Author: Denis Avetisyan
A new framework trains agents to ask clarifying questions before conducting deep research, significantly improving the quality and relevance of generated reports.
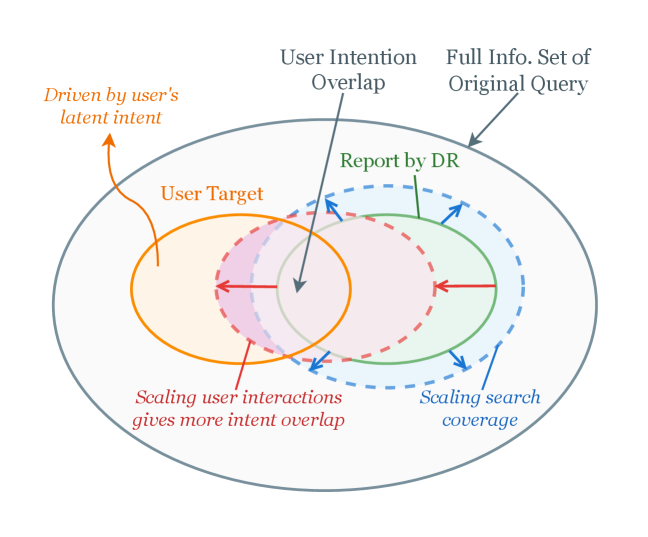
IntentRL leverages reinforcement learning to enable proactive user-intent clarification in open-ended tasks, demonstrating a scalable path toward more effective autonomous research agents.
While Large Language Models excel at synthesizing information, their application to open-ended ‘Deep Research’ tasks often suffers from an autonomy-interaction dilemma-high autonomy can lead to lengthy, unsatisfactory results. To address this, we introduce ‘IntentRL: Training Proactive User-intent Agents for Open-ended Deep Research via Reinforcement Learning’, a novel reinforcement learning framework that trains agents to proactively clarify user intent before embarking on complex research. This approach leverages both offline and online RL stages, coupled with a scalable data expansion pipeline, to significantly improve intent accuracy and downstream task performance. Could IntentRL pave the way for more effective and user-centric autonomous agents capable of tackling complex, open-ended challenges?
Decoding Ambiguity: The Foundation of Effective Inquiry
Deep research methodologies, while powerful, frequently encounter limitations when confronted with poorly defined user needs. Often, initial requests lack the specificity required to guide effective information retrieval, resulting in reports that, despite technical accuracy, fail to address the underlying question. This disconnect stems from the inherent difficulty in interpreting ambiguous language and inferring unstated requirements; algorithms, even sophisticated ones, operate best with clear parameters. Consequently, substantial effort can be wasted compiling irrelevant data or pursuing incomplete lines of inquiry, ultimately diminishing the value of the research and highlighting the critical need for proactive clarification of user intent before embarking on complex investigations.
Many current information retrieval systems operate on the explicit terms of a user’s query, failing to discern the underlying, unstated need-the latent intent. This presents a significant hurdle when dealing with complex requests, as a superficially valid query may mask a more nuanced information need. Effective research, therefore, demands a proactive approach where systems attempt to understand what a user truly seeks, not merely what they ask for. This necessitates algorithms capable of inferring context, recognizing ambiguities, and initiating clarifying dialogues-capabilities largely absent in conventional search architectures. Until systems can reliably decode latent intent, even powerful data analysis tools will struggle to deliver truly relevant and comprehensive results, leaving users to sift through a sea of potentially useless information.
The fundamental difficulty in deep research lies not in accessing information, but in converting a user’s initial, often imprecise, question into a set of concrete, searchable parameters. A vague query – for example, “What about climate change?” – lacks the specificity needed for effective data retrieval; it doesn’t define a timeframe, geographical focus, or specific aspect of the issue. Successfully addressing this requires a system to discern the latent intent behind the query, effectively deconstructing it into distinct, measurable components. This translation process demands an understanding of subject matter, an ability to anticipate information needs, and the capacity to formulate focused search terms – transforming an ambiguous request into a precise blueprint for research, ultimately bridging the gap between what is asked and what must be found.
The efficacy of even the most sophisticated algorithms hinges on the precision of the input they receive; consequently, a lack of clarity in initial queries directly diminishes their potential. Powerful computational tools, designed to sift through vast datasets and identify relevant insights, are rendered less effective when tasked with interpreting ambiguous requests. This isn’t a limitation of the technology itself, but rather a consequence of its reliance on well-defined parameters. The algorithms function optimally when presented with specific criteria, and struggle to extrapolate intended meaning from vague phrasing, leading to results that, while technically accurate, fail to address the user’s underlying information need. Essentially, a powerful engine requires a clear destination to reach its full potential; without proper direction, its capabilities are significantly curtailed, delivering suboptimal outcomes despite considerable processing power.
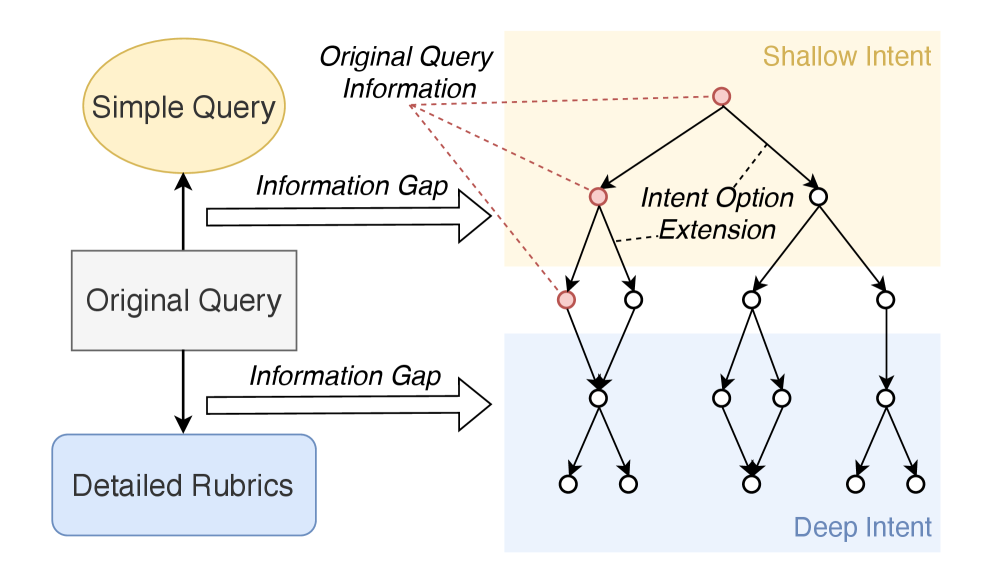
IntentRL: A Proactive Clarification Framework
IntentRL is a reinforcement learning framework that prioritizes the proactive identification of user intent prior to commencing extensive information retrieval. This is achieved through an agent trained to request clarifying information from the user, effectively narrowing the scope of research and focusing data collection efforts. Unlike reactive approaches that begin research immediately and address ambiguities as they arise, IntentRL aims to preemptively resolve uncertainty, leading to more efficient and targeted information gathering. The framework formulates intent elicitation as a sequential decision-making problem, allowing the agent to learn an optimal strategy for querying user preferences and defining research parameters before initiating a full-scale investigation.
IntentRL utilizes a Clarification Directed Acyclic Graph (CDAG) to systematically manage the elicitation of user intent. The CDAG represents potential clarification questions as nodes, and dependencies between these questions as directed edges; this structure ensures questions are asked in a logical order, avoiding redundant or irrelevant inquiries. Each node in the graph corresponds to a specific aspect of the research request needing further definition, and the edges denote prerequisite relationships – for example, clarifying the target audience before detailing specific features. This graph-based approach enables scalable data construction by allowing the system to efficiently explore the space of possible clarifications and prioritize questions based on their impact on downstream research tasks, significantly reducing the number of interactions required to achieve a well-defined research objective.
IntentRL utilizes a two-stage reinforcement learning approach. Initially, the agent is trained using Offline RL, leveraging a dataset of expert-demonstrated clarification trajectories to establish a foundational policy. This pre-training accelerates learning and provides a strong starting point for subsequent refinement. Following Offline RL, the system transitions to Online RL, allowing the agent to interact with a simulated environment and adapt its clarification strategy based on real-time feedback. This online component enables continuous improvement and allows the agent to refine its policy beyond the limitations of the initial expert data, optimizing for long-term report quality and relevance.
IntentRL proactively identifies potential information deficiencies before commencing in-depth research, thereby optimizing data acquisition. This is achieved through a reinforcement learning agent trained to predict likely gaps in understanding relative to a given query. By prioritizing data collection focused on these anticipated gaps, the system avoids expending resources on irrelevant information and concentrates on evidence directly contributing to a comprehensive and accurate report. This targeted approach demonstrably improves report quality, as the agent is equipped with the necessary information to address the core aspects of the user’s intent with greater precision and completeness.

Constructing a Robust Simulator for User Interaction
The User Simulator is a core element of the IntentRL framework, functioning as a dynamic environment for agent training and evaluation. This simulator replicates user interactions, allowing the agent to practice and refine its dialogue management skills without requiring real human participants. It accepts agent actions as input, processes them according to a predefined user model, and generates corresponding user responses. The simulator’s architecture is designed to be modular and configurable, enabling the creation of diverse user behaviors and the simulation of varied interaction scenarios. This facilitates robust training, allowing the agent to encounter a wide range of user responses and learn to adapt its strategies accordingly, ultimately improving performance in real-world deployments.
The Intent-Aware User Simulator builds upon foundational simulation frameworks by incorporating a model of user intent. Rather than responding solely to the surface-level query, the component analyzes the request to infer the user’s underlying goal. This allows the simulator to generate responses that are consistent with the inferred intent, even if the initial query is ambiguous or incomplete. Specifically, the system maintains a probabilistic representation of possible user intents and uses this to guide response generation, resulting in more realistic and nuanced interactions during agent training. This contrasts with traditional simulators which often rely on predefined templates or keyword matching, and offers a more dynamic and contextually appropriate simulation environment.
The User Simulator incorporates a model of user response to clarification questions, predicting how a user will react – either by providing the requested information, refusing to engage, or expressing frustration – based on the type of question asked and the current dialogue state. This allows the IntentRL agent to be trained on a diverse range of user behaviors encountered during clarification attempts. The simulation quantifies the impact of different questioning strategies – including question phrasing, timing, and the number of clarifying questions asked – on user cooperation and task completion rates. Through repeated interaction with the simulated user, the agent learns to identify optimal questioning strategies that maximize information gain while minimizing user burden and maintaining a positive user experience, ultimately improving performance in real-world ambiguous query resolution.
Training an agent with the IntentRL User Simulator directly addresses the challenge of ambiguous user queries encountered in real-world interactions. The simulation exposes the agent to a variety of intentionally ambiguous inputs, forcing it to learn policies for requesting clarifying information. By repeatedly practicing with these simulated ambiguous scenarios, the agent develops robust questioning strategies and learns to discern the user’s underlying intent even with incomplete or unclear initial requests. This iterative training process results in an agent capable of effectively handling ambiguity, minimizing errors, and maximizing successful task completion in practical deployments where such uncertainties are common.
Balancing Autonomy and Interaction: The Core of Intelligent Assistance
The development of IntentRL brings into sharp focus the inherent tension between proactive autonomy and necessary user interaction in intelligent systems. A truly effective agent must determine the optimal balance between independently seeking clarification to refine understanding and directly requesting input from the user. Too much self-directed questioning risks frustrating the user with irrelevant or repetitive inquiries, effectively hindering the research process; conversely, an over-reliance on explicit user direction negates the benefits of a proactive, clarifying agent. IntentRL’s design specifically addresses this ‘Autonomy-Interaction Dilemma’, striving to create a system that anticipates information needs without becoming intrusive, ultimately improving the efficiency and relevance of deep research report generation.
The pursuit of genuinely helpful artificial intelligence often encounters a delicate balancing act: the autonomy-interaction dilemma. A system designed to independently gather information and synthesize insights risks frustrating users if it repeatedly requests clarification on inconsequential details, effectively becoming a verbose and inefficient assistant. Conversely, a system that excessively relies on direct user input to confirm every step or nuance negates the very benefit of proactive intelligence; it transforms into a simple interface for data retrieval, rather than a truly insightful partner. Achieving a successful balance requires an agent capable of discerning genuinely ambiguous areas requiring clarification from those it can reasonably infer, ensuring both efficiency and a positive user experience.
The core of IntentRL’s success lies in a novel Two-Stage Reinforcement Learning approach, enabling the agent to dynamically calibrate its level of proactive questioning. This method doesn’t simply maximize task completion; it optimizes for a harmonious balance between autonomy and a positive user experience. The first stage trains the agent to predict when clarification will be genuinely beneficial, avoiding unnecessary interruptions. Subsequently, a second stage refines this policy, rewarding the agent not only for accurate information gathering, but also for minimizing the cognitive load on the user – effectively learning when and how to ask for help, rather than merely seeking it at every opportunity. This nuanced learning process results in a system that is both efficient and user-friendly, achieving superior performance metrics and demonstrating a significant advancement in intelligent information retrieval.
IntentRL demonstrably elevates the quality of deep research reports through a carefully balanced approach to proactive clarification and user interaction. Rigorous evaluation reveals that the system achieves state-of-the-art performance, evidenced by significant gains in both Intent Precision and Recall – exceeding baseline models by -15.33 and -9.04, respectively. This improvement isn’t merely quantitative; IntentRL also excels in qualitative dimensions, as confirmed by its leading scores on the PDR-Bench. Specifically, the system attained the highest P-Score, indicating superior personalization alignment with user needs, and the highest Q-Score, reflecting enhanced content quality and relevance, ultimately streamlining the research process and delivering more impactful insights.
The pursuit of autonomous agents capable of deep research necessitates a holistic understanding of system interactions, much like a carefully constructed organism. IntentRL embodies this principle by proactively clarifying user intent before embarking on complex tasks. This framework doesn’t merely address the symptom of ambiguous requests; it fundamentally reshapes the agent’s approach to problem-solving. As Paul Erdős aptly stated, “A mathematician knows a lot of things, but a good mathematician knows where to find them.” IntentRL’s strength lies in its ability to ‘find’ clarity, mirroring the elegant efficiency of a well-designed system where each component-intent clarification, research execution, and report generation-works in harmony. The architecture prioritizes understanding the ‘whole’ before acting, ensuring a scalable and user-centric approach to open-ended tasks.
What’s Next?
The pursuit of agents that ‘understand’ intent – or, more accurately, navigate the ambiguity of it – reveals a fundamental tension. IntentRL rightly frames clarification as a proactive step, yet sidesteps the deeper question of what constitutes sufficient understanding. If the system survives on duct tape, it’s probably overengineered. The current focus on reward signals for report quality, while pragmatic, risks optimizing for superficial coherence rather than genuine knowledge synthesis. A more elegant design will require a shift from evaluating outputs to modeling the underlying information landscape itself.
Modularity without context is an illusion of control. Disentangling intent clarification from the deep research process feels… convenient. Future work must confront the inextricable link between how an agent asks a question and what information it ultimately retrieves. The framework’s reliance on offline reinforcement learning, while a reasonable starting point, hints at a lingering dependence on curated datasets. True scalability demands agents capable of learning from the messy, unedited stream of real-world user interactions-a prospect that necessitates robust methods for handling noisy signals and adversarial inputs.
Ultimately, the challenge isn’t building agents that mimic research, but designing systems that evolve a coherent worldview. The current paradigm treats knowledge as a static resource to be extracted. A more fruitful path lies in conceiving of agents as active participants in a dynamic, ever-shifting information ecosystem – constantly refining their understanding, not through mere data accumulation, but through a principled process of iterative exploration and conceptual refinement.
Original article: https://arxiv.org/pdf/2602.03468.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- The Best Former NFL Players Turned Actors, Ranked
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- Silver Rate Forecast
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 20 TV Series That Killed Their Best Character and Survived
2026-02-04 15:23