Author: Denis Avetisyan
A new approach uses natural language descriptions to help artificial intelligence pinpoint and understand anomalies in industrial images, improving defect detection and localization.
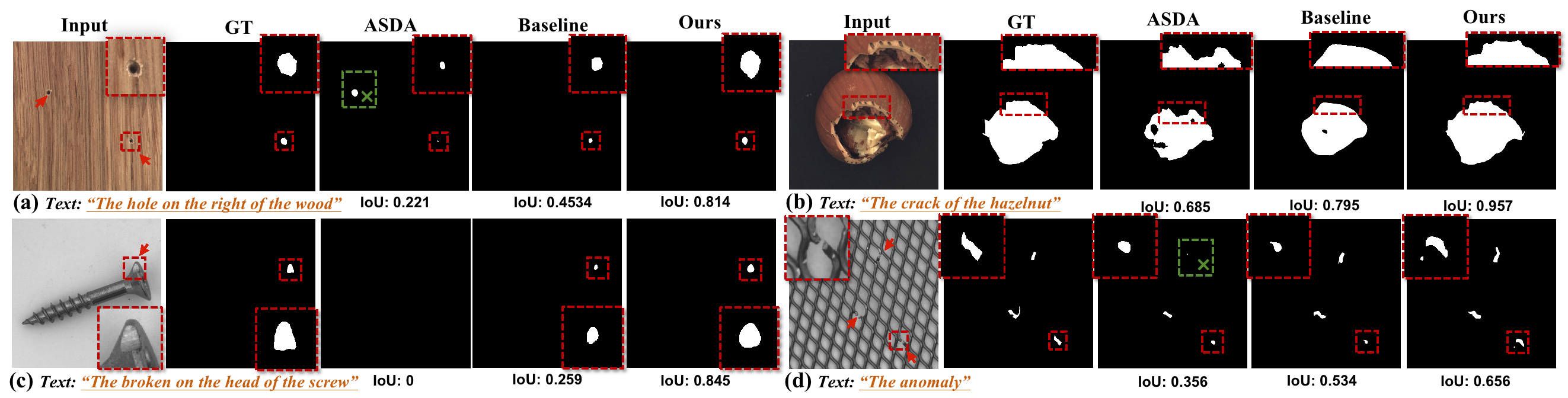
Researchers introduce Referring Industrial Anomaly Segmentation (RIAS) and the MVTec-Ref dataset, achieving state-of-the-art results with the Dual Query Token with Mask Group Transformer (DQFormer).
Despite advances in industrial quality control, current anomaly detection methods struggle with limited data and often require manual tuning or are constrained by single-anomaly-class limitations. To address these challenges, this paper introduces a novel paradigm, ‘Referring Industrial Anomaly Segmentation’, which leverages natural language descriptions to guide precise anomaly localization and segmentation in industrial images. Through the introduction of the MVTec-Ref dataset and the Dual Query Token with Mask Group Transformer (DQFormer) architecture-enhanced by Language-Gated Multi-Level Aggregation-we demonstrate state-of-the-art performance and open-set capabilities. Could this language-guided approach pave the way for more robust and adaptable industrial inspection systems?
The Illusion of Control: Why Simple Anomaly Detection Fails
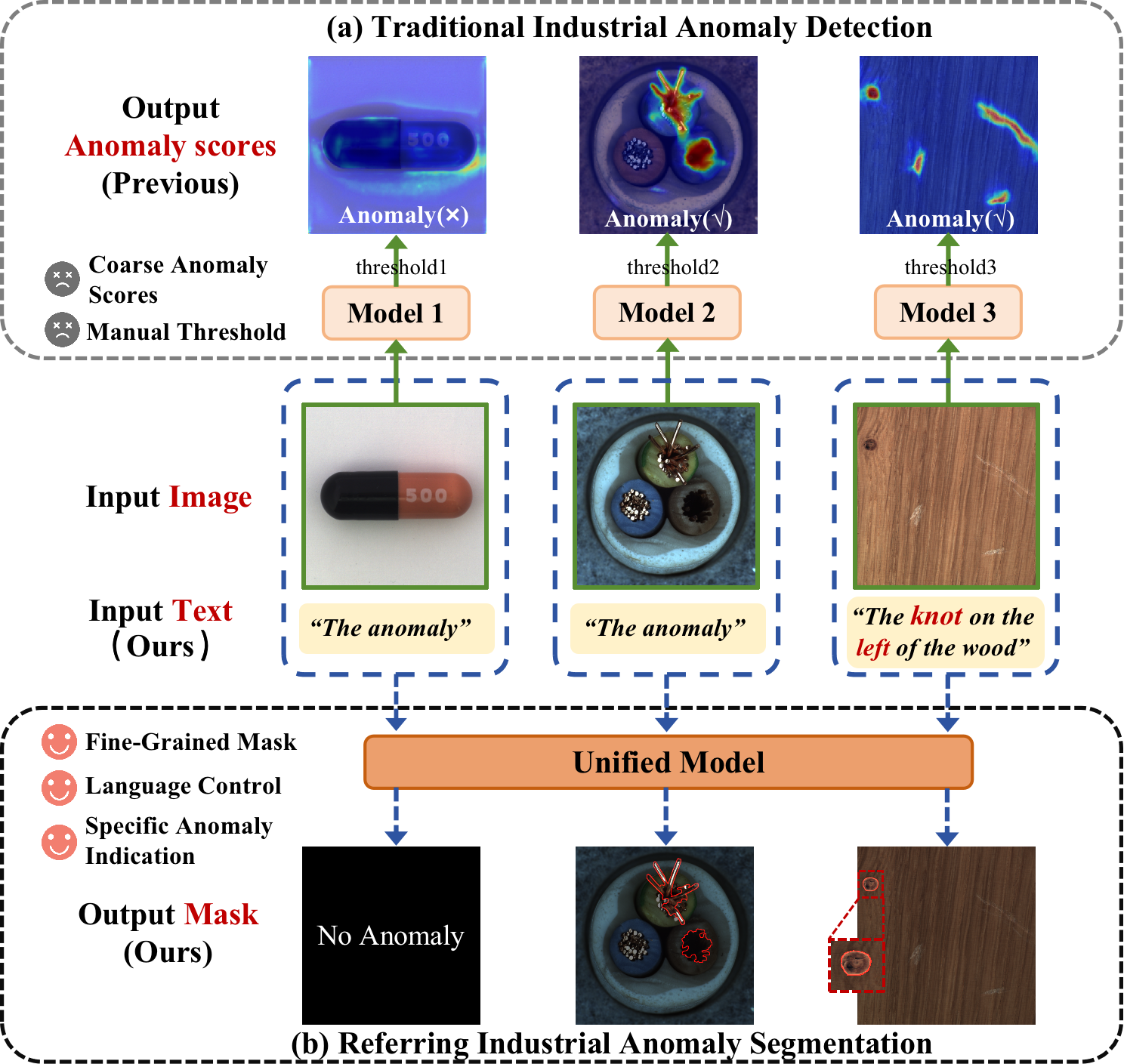
Conventional anomaly detection systems, while effective in controlled environments, frequently encounter difficulties when deployed in the intricacies of real-world industrial scenarios. These systems often lack the capacity to understand the context surrounding an object or process, leading to a high incidence of false positives. For instance, a slightly discolored component might be flagged as defective when, in reality, it simply reflects a change in lighting or a minor, inconsequential variation in material texture. This limitation stems from a reliance on purely visual features or statistical deviations, without incorporating semantic understanding of what constitutes ‘normal’ within that specific industrial context. Consequently, operators are often inundated with alerts for non-issues, diminishing trust in the system and hindering its practical application – a critical challenge demanding more nuanced and context-aware approaches.
The accurate identification of anomalies in industrial settings is often hampered by a lack of contextual awareness; systems frequently flag normal variations as errors. While natural language descriptions offer a powerful means of injecting this crucial semantic understanding – specifying, for instance, “a crack in the turbine blade” rather than simply “anomaly detected” – effectively merging textual information with visual data remains a significant hurdle. Current methods struggle to align linguistic cues with corresponding image regions, leading to imprecise localization and reduced reliability. This integration is complicated by variations in language, image quality, and the inherent ambiguity present in both modalities, demanding innovative approaches to bridge the gap between what is said and what is seen for truly robust anomaly detection.
Referring Industrial Anomaly Segmentation, or RIAS, represents a significant advancement in defect detection by unifying visual analysis with natural language understanding. This novel paradigm moves beyond simply identifying what is anomalous, and instead focuses on where and why, by grounding anomaly detection in descriptive language. The system leverages the strengths of both modalities – the precise localization capabilities of computer vision and the semantic richness of language – to achieve more robust performance in complex industrial environments. By associating textual descriptions with specific regions in images, RIAS not only pinpoints defects with greater accuracy, but also provides interpretable results, enabling human operators to quickly understand the nature of the problem and facilitate efficient repairs. This approach minimizes false positives common in traditional methods and offers a pathway toward truly intelligent and collaborative industrial inspection systems.
Dual Attention: Focusing on What Matters, Ignoring the Noise
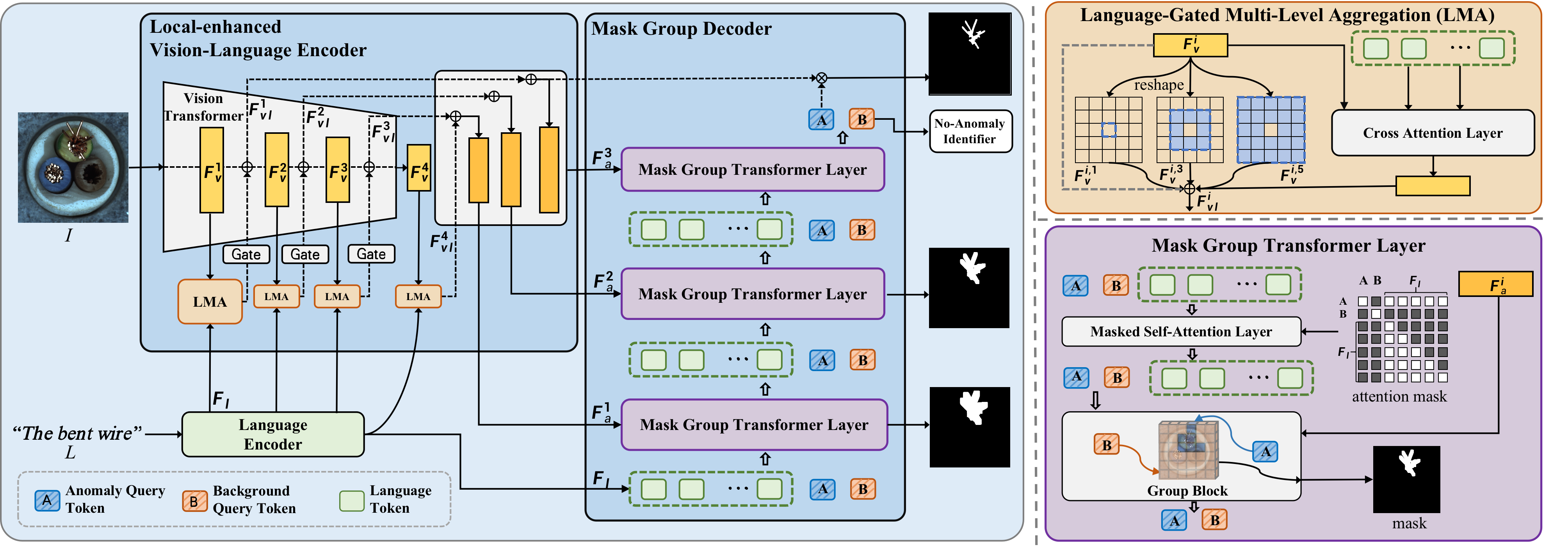
The Dual Query Token mechanism operates by introducing two distinct query tokens during the anomaly detection process: an Anomaly Query Token and a Background Query Token. These tokens function as learned embeddings that explicitly guide the model’s attention. The Anomaly Query Token focuses the model on identifying and segmenting potential anomalous regions within an image, while the Background Query Token simultaneously defines and represents the normal, non-anomalous areas. This explicit delineation allows the model to differentiate between foreground anomalies and background elements, improving the accuracy of anomaly segmentation and reducing false positives by minimizing attention to irrelevant image features.
By explicitly directing the model’s attention to potential anomalies via the Dual Query Token mechanism, computational resources are concentrated on relevant image regions. This selective focus diminishes the influence of irrelevant background information – effectively reducing noise – and enables the model to more precisely delineate anomaly boundaries. The resulting improvement in signal-to-noise ratio directly translates to enhanced segmentation accuracy, particularly in scenarios with subtle or complex anomalies, as the model is less likely to be misled by distracting elements within the image.
The Mask Group Transformer architecture facilitates the concurrent processing of multiple anomaly instances present within a single input image. This is achieved by grouping the features associated with each detected anomaly instance, effectively creating a ‘mask group’ for parallel computation. This approach contrasts with methods that process anomalies individually, leading to improved computational efficiency and reduced processing time when dealing with images containing numerous anomalies. The transformer layers then operate on these mask groups, enabling the model to learn relationships between different anomaly instances and their surrounding context, ultimately enhancing segmentation performance and overall accuracy.
Local Detail: Why the Devil is Always in the Details
The Local-Enhanced Vision-Language Encoder (LVLE) addresses limitations in anomaly detection by explicitly focusing on the enhancement of local visual features. This is achieved through a multi-level process designed to capture fine-grained details often critical for identifying subtle anomalies. Traditional methods may struggle with anomalies exhibiting limited spatial extent or nuanced textural differences; the LVLE aims to mitigate this by prioritizing the extraction and representation of these local characteristics. The enhancement process isn’t a single operation but rather a series of refinements applied at multiple scales, allowing the encoder to effectively represent both small-scale textural anomalies and larger, more complex deviations from normal patterns. This focus on local detail is intended to improve the robustness and accuracy of anomaly segmentation tasks.
The Local-Enhanced Vision-Language Encoder (LVLE) utilizes a Swin Transformer architecture as its foundational component due to the inherent advantages of its shifted window approach to self-attention. Traditional self-attention mechanisms exhibit quadratic complexity with image resolution, limiting their scalability to high-resolution inputs. The Swin Transformer addresses this by performing self-attention within local windows, and then shifting these windows in successive layers. This localized computation reduces complexity to linear with image size, enabling efficient processing of detailed visual information. Furthermore, the hierarchical structure of the Swin Transformer naturally captures multi-scale features, which is crucial for detecting anomalies that vary in size and appearance.
The Local-Enhanced Vision-Language Encoder (LVLE) utilizes Cross-Modal Attention to integrate visual and linguistic information at multiple scales. This process involves applying attention mechanisms that allow the model to weigh the importance of different visual features based on their relevance to the input language, and vice versa. By performing this fusion at multiple scales – leveraging feature maps of varying resolutions – the LVLE captures both broad contextual information and fine-grained details. The resulting cross-modal representation effectively combines visual cues with semantic understanding from the language input, which is then used to generate a comprehensive feature map specifically designed for accurate anomaly segmentation. This multi-scale approach enables the model to effectively identify anomalies regardless of their size or complexity within the visual input.
Language-Gated Multi-Level Aggregation (LGMA) operates by utilizing linguistic information to dynamically weight and combine visual features extracted at multiple scales. This process involves generating gating vectors from the encoded language input, which are then applied to the multi-scale visual features. Specifically, LGMA allows the model to prioritize relevant visual details based on the textual query, effectively suppressing noise and emphasizing features indicative of anomalies. By aggregating these weighted features across different scales, the system improves its ability to detect both small, subtle anomalies and larger, more complex ones, resulting in enhanced performance across a wider range of anomaly characteristics and sizes.
The MvTec-Ref Dataset: A Foundation for Meaningful Progress
A significant advancement in industrial anomaly detection arrives with the introduction of the MvTec-Ref dataset, a novel resource built upon the established MvTec-AD dataset. This expansion moves beyond simple image classification by incorporating image-language-label triplets, specifically designed for referring expression annotation. This innovative approach allows researchers to train and evaluate Referring Image Anomaly Segmentation (RIAS) models, enabling a more nuanced understanding of anomalies within complex industrial imagery. By linking visual features with descriptive language, the MvTec-Ref dataset facilitates the development of systems capable of not only identifying what is anomalous, but also where, based on natural language queries and precise localization – a crucial step toward more reliable and interpretable quality control in manufacturing settings.
The introduction of the MvTec-Ref dataset establishes a crucial foundation for advancements in Referring Image Anomaly Segmentation (RIAS) models. By providing image-language-label triplets – detailed annotations linking visual elements with descriptive language – the dataset enables researchers to train and rigorously evaluate the performance of these models in a standardized manner. This benchmark capability is particularly important for driving progress in the field, allowing for direct comparison of different approaches and accelerating the development of more accurate and reliable anomaly detection systems. The availability of MvTec-Ref fosters collaborative research and ensures consistent evaluation metrics, ultimately contributing to the broader adoption of RIAS technology in industrial quality control and beyond.
Evaluations on the MvTec-Ref dataset reveal a significant advancement in performance through this new approach. Specifically, experiments demonstrate a marked improvement over existing anomaly detection methods, achieving a 3.08% increase in mean Intersection over Union (mIoU) and a 3.42% rise in generalized Intersection over Union (gIoU) when assessed on the validation set. These gains indicate a heightened capacity for accurately localizing and segmenting anomalies within complex industrial imagery, suggesting the methodology effectively refines the precision of anomaly mask generation and provides a more reliable benchmark for future developments in the field.
Evaluations conducted on the MvTec-Ref test set reveal a substantial performance gain, with the proposed methodology achieving a 2.98% improvement in mean Intersection over Union (mIoU) and a 3.16% increase in generalized Intersection over Union (gIoU). These metrics, calculated across a held-out dataset, demonstrate the approach’s ability to generalize beyond the training and validation data. This robust performance across different data splits indicates that the model is not simply memorizing the training examples but is instead learning to identify and localize anomalies based on underlying visual and linguistic features, suggesting a reliable foundation for deployment in real-world industrial inspection scenarios.
The integration of language guidance with resilient visual feature extraction significantly enhances the precision and dependability of anomaly detection within complex industrial settings. This approach moves beyond solely visual cues, allowing the system to interpret contextual information provided through language – for instance, identifying a specific component or expected characteristic – to refine its assessment. Crucially, the resulting anomaly masks consistently cover less than 90% of the image area, indicating a high degree of localization and minimizing false positives; the system accurately pinpoints the defective regions without broadly highlighting large portions of otherwise normal surfaces, a critical requirement for efficient quality control and minimizing unnecessary intervention in automated manufacturing processes.

The pursuit of ever-more-detailed anomaly detection, as demonstrated by this work on Referring Industrial Anomaly Segmentation, feels predictably iterative. The authors achieve state-of-the-art results with their Dual Query Token with Mask Group Transformer, a complex architecture built to interpret language descriptions alongside visual data. It’s elegant, certainly. Geoffrey Hinton once observed, “I’m suspicious of things that look good on paper.” This rings true; while the MVTec-Ref dataset and the DQFormer show promise in precisely localizing defects, one anticipates the inevitable edge cases and production quirks that will surface. The need for language-gated multi-level aggregation is a clear attempt to add robustness, but experience suggests it’s merely delaying the inevitable march toward technical debt.
What’s Next?
The introduction of language-guided anomaly segmentation, while promising, merely shifts the point of failure. Currently, the system excels when language accurately describes the expected deviation. Production, however, rarely offers such clarity. Expect a proliferation of edge cases: ambiguous descriptions, subjective interpretations of ‘anomaly’, and the inevitable drift between linguistic intent and visual reality. The MVTec-Ref dataset, a necessary first step, will quickly reveal its limitations as industrial processes evolve and anomaly types diversify.
Future work will undoubtedly focus on grounding language in a more robust, physics-informed understanding of industrial systems. Relying solely on pixel-level correlations, even with linguistic guidance, feels inherently brittle. The challenge isn’t simply detecting what is anomalous, but why. A system that can reason about expected behavior, predict potential failures, and articulate those predictions in natural language offers a more sustainable, if significantly more complex, path forward.
Ultimately, this paradigm, like all others, will encounter the limits of its abstraction. The elegance of the Dual Query Token with Mask Group Transformer will, at some point, be undermined by the sheer chaotic complexity of the industrial world. It will die beautifully, perhaps, but it will crash. The real question is whether the resulting diagnostics will be expressed in a language humans can actually understand.
Original article: https://arxiv.org/pdf/2602.03673.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- ONE PIECE Season 2 Confirms Sanji’s OTHER Backstory in the Live-Action
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
2026-02-05 04:51