Author: Denis Avetisyan
A new reinforcement learning framework, Strategy-aware Surprise, encourages more effective exploration by focusing on shifts in an agent’s behavioral approach, not just novel states.
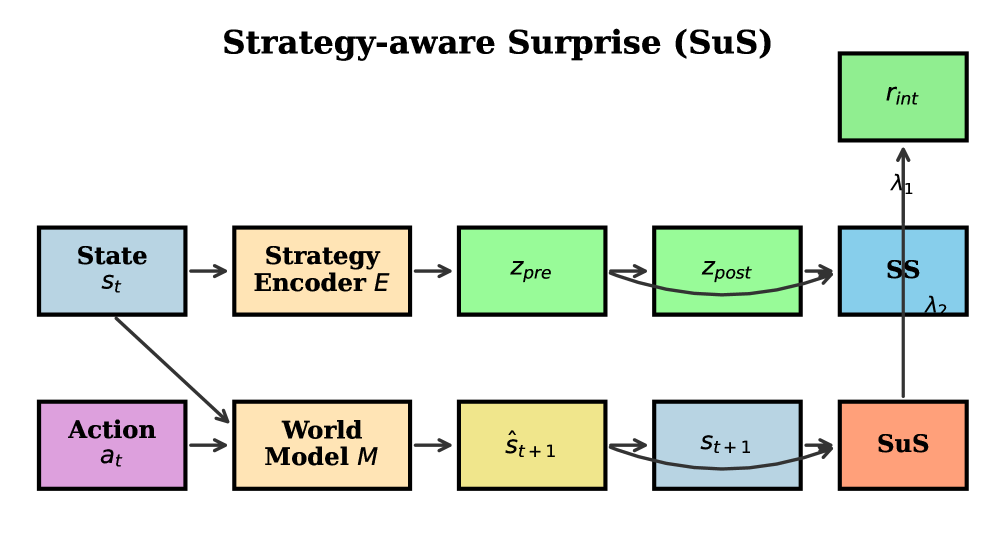
This work introduces a novel intrinsic motivation method that leverages strategy embeddings and contrastive learning to promote behavioral diversity and improve performance on complex tasks.
Effective exploration remains a core challenge in reinforcement learning, often hindered by agents getting stuck in local optima. This paper introduces ‘SuS: Strategy-aware Surprise for Intrinsic Exploration’, a novel intrinsic motivation framework that encourages behavioral diversity by rewarding changes in an agent’s learned strategy. By combining measures of strategy stability and surprise, SuS demonstrably improves performance on complex tasks like mathematical reasoning, achieving significant gains in both accuracy and solution diversity. Could this strategy-aware approach unlock more robust and adaptable agents capable of tackling even more challenging real-world problems?
The Sparse Reward Problem: A Fundamental Bottleneck
Traditional reinforcement learning algorithms frequently encounter difficulties when rewards are infrequent or sparse, fundamentally impacting the agent’s ability to explore its environment effectively. The core of successful learning lies in receiving feedback that guides the agent toward optimal actions; however, when positive reinforcement is rare, the agent struggles to differentiate beneficial behaviors from random ones. This presents a significant challenge because most real-world tasks, such as robotics or strategic game playing, do not provide constant, immediate rewards. Consequently, the agent may spend extended periods taking actions without receiving any signal, leading to slow learning or even complete failure to discover effective strategies. Addressing this sparsity problem is therefore crucial for expanding the applicability of reinforcement learning to more complex and realistic scenarios, necessitating the development of novel exploration techniques that can efficiently navigate environments with limited feedback.
Effective learning in reinforcement learning agents hinges on receiving informative feedback from their environment, yet many real-world scenarios present a stark challenge in this regard. Environments often deliver only infrequent or sparse rewards, meaning the agent receives little to no signal for extended periods of time. This poses a significant problem because agents rely on these signals to correlate actions with outcomes; without consistent feedback, discerning successful strategies from random behavior becomes exceedingly difficult. Consequently, the agent struggles to explore effectively, potentially missing crucial pathways to optimal performance, and highlighting the need for novel exploration strategies capable of thriving in the face of delayed or limited reinforcement.
The practical deployment of reinforcement learning algorithms faces considerable hurdles when tackling complex, real-world tasks due to the pervasive issue of sparse rewards. Environments demanding extended sequences of actions to achieve a goal-such as robotic manipulation, strategic game playing, or long-term resource management-often provide minimal feedback until the very end. This scarcity of intermediate signals severely restricts the agent’s ability to learn effectively, as it struggles to associate actions with their eventual consequences. Consequently, algorithms that perform well in simulated environments with dense rewards often falter when applied to these more realistic, yet challenging, scenarios. Overcoming this limitation is therefore crucial for expanding the reach of reinforcement learning beyond controlled settings and into domains requiring sophisticated long-term planning and decision-making.
Intrinsic Motivation: A Patch for the Exploration Problem
Intrinsic Motivation (IM) addresses the reward sparsity problem in Reinforcement Learning by supplementing external rewards with internally generated signals. These auxiliary rewards are not tied to task completion, but instead are derived from the agent’s own learning process and inherent curiosity. Specifically, IM systems quantify factors such as prediction error, state novelty, or information gain, and translate these metrics into reward signals. By rewarding the agent for exploring unfamiliar states or reducing uncertainty, IM encourages continued interaction with the environment and facilitates learning, even in the absence of immediate, externally defined goals. This approach allows agents to proactively acquire knowledge and build a more comprehensive understanding of their surroundings.
Intrinsic Motivation (IM) techniques encompass a variety of methodologies, prominently including count-based and prediction-based approaches. Count-based methods operate by rewarding agents for visiting previously unseen states, effectively incentivizing exploration of novel areas within an environment; state visitation counts are maintained and used as a proxy for novelty. Conversely, prediction-based methods utilize learned models of environmental dynamics; rewards are then generated based on the agent’s ability to accurately predict the consequences of its actions – higher prediction error corresponds to greater reward. Both approaches aim to provide an internal reward signal independent of external task goals, driving continued learning and exploration.
Intrinsic motivation techniques enable reinforcement learning agents to explore their environment and acquire knowledge without relying on externally defined rewards. By generating internal signals based on learning progress or novelty, these methods incentivize the agent to visit unfamiliar states and interact with previously unseen aspects of the environment. This is achieved by rewarding the agent for reducing prediction error, increasing its ability to accurately model the environment’s dynamics, or for encountering states that differ significantly from those previously observed, effectively driving autonomous exploration and skill acquisition even when no external task is specified.
Strategy Surprise: When Curiosity Gets Clever
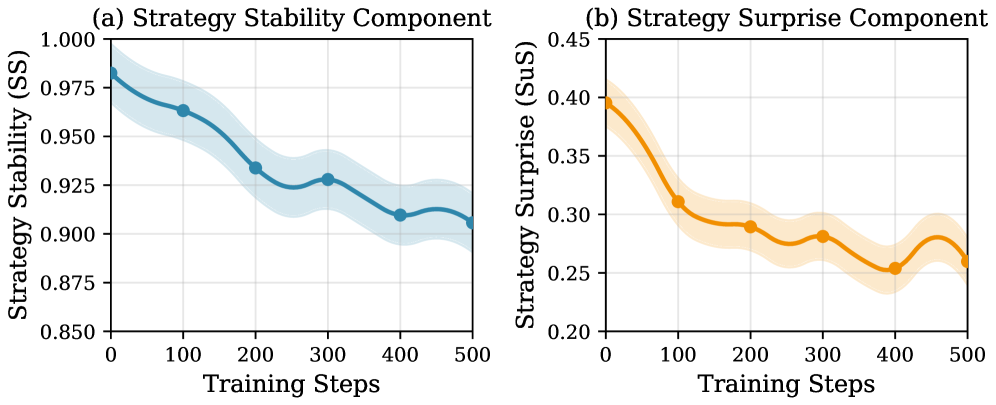
Strategy Surprise (SuS) represents a departure from traditional intrinsic motivation methods by directly addressing the prediction of an agent’s behavioral patterns, termed ‘strategies’. Rather than rewarding novelty as an end in itself, SuS focuses on the difference between predicted and observed outcomes. This is achieved by training a model to anticipate the agent’s actions given its current state and then providing a reward signal proportional to the prediction error. The underlying premise is that agents are inherently driven to reduce uncertainty about their own behavior, and thus, a reward for unexpected outcomes encourages exploration and the refinement of increasingly predictable – and therefore robust – strategies. This predictive approach distinguishes SuS from methods reliant on state visitation counts or similar measures of environmental novelty.
The Strategy Surprise (SuS) framework employs a Strategy Encoder, a neural network component, to compress high-dimensional observation data into a lower-dimensional latent space. This latent space represents the agent’s inferred behavioral strategies. The encoder’s output is then used to predict future outcomes; a reward signal is generated based on the discrepancy between the predicted outcome and the actual observed outcome. Specifically, larger discrepancies – indicating the agent executed a strategy that deviated from the encoder’s prediction – result in a positive reward, incentivizing the exploration of novel or unexpected behaviors. This reward mechanism is distinct from traditional reward structures and focuses on the surprise of the agent’s actions, rather than achieving a pre-defined goal.
Strategy Stability (SS) measurement functions as a key component in reinforcing the discovery of reliable behavioral patterns within the Strategy Surprise (SuS) framework. SS quantifies the consistency of an agent’s chosen strategy over time; higher stability scores indicate the agent is repeatedly executing the same strategy to achieve its goals. By rewarding agents not only for unexpected successes, but also for maintaining consistent strategic behavior – as indicated by high SS scores – the system incentivizes the refinement of strategies that demonstrably yield predictable and repeatable outcomes. This combination of rewarding both novelty and consistency leads to the emergence of robust and reliable behavioral patterns, improving performance and generalization capabilities.
Integrating a World Model with the Strategy Surprise (SuS) framework significantly enhances predictive accuracy by providing a learned representation of the environment’s dynamics. This allows the Strategy Encoder to operate on predicted states rather than raw observations, improving generalization and robustness to noisy or incomplete sensory input. The World Model facilitates more accurate prediction of future outcomes given a particular strategy, enabling a more precise reward signal for mismatches between predicted and actual results. Consequently, the agent receives stronger reinforcement for genuinely novel and effective strategies, accelerating learning and promoting the discovery of robust behavioral patterns beyond those immediately apparent from raw sensory data.
Validation on Mathematical Reasoning Tasks: A Glimmer of Intelligence
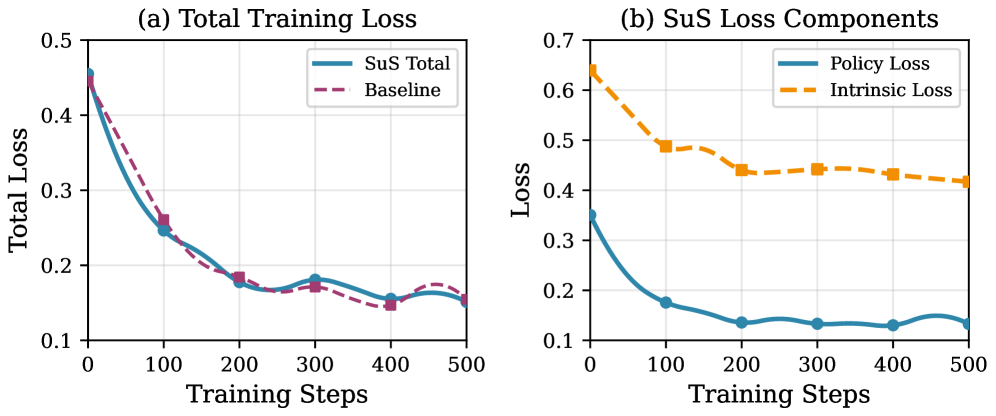
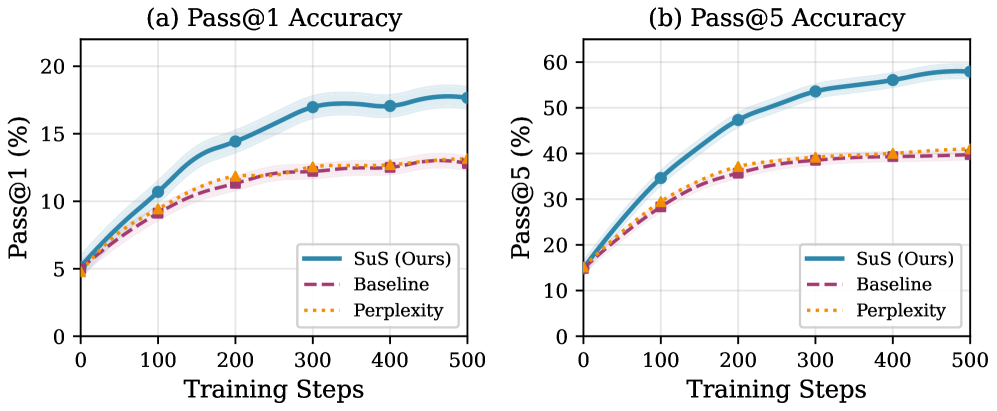
Application of this novel framework to mathematical reasoning tasks reveals a significant enhancement in agent performance. Evaluation through established metrics – Pass@1, which measures the probability of the correct answer being within the top prediction, and Pass@5, assessing correctness within the top five – demonstrates substantial gains. Specifically, agents employing this approach exhibit improved accuracy in solving complex mathematical problems, indicating a capacity to not only identify potential solutions but also to prioritize the most likely correct answer. This performance boost suggests the framework effectively equips agents with enhanced reasoning abilities, enabling them to navigate the challenges inherent in mathematical problem-solving with greater success.
Evaluations on mathematical reasoning tasks demonstrate a significant performance boost when utilizing the proposed framework. Specifically, the Strategy Surprise (SuS) component achieved a 17.4% relative improvement in Pass@1 accuracy – indicating a greater likelihood of selecting the correct answer on the first attempt – and a substantial 26.4% improvement in Pass@5 accuracy, which measures success when considering the top five predicted solutions. These gains, observed when contrasted with established baseline methods, underscore the effectiveness of SuS in navigating complex problem spaces and identifying viable solution pathways. The observed improvements suggest a more robust and efficient approach to mathematical reasoning within the agent, enhancing its ability to solve challenging problems.
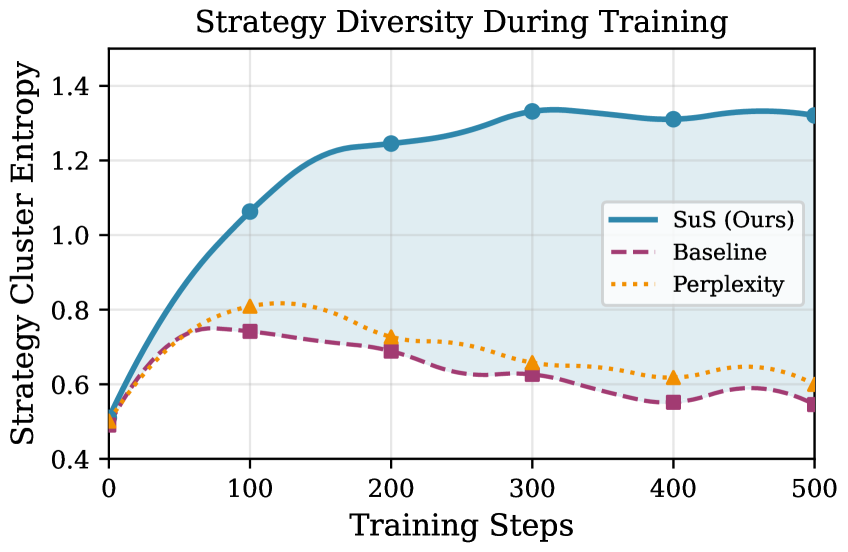
The architecture incorporates contrastive learning within its strategy encoder to refine the representation of an agent’s behavioral approaches. This technique doesn’t simply record what an agent does, but focuses on discerning why certain strategies are successful in specific contexts. By pulling together similar, high-reward strategies in the representation space while pushing apart those leading to failure, the encoder learns a more nuanced understanding of effective behavior. Consequently, the agent demonstrates improved predictive accuracy, allowing it to anticipate which strategies are most likely to yield positive results in novel situations and ultimately enhancing performance on complex mathematical reasoning tasks.
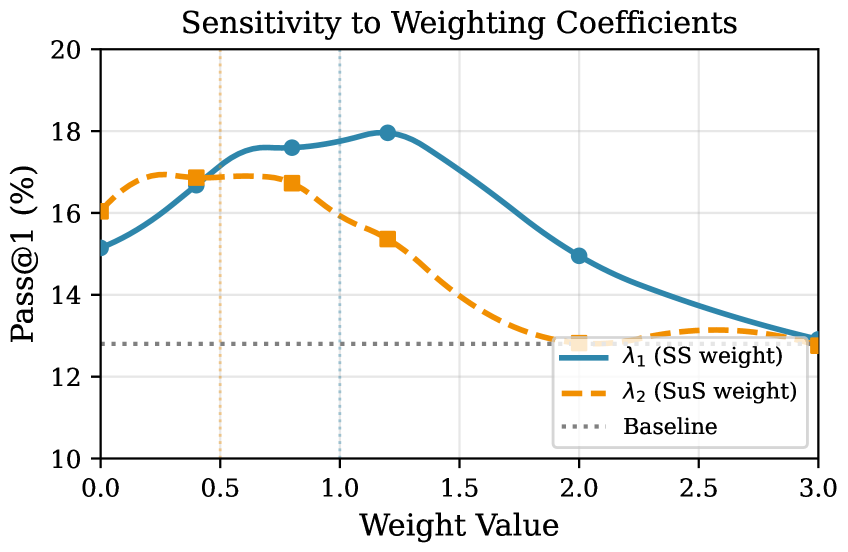
Ablation studies reveal the critical interplay between Strategy Stability and Strategy Surprise in achieving robust performance on mathematical reasoning tasks. Removing either component – the measure of consistent strategic approaches or the detection of novel, potentially beneficial behaviors – independently diminishes predictive accuracy by a substantial 12.0% as measured by Pass@5. This finding underscores that neither consistent application of known strategies nor the exploration of new approaches is sufficient in isolation; rather, a balance between exploiting established methods and embracing surprising, yet potentially superior, alternatives is essential for maximizing success in complex problem-solving scenarios. The combined presence of both signals appears crucial for effective behavioral representation and, consequently, improved agent performance.
The persistent challenge of exploration in complex, goal-directed tasks appears mitigated by leveraging intrinsic motivation, notably through the Strategy Surprise (SuS) mechanism. This approach doesn’t rely on external rewards, but instead encourages agents to seek out novel and unexpected behavioral strategies. Results indicate that by prioritizing the exploration of less-familiar approaches, agents can significantly improve their performance on mathematical reasoning tasks, discovering solutions that would likely be missed by purely reward-driven methods. The effectiveness of SuS is underscored by the marked decrease in accuracy observed when removed, suggesting its critical role in guiding exploration and ultimately enhancing problem-solving capabilities in environments demanding strategic thinking.
Towards Efficient and Scalable Agents: A Pragmatic Future
The development of scalable and efficient artificial agents is increasingly reliant on techniques that maximize the potential of large language models without incurring prohibitive computational costs. Fine-tuning models like Qwen2.5-1.5B using Low-Rank Adaptation (LoRA) adapters presents a compelling solution. LoRA operates by freezing the pre-trained model weights and introducing a smaller set of trainable parameters, significantly reducing the resources needed for adaptation to specific tasks. This parameter-efficient transfer learning approach allows agents to learn new skills and respond to diverse instructions without the need for extensive retraining of the entire model. Consequently, LoRA facilitates the creation of agents that are not only more computationally accessible but also more easily deployed and scaled across various applications, paving the way for more versatile and responsive AI systems.
Adapting large language models to specialized tasks traditionally demands substantial computational resources, often requiring the retraining of billions of parameters. However, parameter-efficient techniques like Low-Rank Adaptation (LoRA) offer a compelling alternative. LoRA freezes the pre-trained model weights and injects trainable low-rank matrices, significantly reducing the number of parameters that need adjustment for a new task. This approach not only accelerates the adaptation process but also minimizes the memory footprint, making it feasible to deploy customized language models on resource-constrained hardware. Consequently, LoRA unlocks the potential for creating a diverse range of specialized agents without incurring the prohibitive costs associated with full model retraining, paving the way for broader accessibility and scalability in artificial intelligence applications.
The integration of parameter-efficient fine-tuning with intrinsic motivation frameworks, such as SuS (Self-Supervised exploration with intrinsic rewards), represents a significant advancement in the development of adaptable artificial intelligence. By equipping agents with an internal drive to seek out novel and informative experiences, these systems move beyond reliance on external rewards and can proactively learn in complex, ever-changing environments. This approach allows agents to continuously refine their skills and knowledge without requiring constant human intervention or pre-defined training data, fostering a level of autonomy previously unattainable. The resulting agents demonstrate enhanced resilience and a greater capacity to generalize learning, opening doors to applications in fields demanding sustained performance in unpredictable settings – from robotic exploration to personalized education and beyond.
Continued research centers on optimizing the synergy between intrinsic motivation and large language models, anticipating substantial gains in agent autonomy and adaptability. Current efforts investigate methods for more effectively translating internally generated curiosity signals – the drive to explore novel or challenging situations – into actionable behaviors within the language model’s framework. This includes refining reward structures and exploration strategies to encourage agents to not only pursue intrinsically rewarding tasks but also to generalize learned skills to unforeseen circumstances. Ultimately, a deeper understanding of this interplay promises to move beyond task-specific performance, fostering agents capable of continuous self-improvement and robust operation in complex, ever-changing environments – potentially unlocking genuinely intelligent and versatile artificial systems.
The pursuit of truly intelligent agents, as highlighted by this work on Strategy-aware Surprise, inevitably runs headfirst into the brick wall of reality. The authors attempt to address behavioral diversity through strategy embeddings, a clever approach, but one shouldn’t mistake elegance for resilience. As Carl Friedrich Gauss observed, “If I speak for my own benefit, I may say that I have always been remarkably successful in mathematics, and that I have never known a moment of difficulty.” This sentiment applies here; the initial results are promising, but the inevitable edge cases and unforeseen production environments will undoubtedly expose the limitations of even the most carefully crafted intrinsic motivation framework. It’s a temporary victory, nicely packaged, until the next version of ‘reality’ is deployed.
The Road Ahead
The introduction of strategy embeddings as a signal for intrinsic motivation is… predictable. Any system that rewards change will eventually reward pointless oscillation. The true test isn’t mathematical reasoning-it’s how quickly SuS discovers novel ways to fail in production. If a bug is reproducible, it implies a stable, if suboptimal, system-a far more valuable outcome than elegant, brittle exploration.
The claim of improved behavioral diversity invites scrutiny. Diversity is a metric easily inflated by noise. A truly diverse agent would, presumably, also discover strategies that actively avoid the reward function. That, of course, isn’t measured. The current reliance on contrastive learning feels… optimistic. Anything self-healing just hasn’t broken yet.
Future work will undoubtedly focus on scaling these methods. More parameters, more data, more tasks. The real challenge, though, isn’t performance-it’s documentation. Because documentation is collective self-delusion. The inevitable architectural drift will render any current explanation obsolete, and the cycle will begin anew.
Original article: https://arxiv.org/pdf/2601.10349.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Brent Oil Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
2026-01-18 17:39