to generalize and adapt to previously unseen environments, paving the way for AI systems capable of reliable performance in dynamic, real-world scenarios.
Recent advancements in intelligent systems, as detailed in this review, have yielded notable performance gains in complex signal processing tasks. Specifically, combining Bayesian methods with Topological Deep Learning has achieved up to 93% accuracy in radar emitter identification, even under low signal-to-noise ratio (SNR) conditions – scenarios that traditionally challenge signal detection. This represents a significant improvement over standard recurrent neural network architectures, such as Gated Recurrent Units (GRU) without attention mechanisms, which demonstrate comparatively lower performance in these demanding environments. The demonstrated success suggests a promising trajectory for creating AI systems capable of reliable operation and insightful decision-making in real-world applications characterized by noisy or incomplete data.
The pursuit of robust artificial intelligence, as detailed in this exploration of neural networks under uncertainty, mirrors a fundamental truth about all complex systems. The article rightly emphasizes data curation and model calibration as crucial elements – acknowledging that even the most sophisticated architecture is only as reliable as the information it processes. This resonates with Claude Shannon’s observation: “The most important component of a communication system is the human being.” While the study focuses on technical implementations-Bayesian methods, topological data analysis, and graph neural networks-it implicitly recognizes that the ‘signal’ of meaningful insight is lost without careful attention to the ‘noise’ of flawed or incomplete data. Every architecture lives a life, and we are just witnesses to its eventual decay, necessitating continuous refinement and adaptation, even in the face of inherent uncertainty.
What Remains to be Seen
The convergence of classical and topological neural networks, as explored within these pages, does not represent an arrival, but a re-alignment. Every failure is a signal from time; the observed enhancements in uncertainty quantification, while promising, merely delay the inevitable entropy. The efficacy of these methods remains tethered to the quality of curated data, a dependency that highlights a fundamental limitation-the system’s inability to transcend the imperfections of its source material. Future work must address not simply how to model uncertainty, but what constitutes meaningful information in the face of inherent noise.
The present investigation points toward a necessary expansion of graph neural networks, moving beyond structural relationships to encompass a more nuanced understanding of dynamic systems. Refactoring is a dialogue with the past; each iteration of model calibration represents an attempt to reconcile present performance with the accumulated weight of prior assumptions. The true challenge lies in designing networks capable of graceful degradation, systems that acknowledge the transient nature of knowledge and adapt accordingly.
Ultimately, the pursuit of robust AI in complex domains-particularly those with military applications-demands a shift in perspective. The goal is not to eliminate uncertainty, but to build systems that can navigate it with resilience. The metrics of success will not be defined by accuracy alone, but by the capacity to learn from error and to anticipate the inevitable decay of predictive power.
Original article: https://arxiv.org/pdf/2602.10266.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Top 20 Dinosaur Movies, Ranked
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Gold Rate Forecast
- Silver Rate Forecast
- Spotting the Loops in Autonomous Systems
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Top 10 Coolest Things About Invincible (Mark Grayson)
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
2026-02-12 10:16