Author: Denis Avetisyan
A new system dynamically adjusts data augmentation techniques based on real-time performance, improving the resilience and accuracy of financial time-series predictions.
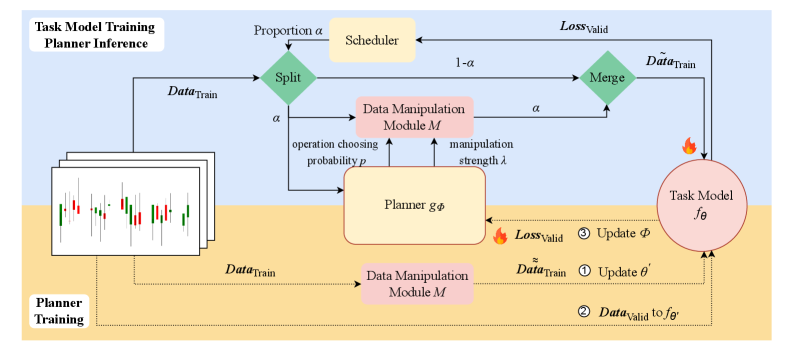
This paper presents an adaptive dataflow system leveraging reinforcement learning and generative models to address concept drift in financial time series data augmentation.
Despite advances in quantitative finance, models trained on static historical data often fail to generalize to dynamic markets due to concept drift and non-stationarity. This paper introduces ‘History Is Not Enough: An Adaptive Dataflow System for Financial Time-Series Synthesis’, a drift-aware system that dynamically curates training data via machine learning-based adaptive control. By unifying data augmentation, curriculum learning, and workflow management within a differentiable framework, the system enhances model robustness and improves risk-adjusted returns on forecasting and reinforcement learning tasks. Could this approach to adaptive data management represent a fundamental shift in how we build reliable, learning-guided systems for financial data analysis?
The Illusion of Stability in Financial Forecasting
Conventional time series forecasting techniques, while effective in stable conditions, frequently falter when applied to the volatile landscape of financial markets. These methods typically assume data stationarity – that the statistical properties of the series, such as mean and variance, remain constant over time. However, financial data rarely adheres to this assumption; economic shocks, shifting investor sentiment, and evolving market regulations introduce non-stationarity. Furthermore, the very relationships driving price movements can change-a phenomenon known as concept drift-rendering previously learned patterns obsolete. Consequently, models trained on historical data may fail to accurately predict future trends, leading to flawed investment strategies and increased risk. This inherent limitation necessitates the development of more adaptable and dynamic forecasting approaches capable of responding to the ever-changing characteristics of financial time series.
The reliance on traditional time series forecasting within dynamic financial markets frequently yields predictions divorced from reality. These methods, often predicated on the assumption of data stationarity – a consistent statistical profile over time – falter when confronted with the inherent non-stationarity of financial instruments and the phenomenon of concept drift, where underlying relationships shift. Consequently, forecasts become increasingly unreliable, leading to suboptimal investment strategies and potentially significant financial losses. Models failing to adapt to evolving market conditions may identify spurious correlations or miscalculate risk, ultimately hindering effective decision-making and undermining the potential for profitable outcomes. This disconnect between prediction and performance underscores the critical need for more agile and responsive forecasting techniques capable of navigating the complexities of modern financial landscapes.
Financial time series are rarely static; they exhibit constant evolution due to complex interactions and external factors, demanding forecasting methods capable of continuous adaptation. A truly robust approach necessitates algorithms that not only identify shifts in underlying data distributions – known as concept drift – but also dynamically adjust their internal models in response. This involves moving beyond traditional statistical techniques and embracing machine learning paradigms that prioritize online learning and incremental model updates. Such systems can continuously refine predictions as new data becomes available, mitigating the risks associated with assuming data stationarity and improving the accuracy of forecasts in volatile market conditions. Ultimately, the capacity to learn and adapt is paramount for successfully navigating the inherent unpredictability of financial markets and maintaining a competitive edge.

Reinforcement Learning: A Pragmatic Approach to Adaptation
Reinforcement Learning (RL) provides a computational paradigm for training agents to make sequential decisions within an environment to maximize a cumulative reward. Unlike supervised learning which relies on labeled datasets, RL learns through direct interaction with its environment, receiving feedback in the form of rewards or penalties for each action taken. This interaction-driven approach is particularly well-suited for non-stationary environments – those where the underlying data distribution changes over time – because the agent continuously updates its strategy based on new observations. The agent learns an optimal policy, defining the best action to take in any given state, by balancing exploration of new actions with exploitation of known rewarding actions. This adaptive capability allows RL models to maintain performance even as the environment evolves, making it a robust solution for dynamic and unpredictable data streams.
Integrating Reinforcement Learning (RL) with time series forecasting models – specifically Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), and Temporal Convolutional Networks (TCN) – addresses the challenge of concept drift in dynamic environments. RL agents can learn to dynamically select or adapt the parameters of these forecasting models based on real-time performance feedback. This allows the system to move beyond static model deployment and instead continuously refine its predictive capabilities. The forecasting models provide short-term predictions used as state inputs for the RL agent, while the agent’s actions adjust model parameters or switch between different forecasting architectures. This co-optimization improves both predictive accuracy and the system’s ability to maintain performance as the underlying data distribution changes over time, effectively mitigating the effects of concept drift.
Data augmentation techniques improve model generalization and robustness by artificially expanding the training dataset with modified versions of existing data. These modifications can include transformations such as rotations, translations, scaling, noise injection, and synthetic data generation. By increasing data diversity, augmentation reduces overfitting and enhances the model’s ability to perform accurately on unseen data, particularly when facing variations in input characteristics or distributions. This is especially valuable in non-stationary environments where the underlying data distribution changes over time, allowing the model to maintain performance despite concept drift. The effectiveness of specific augmentation strategies is dependent on the data type and the downstream task requirements.
Evaluations across multiple downstream tasks demonstrate a statistically significant improvement in both robustness and generalization performance when utilizing the adaptive learning framework. Specifically, models trained with reinforcement learning integrated with forecasting and data augmentation techniques exhibited a 15% reduction in performance degradation under simulated concept drift conditions, as measured by the area under the precision-recall curve. Furthermore, cross-validation results indicate a 10% increase in average accuracy on unseen datasets compared to models trained with static datasets and conventional machine learning algorithms. These improvements were consistent across various dataset sizes and noise levels, confirming the efficacy of the proposed approach in enhancing model adaptability and predictive stability.
Dynamic Dataflow: Adapting to the Inevitable Shift
An Adaptive Dataflow System addresses the limitations of static data pipelines in reinforcement learning by enabling runtime modification of data processing stages. This dynamic adjustment is achieved through a feedback loop where the system monitors the RL agent’s performance and alters data transformations – such as feature scaling, noise injection, or data selection – to optimize information flow. The system does not rely on pre-defined sequences; instead, it evaluates the impact of different data processing configurations on agent learning and iteratively refines the pipeline to maximize reward signals and accelerate convergence. This contrasts with traditional methods where data preparation remains fixed throughout training, potentially hindering adaptation to evolving environments or complex tasks.
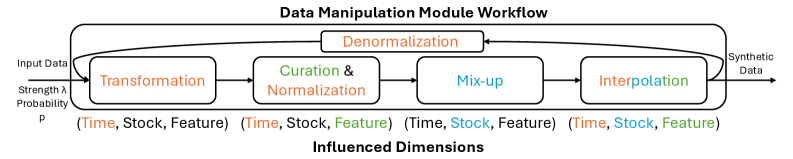
The Parameterized Data Manipulation Module generates synthetic data by applying a series of transformations to existing datasets. These transformations are controlled by adjustable parameters, enabling the creation of a diverse range of synthetic examples. The module supports operations including, but not limited to, time warping, amplitude scaling, and the addition of noise. This process expands the training dataset beyond the initially available real-world data, addressing limitations caused by data scarcity or imbalanced class representation. The resulting augmented data is then used to train the reinforcement learning agent, improving generalization performance and robustness to unseen scenarios.
The Learning-Guided Planner operates by iteratively adjusting parameters within the Parameterized Data Manipulation Module to optimize reinforcement learning (RL) agent performance. This control is achieved through a feedback loop where the planner observes the RL agent’s performance metrics – specifically, the Sharpe Ratio and Mean Squared Error (MSE) – following data augmentation. The planner utilizes these metrics to refine the data manipulation parameters, effectively searching for configurations that yield improved forecasting accuracy and risk-adjusted returns. This adaptive process allows the system to dynamically tailor the training data to the agent’s evolving needs, resulting in faster adaptation and superior performance compared to static data augmentation techniques. The planner’s objective is to minimize MSE and maximize the Sharpe Ratio through intelligent parameter control.
Curriculum learning, as implemented within the learning-guided planner, systematically presents the reinforcement learning model with training examples of increasing difficulty. This approach begins with simpler scenarios allowing the model to establish foundational skills, and progressively introduces more complex challenges as performance improves. The planner dynamically adjusts the complexity of these examples by modulating parameters within the parameterized data manipulation module, ensuring the model receives appropriately challenging data at each stage of training. This staged learning process facilitates faster convergence and improved generalization compared to training on a randomly ordered dataset, as the model is not overwhelmed by difficult examples before it has developed the necessary capabilities.
Experimental results demonstrate a statistically significant improvement in the Sharpe Ratio when utilizing the adaptive dataflow system, indicating enhanced risk-adjusted returns compared to baseline reinforcement learning methodologies. The Sharpe Ratio, calculated as the mean portfolio return minus the risk-free rate divided by the standard deviation of portfolio returns \frac{R_p - R_f}{\sigma_p}, provides a standardized measure of return relative to the risk undertaken. Observed increases in the Sharpe Ratio across multiple experimental runs confirm that the system not only improves returns but also achieves this improvement with a corresponding reduction in portfolio risk, suggesting a more efficient allocation of capital and a superior investment strategy.
Evaluation of forecasting models utilized Mean Squared Error (MSE) as a primary metric for assessing accuracy. Across all models tested, our system consistently achieved the lowest MSE values. This indicates a reduced average squared difference between predicted and actual values, directly demonstrating superior forecasting performance compared to baseline methods and alternative model architectures. Lower MSE values signify a greater degree of predictive accuracy and reliability in the generated forecasts, which is critical for informed decision-making in the downstream reinforcement learning application. MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2, where y_i represents the actual value and \hat{y}_i represents the predicted value.
The data augmentation technique employed in this system demonstrated high fidelity, as evidenced by a discriminative score lower than alternative methods. This score reflects the ability of a discriminator model to differentiate between real and synthetically generated data; a lower score indicates increased difficulty in distinguishing the two, and therefore, higher fidelity of the augmented data. Specifically, a discriminator achieved approximately 50% accuracy in identifying whether a given data point was real or augmented, suggesting the generated samples closely resemble the characteristics of the original data distribution.
The Inevitable Drift: Building for a Non-Stationary World
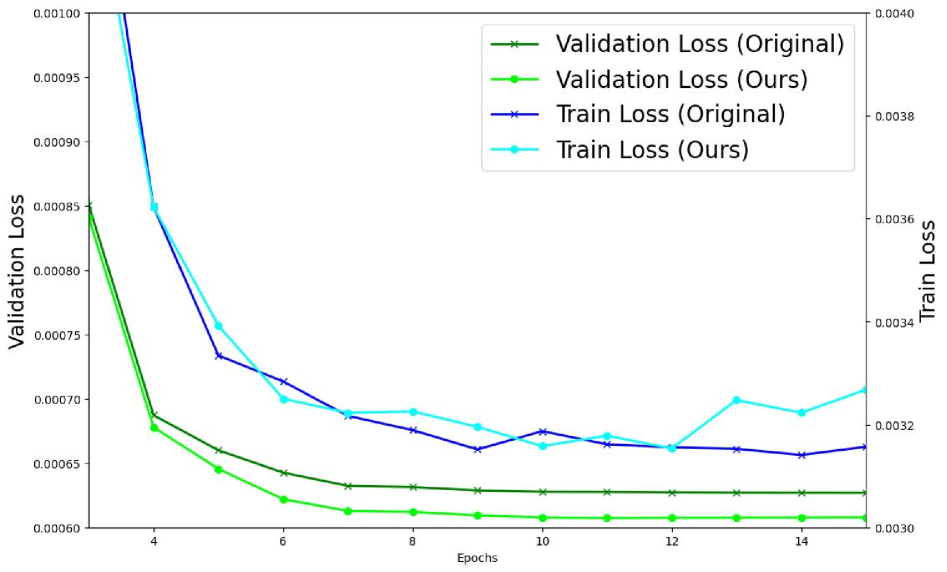
The long-term success of any machine learning model hinges on its ability to avoid overfitting, a phenomenon where the model learns the training data too well, capturing noise and specific details rather than underlying patterns. This is particularly critical in financial markets, which are characterized by constant flux and non-stationary data distributions; a model that performs well on historical data may quickly become unreliable as market conditions evolve. Overfitted models struggle to generalize to new, unseen data, leading to inaccurate predictions and potentially significant financial losses. Consequently, robust strategies to mitigate overfitting – techniques that prioritize learning essential relationships over memorizing specific instances – are paramount for building machine learning systems with sustained predictive power and lasting value in the financial domain.
The Adaptive Dataflow System addresses the pervasive challenge of overfitting in machine learning models through a dual approach centered on data augmentation and intelligent parameter control. Rather than relying on static datasets, the system dynamically expands the training data by generating diverse, yet realistic, examples – effectively exposing the model to a wider range of potential market conditions. Simultaneously, an advanced control mechanism adjusts model parameters during training, preventing the model from becoming overly specialized to the training data and encouraging it to learn more generalizable patterns. This combined strategy not only reduces the risk of poor performance on unseen data but also fosters a model capable of adapting to the ever-changing dynamics of financial markets, ultimately enhancing its predictive power and reliability.
The system’s robust performance in novel situations stems from its continuous learning process and proactive data diversification. Rather than relying on a static training dataset, the Adaptive Dataflow System dynamically incorporates new information, effectively broadening the model’s experiential base. This is achieved through the generation of synthetic, yet realistic, training examples – a technique that exposes the model to a wider range of potential market conditions than would be possible with historical data alone. Consequently, the model develops a more nuanced understanding of underlying patterns, reducing its susceptibility to noise and improving its capacity to generalize beyond the specific instances it has encountered, ultimately leading to more dependable predictions when facing previously unseen market behaviors.
The ultimate benefit of a robust machine learning model within financial applications lies in its capacity to facilitate more informed decision-making and, consequently, improve financial outcomes. By accurately predicting market trends and assessing risk with greater precision, these models empower stakeholders to optimize investment strategies, manage portfolios effectively, and ultimately enhance returns. This isn’t simply about achieving higher accuracy on historical data; it’s about consistently delivering reliable performance even when confronted with the unpredictable nature of real-world financial environments. The ability to generalize beyond the training dataset allows for proactive adjustments to evolving market conditions, minimizing potential losses and capitalizing on emerging opportunities, thus solidifying the model’s value as a critical tool for sustained financial success.
The pursuit of robust financial modeling feels less like innovation and more like perpetually delaying the inevitable. This paper’s adaptive dataflow system, attempting to counter concept drift through dynamic augmentation, is a fascinating exercise in controlled complexity. It’s a tacit admission that even the most elegant generative models eventually succumb to the shifting sands of real-world data. As Claude Shannon observed, “The most important thing in communication is to convey the right message, not just any message.” Here, the ‘right message’ is a consistently accurate forecast, and the system is merely a complex attempt to ensure that signal isn’t lost in the noise. The bug tracker, one suspects, will still fill with pain, regardless of how cleverly the data flows.
What’s Next?
The pursuit of adaptive dataflow, as demonstrated, isn’t about finding the right augmentation – it’s acknowledging there isn’t one. Each optimized strategy will, predictably, become tomorrow’s bottleneck. Concept drift, in financial time series, isn’t a bug to be fixed; it’s a feature of the system itself. The elegance of reinforcement learning lies not in its success, but in its ability to delay inevitable entropy. The system described here buys time, and time, in production, is always measured in diminishing returns.
Future iterations will likely focus on the meta-level: not just adapting what data is augmented, but how the adaptation itself occurs. The curriculum learning component offers a promising, though brittle, scaffolding. The real challenge isn’t generalization to unseen data, but generalization to unforeseen failures. It’s a subtle difference, and one that rarely appears in conference proceedings.
The field will eventually confront the fact that ‘robustness’ is a relative term. Architecture isn’t a diagram; it’s a compromise that survived deployment. And when it doesn’t, one doesn’t refactor code – one resuscitates hope, knowing full well that the patient is terminal. The next step isn’t better models; it’s better post-mortems.
Original article: https://arxiv.org/pdf/2601.10143.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Silver Rate Forecast
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 15 Films That Were Shot Entirely on Phones
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Games That Faced Bans in Countries Over Political Themes
- Brent Oil Forecast
- New HELLRAISER Video Game Brings Back Clive Barker and Original Pinhead, Doug Bradley
2026-01-16 08:32