Author: Denis Avetisyan
Researchers have developed a new AI system that blends the power of large language models with curated human expertise to achieve expert-level performance in the complex game of Go.

A novel training paradigm integrates self-play reinforcement learning with a heuristically constructed dataset of expert Go moves to create LoGos, a high-performing AI.
Despite recent advances in large language models (LLMs) demonstrating exceptional reasoning in broad domains, significant performance gaps persist when applying these models to specialized fields requiring expert knowledge. This limitation motivates the work ‘Mixing Expert Knowledge: Bring Human Thoughts Back To the Game of Go’, which introduces LoGos, a novel LLM achieving human professional-level proficiency in the complex game of Go through a training paradigm integrating reinforcement learning with a heuristically constructed expert dataset. LoGos not only maintains strong general reasoning abilities but also conducts Go gameplay in natural language, demonstrating effective strategic reasoning and accurate move prediction. Will this approach of blending general LLM capabilities with domain-specific expertise unlock similar advancements across other complex, knowledge-intensive fields?
The Challenge of Strategic Depth
For decades, artificial intelligence achieved remarkable success in games demanding precise calculation, most notably chess. However, the ancient game of Go presents a fundamentally different challenge. Unlike chess, where a relatively limited number of possible moves exist at each turn, Go’s larger board and simpler rules give rise to an astonishingly vast “game tree” – the total number of potential game states. This combinatorial explosion renders traditional AI methods, reliant on exhaustively searching possible move sequences, impractical. Go isn’t simply about calculating the best immediate move; it requires a nuanced understanding of strategic positioning, influence, and long-term planning-qualities that demand a more intuitive, pattern-recognition-based approach rather than brute-force computation. Consequently, developing AI capable of mastering Go necessitated a shift toward algorithms that could approximate strategic value and prioritize promising lines of play, rather than attempt to evaluate every possibility.
Large Language Models (LLMs), while demonstrating remarkable capabilities in various domains, encounter significant limitations when applied to complex games requiring extensive strategic foresight. This stems from what is known as the ‘Context Curse’ – a phenomenon where performance degrades as the length of the input sequence, representing the game state and reasoning chain, increases. Essentially, LLMs struggle to maintain relevant information across numerous turns and possibilities, hindering their ability to accurately evaluate positions and plan effectively. The computational demands of processing these lengthy sequences, combined with the model’s finite ‘attention window’, lead to critical details being overlooked or misinterpreted, ultimately impacting the quality of their decision-making in strategically rich environments. This constraint necessitates innovative approaches to managing context and enhancing long-term reasoning capabilities within LLMs to unlock their full potential in complex game scenarios.
LoGos: A Foundation for Strategic Understanding
LoGos utilizes the Qwen2.5-7B-Base and Qwen2.5-32B-Base large language models as its foundational architecture. These models were selected to provide a pre-trained base with sufficient parameter capacity for complex pattern recognition inherent in the game of Go. The Qwen2.5 models offer a balance between computational efficiency – particularly the 7B parameter variant – and the ability to represent nuanced game states, while the 32B model offers increased capacity for more complex understanding. Building upon these established LLMs allows LoGos to leverage existing knowledge and accelerate the learning process required for mastering Go strategy, rather than training from a randomly initialized state.
LoGos utilizes a dual-dataset approach to acquire Go knowledge. The Go Commentary Dataset provides human-generated analyses of games, offering insights into strategic thinking and move rationale. Complementing this, a Next Step Prediction Dataset, created using the KataGo engine, delivers a large volume of position-evaluation pairs, effectively teaching the model to predict optimal moves. This combination of human insight and machine-generated data aims to provide LoGos with both strategic understanding and tactical proficiency, exceeding the capabilities of models trained on single data sources.
The Next Step Prediction Dataset, used to train the LoGos AI, relies heavily on heuristic rules to ensure data quality. These rules, derived from expert Go players and established strategic principles, guide the generation of training examples by evaluating potential moves and prioritizing those considered strong or optimal. This process effectively filters out suboptimal or amateur moves, resulting in a dataset composed of high-quality, expert-level data. The use of heuristic rules is not merely for initial dataset creation; these rules also facilitate iterative refinement, allowing for continuous improvement of the dataset’s accuracy and relevance during the training process and subsequent model adjustments.

Training LoGos: A Path to Efficient Mastery
LoGos employs Group Relative Policy Optimization (GRPO), a reinforcement learning algorithm designed to improve sample efficiency in complex environments. GRPO achieves this by learning a policy relative to a group of previously learned policies, allowing for more stable and efficient exploration of the action space. Unlike standard policy gradient methods, GRPO minimizes the KL divergence between the current policy and a mixture of past policies, preventing drastic changes that can destabilize training. This relative optimization facilitates faster convergence and improved performance, particularly in scenarios with sparse rewards or high-dimensional state spaces, enabling LoGos to refine its strategic understanding through continuous self-play and adaptation.
LoGos incorporates Long Chain-of-Thought (CoT) reasoning to enhance its strategic capabilities by enabling multi-step inference during game analysis. This is achieved by prompting the model to explicitly articulate its reasoning process, breaking down complex game states into a series of intermediate logical steps. By generating a traceable sequence of thoughts, LoGos can better evaluate potential actions and their consequences, leading to more informed decision-making. The CoT implementation facilitates the identification of subtle tactical advantages and long-term strategic opportunities that might be missed through direct state evaluation, and allows for improved error analysis and refinement of its strategic understanding.
LoGos employs reinforcement learning for self-exploration, a process that allows the agent to move beyond the constraints of pre-defined datasets. This approach enables LoGos to actively interact with the game environment, generating its own training data through trial and error. By maximizing a reward signal, the agent iteratively refines its policy, discovering strategies not explicitly present in any initial dataset. Consequently, LoGos can develop emergent behaviors and achieve performance levels exceeding those attainable through supervised learning from human gameplay or static data alone, as it is not limited by the existing knowledge base and can independently optimize its decision-making process.
LoGos: A New Standard for Strategic AI
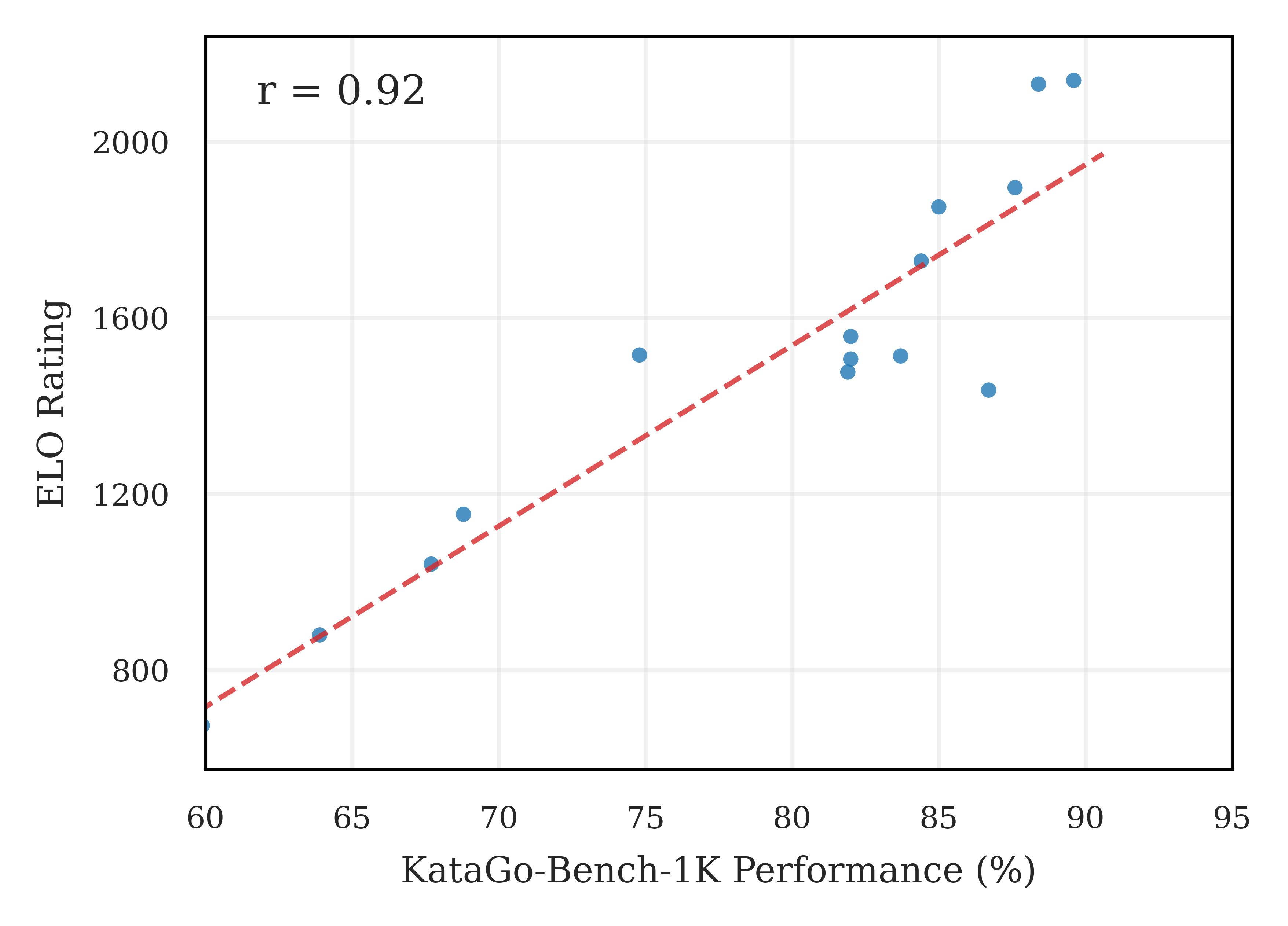
To rigorously assess LoGos’s proficiency in the complex game of Go, researchers employed the widely respected KataGo-Bench-1K benchmark, a standardized dataset designed to evaluate Go-playing artificial intelligence. This benchmark utilizes the Elo rating system – a method originally developed for chess – to provide a comparative measure of skill. Each model’s performance is quantified through a numerical Elo score, enabling a direct assessment of its relative strength against other programs. By subjecting LoGos to this established testing protocol, the study established a clear and objective metric for evaluating its capabilities and comparing it to existing state-of-the-art Go-playing engines, ensuring a transparent and verifiable demonstration of its advancements.
LoGos demonstrates a remarkable capacity for the game of Go, achieving an 88.6% accuracy rate on the challenging KataGo-Bench-1K benchmark – a performance indicative of expert-level proficiency. This evaluation, utilizing a standardized test suite, reveals LoGos’ ability to accurately assess game positions and predict optimal moves. The high score not only validates the model’s training but also establishes a new standard for large language models applied to complex strategic domains, signifying a substantial leap towards artificial intelligence capable of mastering nuanced, rule-based systems.
LoGos demonstrates a significant leap forward in artificial intelligence, exceeding the performance of established models like Claude3.7-Sonnet on the demanding KataGo-Bench-1K benchmark. Achieving an accuracy of 88.6%, LoGos not only rivals the skill of KataGo-Human-SL-9d, but also signals a broader potential for large language models. This success, built upon reinforcement learning and specialized domain knowledge, suggests a pathway for applying similar techniques to diverse fields involving intricate strategic decision-making – from logistical optimization and financial modeling to scientific discovery and even creative problem-solving. The demonstrated capabilities position LoGos as a compelling example of how AI can move beyond pattern recognition to exhibit genuine expertise in complex domains.
LoGos demonstrates a commitment to distilling Go’s complexity into a manageable, learnable form. The system’s reliance on both self-play and a curated expert dataset echoes a pursuit of essential knowledge, stripping away superfluous information to achieve proficiency. This aligns with the principle that unnecessary elements constitute a violence against attention. As John McCarthy stated, “The best way to predict the future is to create it.” LoGos doesn’t merely predict expert play; it actively constructs a pathway to it by integrating human insight with machine learning, effectively shaping the future of AI in complex domains like Go. The core concept of domain adaptation, so vital to LoGos’ success, benefits from this focused approach.
Beyond the Stone
The pursuit of artificial general intelligence often manifests in contrived contests – games, if one insists on the term. This work, achieving competence in Go through a synthesis of self-play and curated human knowledge, exposes a fundamental truth: proficiency isn’t born from brute computation alone. It requires distillation. The efficacy of LoGos hinges on the quality of the initial ‘expert’ dataset, a scaffolding upon which further learning proceeds. The lingering question, then, is not simply whether a machine can play Go, but how efficiently it can learn from human intuition, and more importantly, what is lost in that translation.
Future efforts will likely focus on diminishing the reliance on pre-constructed datasets. A truly adaptable system should be able to actively solicit, and critically evaluate, expert input during training – a form of algorithmic apprenticeship. However, the inherent ambiguity of human reasoning presents a challenge. How does one quantify ‘good form’ or ‘strategic intent’ in a manner digestible by an algorithm? The answer, predictably, will not lie in more data, but in more elegant abstraction.
Ultimately, this line of inquiry serves as a useful, though limited, proxy for broader challenges in artificial intelligence. The real task isn’t to create machines that mimic human performance, but to understand the principles underlying intelligence itself. The game, it seems, is merely a convenient canvas upon which to explore those principles – a simplification, perhaps, but one that reveals, rather than obscures, the path forward.
Original article: https://arxiv.org/pdf/2601.16447.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- The Best Directors of 2025
2026-01-26 22:34