Author: Denis Avetisyan
Researchers are applying principles from probability theory to reshape how large language models generate text, aiming for more efficient and reliable reasoning.
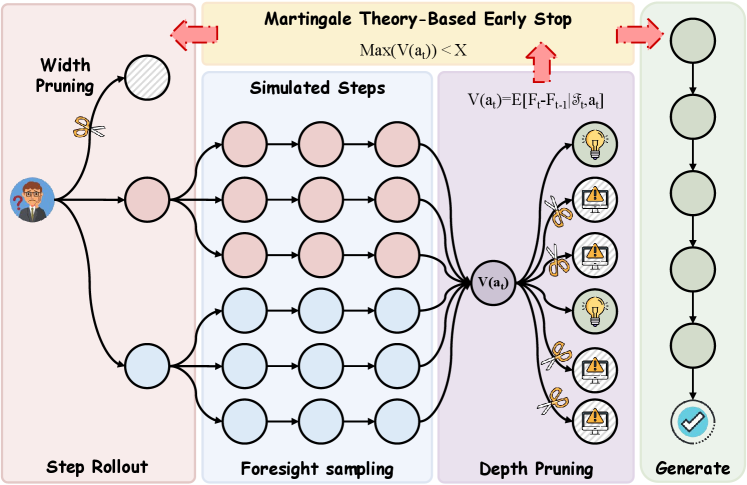
This work introduces Martingale Foresight Sampling, a decoding framework grounded in optimal stopping theory and Doob decomposition for improved LLM performance.
Autoregressive decoding in large language models, while powerful, often struggles with complex reasoning due to its myopic, token-by-token approach. This limitation motivates the development of more globally aware inference strategies, and we introduce ‘Martingale Foresight Sampling: A Principled Approach to Inference-Time LLM Decoding’, a novel framework that reformulates LLM decoding as the problem of identifying an optimal stochastic process. By leveraging Martingale theory-specifically the Doob Decomposition Theorem and Optional Stopping Theory-we design an algorithm that values reasoning paths based on predictable advantage and prunes suboptimal candidates with theoretical guarantees. Does this principled approach to foresight sampling unlock a new era of robust and efficient reasoning in large language models?
The Illusion of Fluency: Beyond Token Prediction
Large Language Models (LLMs) demonstrate remarkable proficiency in predicting the subsequent token within a sequence, a capability that underpins their fluency in generating human-like text. However, this strength belies a significant weakness when confronted with tasks demanding complex, multi-step reasoning. While adept at identifying immediate patterns and continuations, LLMs struggle to maintain coherence and accuracy across extended problem-solving processes. This isn’t a matter of insufficient data, but a fundamental limitation in their architecture; they excel at local prediction but lack the capacity for global planning or anticipating the consequences of each step within a larger, interconnected chain of thought. Consequently, even seemingly simple reasoning problems can expose this fragility, leading to errors that highlight the difference between statistical mimicry and genuine cognitive ability.
The fundamental constraint facing Large Language Models lies in what researchers now define as ‘Myopic Decoding’ – a tendency to focus intensely on immediate textual coherence at the expense of broader contextual understanding. These models, optimized for predicting the subsequent word or token, essentially operate with a limited foresight, failing to effectively plan or anticipate the ramifications of their outputs beyond the very next step. This isn’t a matter of insufficient data; rather, it’s an architectural limitation where the pursuit of local accuracy overshadows global consistency and logical progression. Consequently, even impressively fluent text can quickly unravel when presented with tasks requiring sustained reasoning, strategic thinking, or the consideration of distant consequences, highlighting a crucial gap between statistical proficiency and genuine comprehension.
Current attempts to enhance Large Language Model reasoning, such as ‘Step-by-Step Reasoning’, often present a limited solution to a fundamental architectural challenge. While these techniques encourage models to articulate intermediate reasoning stages, they largely function as a post-hoc adjustment rather than addressing the core issue of myopic decoding. The model still fundamentally operates by predicting the most probable next token, even when prompted to generate reasoning steps; it doesn’t genuinely plan or anticipate consequences beyond the immediate prediction. Consequently, performance improvements gained through step-by-step prompting frequently plateau, particularly on tasks requiring extensive foresight or complex strategy, indicating that substantial progress demands modifications to the underlying model architecture-a move beyond simply influencing the decoding process to fundamentally altering how the model represents and processes information.
The Ecosystem of Thought: Reasoning as Search
Tree-of-Thought (ToT) builds upon step-by-step reasoning by representing the problem-solving process as a search within a decision tree. Unlike methods that generate a single sequence of tokens, ToT allows the model to explore multiple reasoning paths concurrently. At each step, the model doesn’t simply predict the next token but instead generates several potential continuations – “thoughts” – forming branches in the tree. These thoughts are then evaluated based on a defined criteria, and the most promising branches are expanded further, enabling the model to consider diverse possibilities and backtrack if necessary. This branching exploration differentiates ToT from sequential methods and allows for more complex reasoning and problem-solving.
Foresight Sampling builds upon Tree-of-Thought reasoning by incorporating a forward-looking evaluation component. Rather than solely assessing the immediate result of a reasoning step, this method simulates multiple potential future sequences stemming from that step. By ‘peering into the future’ and estimating the value of these simulated outcomes – often using a reward function or heuristic – the system can prioritize steps predicted to lead to more desirable end states. This allows for a more informed search through the decision tree, as each step is not just judged on its own merit, but on its projected long-term impact on solving the overall problem. The number of simulated futures, and the depth of those simulations, are configurable parameters impacting computational cost and the quality of the foresight evaluation.
Traditional language models operate by predicting the next token in a sequence, a process focused on immediate continuation. Tree-of-Thought and Foresight Sampling represent a departure from this approach, re-framing problem-solving as a deliberate search process. Instead of solely generating the most probable subsequent token, these methods explore multiple potential reasoning paths – represented as nodes in a decision tree – and evaluate their potential to lead to a successful outcome. This involves assessing the value of each step not just in terms of its immediate plausibility, but also its projected impact on the overall solution, effectively prioritizing exploration over simple continuation.
The Mathematics of Prediction: A Formal Framework
Martingale theory, originating in probability theory, provides a formal system for analyzing sequential decision-making processes under uncertainty, and is increasingly relevant to Large Language Model (LLM) decoding. A stochastic process is defined as a martingale if, given all prior observations, the expected value of the next observation is equal to the current value; mathematically, E[X_{t+1} | X_1, ..., X_t] = X_t . In the context of LLMs, this can be applied to the cumulative log-probabilities assigned to generated tokens; if the expected future log-probability, conditional on the current sequence, remains equal to the current cumulative log-probability, the process is a martingale. This property allows for rigorous analysis of decoding strategies and the development of algorithms that can effectively navigate the probabilistic nature of text generation, facilitating techniques for controlling and optimizing the decoding process beyond simple greedy approaches.
The Doob Decomposition Theorem states that a square-integrable martingale X_t can be uniquely decomposed into the sum of a predictable process Y_t and a local martingale Z_t, such that X_t = Y_t + Z_t. The predictable component Y_t represents the portion of the process that can be estimated based on past information, effectively capturing the deterministic trend. The local martingale Z_t represents the unpredictable, random fluctuations. This decomposition is crucial because it allows for the isolation and separate analysis of the predictable and unpredictable components of an LLM’s decoding process, facilitating more precise evaluation of future trajectory probabilities and improved decision-making during search algorithms like beam search.
Optional Stopping Theory provides a formal basis for determining when to terminate exploration of a given path within a Beam Search algorithm. This theory establishes conditions under which sequentially constructed random variables – in this case, the log-probabilities of generated tokens – converge, or fail to converge, allowing for the identification of suboptimal paths that are unlikely to yield improved results. By defining a stopping time – a rule for when to cease extending a particular beam – and satisfying the conditions of the theorem, the search can be pruned, discarding paths that offer diminishing returns. This principled pruning, based on mathematical guarantees, directly maximizes the efficiency of the Beam Search by focusing computational resources on more promising candidates, without introducing bias or sacrificing optimality.
The System in Action: MFS and Principled Search
The Martingale Foresight Sampling (MFS) algorithm operationalizes a theoretical framework by integrating predictive foresight with the mathematical principles of martingale theory. This approach allows for the dynamic evaluation of potential reasoning paths, assigning values based on predicted outcomes and rigorously controlling the exploration process. By leveraging martingale convergence theorems, MFS ensures the algorithm will ultimately converge towards an optimal solution. The core implementation relies on assessing the expected change in value at each step, enabling the algorithm to prioritize paths demonstrating a sustained, predictable advantage and effectively prune those that do not.
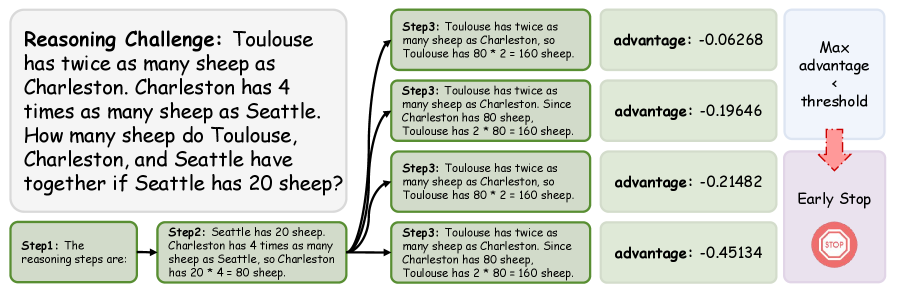
The Martingale Foresight Sampling (MFS) algorithm employs ‘Predictable Advantage’ and the ‘Deficit Process’ to assess and eliminate unproductive search paths during reasoning. Quantitative analysis reveals a consistent performance differential: correct reasoning paths exhibit a predictable advantage ranging from -0.458 to -0.458, while incorrect paths demonstrate a significantly lower advantage, ranging from -1.027 to -1.027. This difference in predictable advantage serves as a key metric for dynamic pruning, allowing the algorithm to prioritize and explore more promising reasoning sequences based on quantifiable performance indicators.
The Martingale Convergence Theorem provides a performance guarantee for the MFS algorithm by mathematically ensuring convergence to an optimal solution as the search progresses. This convergence is empirically supported by observed differences in variance along reasoning paths; correct paths demonstrate a significantly lower variance in step values (0.249) compared to incorrect paths (0.994). This disparity in variance indicates that correct reasoning consistently produces more predictable and stable outcomes, while incorrect paths exhibit greater instability and unpredictability, contributing to the algorithm’s ability to effectively prune suboptimal search branches.
Beyond Imitation: A Future of Genuine Reasoning
Modern foundation models (MFMs) are extending the boundaries of artificial intelligence by systematically incorporating foresight into a mathematically rigorous framework. This isn’t merely about predicting the next word, but about enabling large language models to anticipate the consequences of actions and reason through complex scenarios. By grounding reasoning in formal methods, MFS moves beyond pattern recognition to genuine problem-solving. The system leverages mathematical principles to evaluate potential outcomes, allowing the model to select the most advantageous path toward a defined goal. This integration of foresight and mathematical rigor facilitates a significant leap in reasoning depth, allowing MFMs to tackle challenges requiring strategic planning and long-term consideration-capabilities previously unattainable through purely statistical approaches. φ-Decoding, a key component, uses this enhanced reasoning to consistently generate solutions with measurable quality.
ϕ-Decoding introduces a novel evaluation framework centered on ‘Alignment Score’ and ‘Advantage Score’ to rigorously assess the quality of solutions generated by large language models. The ‘Alignment Score’ quantifies how consistently a proposed solution adheres to the initial problem constraints and stated goals, effectively measuring logical coherence. Complementing this, the ‘Advantage Score’ determines whether a given solution demonstrably improves upon previous attempts or represents a genuinely beneficial step towards a desired outcome. These metrics, calculated during the decoding process, move beyond simple probabilistic text generation by providing a quantifiable measure of reasoning effectiveness; a higher score indicates not just grammatical correctness, but a solution that is both logically sound and strategically advantageous. This allows for a more discerning evaluation of LLM outputs, facilitating the development of AI systems capable of consistently generating reliable and well-reasoned responses.
This development signifies a move beyond the conventional limitations of large language models, which primarily focus on statistical pattern recognition to generate human-like text. Instead of merely predicting the next word, this approach establishes a framework for genuine reasoning – a system where AI actively pursues defined goals with logical consistency. By prioritizing principled reasoning, the technology moves towards solutions grounded in objective criteria, rather than probabilistic estimations. This fundamental shift promises not only more accurate and dependable outputs, but also a greater capacity for tackling complex, multi-step problems, ultimately fostering AI systems that are demonstrably more reliable and trustworthy in their decision-making processes.
The pursuit of efficient Large Language Model decoding, as detailed within this work, echoes a fundamental truth about complex systems. This paper’s framing of decoding as an optimal stopping problem – leveraging martingale theory to identify the most judicious moment for inference – isn’t about control, but about navigating inherent uncertainty. As Tim Berners-Lee observed, “Order is just cache between two outages.” The seemingly ordered output of an LLM is, in essence, a temporary state, a probabilistic arrangement poised to shift with each new input. This research doesn’t attempt to prevent chaos, but to understand the underlying stochastic processes, accepting that the best strategy isn’t to eliminate risk, but to adapt to it with principles of optimal stopping, thus enhancing robustness.
What Lies Ahead?
The framing of Large Language Model decoding as an optimal stopping problem, leveraging the machinery of martingale theory, is less a solution than a carefully constructed postponement of inevitable complexity. Long stability in perplexity metrics will, in time, reveal not mastery, but the precise contours of the next systemic failure. This work doesn’t offer a path to robust reasoning; it illuminates the shape of the wilderness where robustness is lost. The authors rightly identify the tension between exploration and exploitation, but the true challenge isn’t balancing these forces-it’s accepting that any static balance is illusory.
Future iterations will inevitably confront the limits of Doob decomposition when applied to the profoundly non-Markovian processes inherent in LLM state. The current approach, elegant as it is, addresses symptom, not cause. The focus should shift toward understanding how these models accumulate error-how local submartingale drifts compound into global incoherence. A complete theory will require not merely efficient decoding, but a formal account of the model’s evolving belief states-and the inevitable divergence from any ground truth.
The promise of “foresight” is a seductive one, but it is crucial to remember that systems do not fail-they evolve. The goal isn’t to prevent unexpected behavior, but to build architectures that reveal the shape of their own decay, offering legible pathways toward adaptation-or graceful collapse.
Original article: https://arxiv.org/pdf/2601.15482.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Spotting the Loops in Autonomous Systems
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- Silver Rate Forecast
2026-01-24 11:39