Author: Denis Avetisyan
Researchers are moving beyond traditional divergence measures to build more robust systems for identifying images that don’t fit the mold.
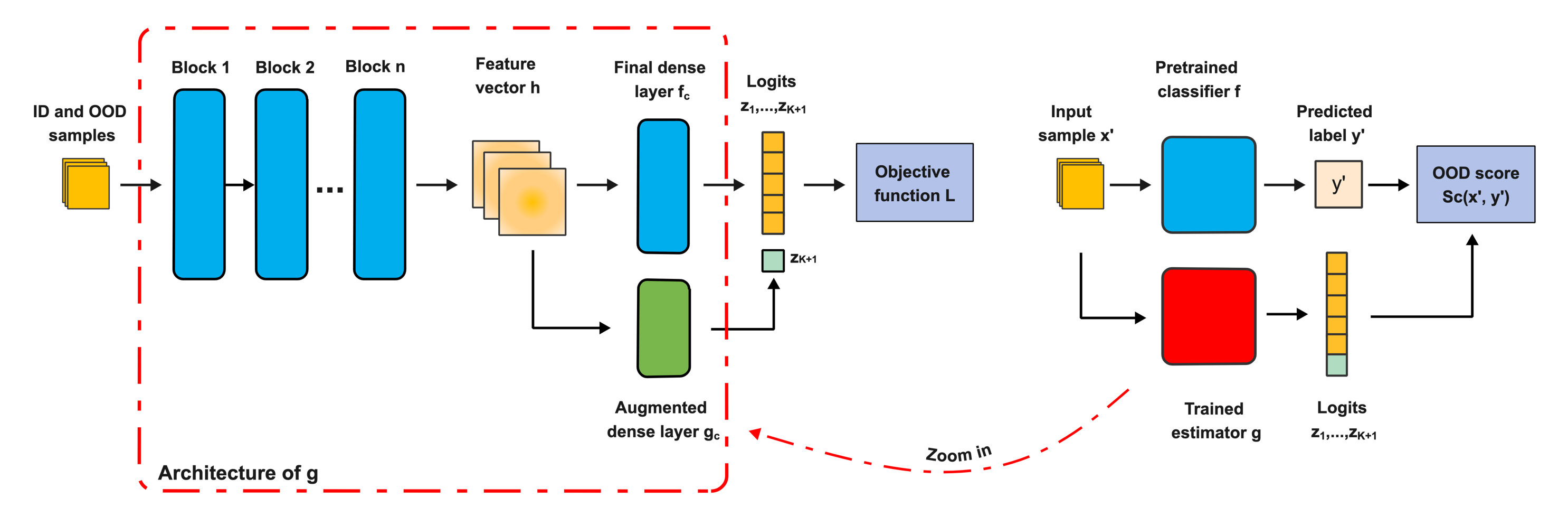
This review details TV-OOD, a novel out-of-distribution detection method leveraging total variation distance for improved performance in image classification tasks.
Reliable performance of machine learning models hinges on the assumption that test data aligns with training distributions, a condition rarely met in real-world deployments. This paper introduces a novel approach to address this challenge, presenting ‘Out-of-Distribution Detection Based on Total Variation Estimation’ which leverages total variation distance-an alternative to traditional KL divergence-to quantify the dissimilarity of input data. The proposed Total Variation Out-of-Distribution (TV-OOD) method demonstrably improves performance in image classification tasks, achieving comparable or superior results to state-of-the-art techniques. Could this shift in perspective unlock more robust and adaptable machine learning systems capable of navigating unpredictable data landscapes?
The Fragility of Pattern Recognition
Machine learning models, while powerful, exhibit a notable fragility when encountering data that diverges from their initial training. This limitation, termed Out-of-Distribution (OOD) detection, arises because these models learn to recognize patterns within a specific dataset, and struggle to generalize beyond those boundaries. Essentially, a model trained to identify cats and dogs may falter when presented with images of horses or airplanes, not due to a lack of processing power, but because the input falls outside its learned experience. This poses significant challenges, as real-world data is rarely static and often contains unexpected variations or entirely new categories, demanding systems capable of recognizing not just what they know, but also what they don’t.
The inherent limitations of current machine learning models present substantial risks when deployed in critical applications demanding unwavering reliability. Consider autonomous vehicles, where a model encountering an unforeseen road condition – perhaps a uniquely patterned construction zone or an unusual weather event – could misinterpret the environment, leading to potentially catastrophic consequences. Similarly, in medical diagnosis, a model trained on a specific patient demographic or imaging technique might struggle with data from an underrepresented group or a novel scanning protocol, resulting in inaccurate assessments and delayed treatment. These scenarios highlight that failures in out-of-distribution (OOD) detection aren’t simply statistical errors; they represent genuine threats to safety and well-being, underscoring the urgent need for more robust and adaptable machine learning systems.
Many current Out-of-Distribution (OOD) detection techniques stumble when applied to complex, real-world data because they are built upon simplifying assumptions about how data is distributed. These methods frequently presume data adheres to specific statistical patterns – such as Gaussian distributions or clearly defined clusters – which rarely hold true in dynamic environments. Consequently, a model trained to identify anomalies based on these flawed assumptions may incorrectly classify novel, yet perfectly valid, data as out-of-distribution, or conversely, fail to recognize genuinely dangerous anomalies. This reliance on unrealistic distributional models limits the reliability of OOD detection systems, creating significant challenges for safety-critical applications where accurate identification of unfamiliar data is paramount and false positives or negatives can have severe consequences.
Current research pivots towards characterizing data novelty through methods that transcend traditional distributional comparisons. Instead of simply identifying data points distant from the training set, these innovative approaches aim to understand why a data instance is unusual. This involves techniques like learning disentangled representations, which isolate meaningful features and allow for the detection of combinations unseen during training, or employing predictive models that quantify the uncertainty associated with novel inputs. Such methods move beyond flagging outliers to building a richer understanding of data characteristics, enabling more robust and reliable performance in real-world applications where unexpected or previously unseen data is commonplace. Ultimately, this shift promises to enhance the adaptability of machine learning systems and foster trust in their decision-making processes when faced with the unknown.
TV-OOD: Measuring the Shift
Total Variation (TV) estimation, as employed by TV-OOD, provides a method for quantifying the amount of change within a function or, in this context, a data distribution. Mathematically, TV measures the integral of the gradient magnitude of a function f, represented as \in t |\nabla f(x)| dx. Applied to data distributions, TV calculates the minimum number of changes required to transform one distribution into another. A higher TV distance indicates greater dissimilarity between the distributions, signifying a larger shift from the training data. This measure is particularly useful for Out-of-Distribution (OOD) detection as it focuses on the rate of change rather than absolute values, allowing for the identification of novel data points that deviate significantly from the established distribution.
The Total Variation Network Estimator (TVNE) is the computational engine of the TV-OOD framework, designed for efficient calculation of the Total Variation (TV) distance. The TV distance, TV(P,Q) = \frac{1}{2} \in t |p(x) - q(x)| dx, quantifies the minimum amount of “effort” required to transform one probability distribution into another. The TVNE approximates this integral using a neural network architecture, enabling rapid estimation of the TV distance between an input data sample and the established training distribution. This network is trained to directly predict the TV value, bypassing computationally expensive density estimation procedures required by alternative Out-of-Distribution (OOD) detection methods. The efficiency of the TVNE allows for scalable application of TV-OOD to large datasets and complex models.
TV-OOD’s reliance on quantifying distributional change, rather than absolute distributional shape, provides inherent robustness to common Out-of-Distribution (OOD) challenges. Traditional OOD detection methods often struggle when presented with distributions that differ only in minor ways or exhibit high-dimensional shifts. By focusing on the Total Variation (TV) – a measure of the amount a distribution changes – TV-OOD is less affected by the precise characteristics of the in-distribution data. This approach allows for effective detection of deviations from the training distribution, even when those deviations are subtle or occur in complex data spaces, as the metric prioritizes the rate of change rather than the absolute values of the distributions being compared.
TV-OOD distinguishes itself from many Out-of-Distribution (OOD) detection methods by utilizing Total Variation Distance instead of the more common Kullback-Leibler (KL) Divergence. KL Divergence, and other f-divergences, can be sensitive to distribution mismatch and may not accurately reflect the degree of dissimilarity between in-distribution and OOD data. As detailed in table 3, TV-OOD, leveraging Total Variation Distance – a metric measuring the maximum difference between the cumulative distribution functions of two probability distributions – consistently achieves superior performance compared to methods based on alternative f-divergences in OOD detection benchmarks. This suggests that Total Variation Distance provides a more robust and reliable measure of distributional difference for identifying OOD samples.
Benchmarking Against the Baseline
TV-OOD’s performance was benchmarked against the baseline method BEOE across multiple datasets and network architectures to ensure comprehensive evaluation. Experiments utilized DenseNet121, WideResNet, and ViT-B_16 models. This comparative analysis was conducted to establish the relative effectiveness of TV-OOD in out-of-distribution (OOD) sample detection, accounting for variations in model capacity and feature extraction approaches. The chosen architectures represent a range of convolutional and transformer-based designs commonly used in image classification tasks, providing a robust assessment of TV-OOD’s generalizability.
Auxiliary Out-of-Distribution (OOD) datasets were generated to strengthen the reliability of experimental results. These datasets were created through the application of several image augmentation techniques, specifically AugMix, CutMix, and OpenGAN. AugMix employs a sequence of data augmentation operations to create diverse samples, while CutMix generates new images by combining parts of existing images. OpenGAN utilizes generative adversarial networks to produce synthetic images. The inclusion of these artificially generated OOD samples alongside natural OOD datasets increases the variability of the evaluation process and provides a more comprehensive assessment of OOD detection capabilities.
Quantitative analysis demonstrates that the TV-OOD method consistently achieves superior performance in out-of-distribution (OOD) sample detection when compared to the BEOE baseline. Specifically, experimental results, detailed in table 1, indicate that TV-OOD exhibits both improved accuracy and a higher Area Under the Receiver Operating Characteristic curve (AUROC) score across multiple datasets and network architectures, including DenseNet121, WideResNet, and ViT-B_16. These metrics collectively demonstrate TV-OOD’s enhanced capability to accurately identify samples that deviate from the training distribution.
The implementation of the Da_aug auxiliary out-of-distribution (OOD) dataset resulted in performance gains for both the TV-OOD and BEOE models when utilizing the DenseNet121 architecture. This indicates that augmenting the training data with samples generated via Da_aug improves the models’ ability to generalize and accurately identify OOD inputs, regardless of the primary OOD detection method employed. The observed enhancement suggests that Da_aug provides a beneficial signal for improved OOD discrimination when paired with DenseNet121, contributing to more robust and reliable performance in real-world scenarios.
Beyond Detection: Towards Resilient AI
The pursuit of reliable machine learning extends beyond achieving high accuracy on training data; it demands resilience when confronted with real-world scenarios exhibiting unexpected variations. TV-OOD-a novel approach to out-of-distribution (OOD) detection-directly addresses this critical need by identifying inputs that deviate significantly from the data used to train the system. This proactive identification isn’t simply about flagging anomalies, but rather about preventing potentially unsafe or incorrect decisions. By quantifying the ‘transportation variance’ between input data and the training distribution, TV-OOD offers a robust metric for assessing data novelty. Consequently, machine learning systems equipped with this capability can either request human intervention or conservatively abstain from making predictions when presented with unfamiliar data, thereby enhancing both safety and overall system trustworthiness in complex, dynamic environments.
The capacity of TV-OOD to maintain performance amidst distribution shifts proves especially advantageous in fields grappling with unpredictable data. Applications like autonomous vehicles, where encountering novel scenarios is inherent, benefit from a system less prone to errors when faced with previously unseen conditions – a pedestrian with an unusual object, for example, or an unexpected road configuration. Similarly, in medical imaging, where variations in patient anatomy, imaging techniques, and disease presentation are commonplace, the method’s resilience to data novelty offers the potential for more reliable diagnoses and reduced instances of false positives or negatives, ultimately improving patient care. This adaptability suggests a powerful tool for enhancing the safety and dependability of AI systems operating in dynamic, real-world contexts.
Continued development of the TV-OOD methodology centers on broadening its applicability to increasingly intricate data types, moving beyond current limitations to encompass modalities such as video, 3D point clouds, and multi-spectral imagery. Researchers are also actively investigating synergistic combinations of TV-OOD with complementary out-of-distribution (OOD) detection strategies; for example, integrating TV-OOD’s strengths in novelty detection with techniques focused on uncertainty estimation or adversarial robustness. This pursuit of integration aims to create a more comprehensive and resilient OOD detection framework, ultimately enhancing the safety and reliability of AI systems operating in unpredictable, real-world scenarios and paving the way for more trustworthy machine learning applications.
The development of TV-OOD anticipates a significant shift in the architecture of reliable artificial intelligence. Rather than treating out-of-distribution (OOD) detection as a supplementary feature, this method proposes its integration as a core component of AI system design. By proactively identifying and mitigating the risks associated with novel, unseen data, TV-OOD aims to establish a baseline for trustworthy performance across diverse and unpredictable real-world scenarios. This foundational approach promises to enhance the resilience of machine learning models, fostering greater confidence in their deployment within critical applications and ultimately paving the way for more dependable and safe AI technologies.
The pursuit of elegant solutions in out-of-distribution (OOD) detection, as explored in this paper with its Total Variation estimation, feels predictably optimistic. It’s a familiar cycle: a novel approach-replacing KL divergence with total variation distance-is proposed with the intention of streamlining image classification. However, one suspects production systems will inevitably reveal edge cases the researchers hadn’t accounted for. As Fei-Fei Li once noted, “The most dangerous thing is to assume everything is solvable.” This paper, in its attempt to refine OOD detection, simply creates a new, potentially more complex form of tech debt. The core idea of leveraging total variation feels neat until confronted with the messy reality of real-world data and unforeseen distributions.
What Comes Next?
The substitution of KL divergence with total variation estimation, as demonstrated by this work, feels less like a breakthrough and more like a predictable course correction. Every elegant information-theoretic construct eventually encounters the blunt reality of production data. The initial gains are encouraging, certainly, but the underlying problem – defining ‘distribution’ in a world that delights in novelty – remains stubbornly unresolved. Expect diminishing returns as edge cases accumulate, and the definition of ‘out-of-distribution’ itself becomes increasingly fluid.
Future work will inevitably focus on adaptive thresholds and ensemble methods, attempting to patch the inevitable leaks in this, and all other, OOD detection schemes. Perhaps more fruitful avenues lie in abandoning the pursuit of a perfect ‘in’ versus ‘out’ dichotomy. Instead, research might explore quantifying the degree of distributional shift, offering a more nuanced signal for downstream tasks. The ideal scenario isn’t flagging anomalies, but gracefully degrading performance in their presence.
It’s a reasonable bet that this approach, like its predecessors, will eventually become a legacy component, a memory of better times. Bugs, after all, are merely proof of life. The real challenge isn’t building a perfect detector, but accepting that, ultimately, one doesn’t fix production – one simply prolongs its suffering.
Original article: https://arxiv.org/pdf/2601.15867.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Spotting the Loops in Autonomous Systems
- Gold Rate Forecast
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Silver Rate Forecast
- The Best Directors of 2025
- Transformers Under the Microscope: What Graph Neural Networks Reveal
2026-01-26 05:51