Author: Denis Avetisyan
Researchers have developed a framework that equips artificial intelligence with the ability to strategically construct rebuttals, mimicking human reasoning in academic discourse.

This work introduces RebuttalAgent, a reinforcement learning framework leveraging Theory of Mind, alongside the RebuttalBench dataset and Rebuttal-RM evaluation metric for improved academic rebuttal quality.
Despite advances in artificial intelligence, effectively responding to peer review remains a uniquely challenging communication problem, demanding more than surface-level linguistic competence. This paper, ‘Dancing in Chains: Strategic Persuasion in Academic Rebuttal via Theory of Mind’, introduces RebuttalAgent, a novel framework that grounds rebuttal in Theory of Mind, leveraging reinforcement learning and a new dataset, RebuttalBench, to model reviewer mental states and generate persuasive responses. Our experiments demonstrate that RebuttalAgent significantly outperforms existing methods, even surpassing powerful proprietary models in both automated and human evaluations, as assessed by our specialized evaluator, Rebuttal-RM. Could this approach unlock a new era of AI-assisted scientific communication, fostering more productive and nuanced scholarly debate?
The Asymmetry of Scholarly Discourse
The established process of academic peer review, while foundational to scholarly communication, demonstrably struggles with systemic inefficiencies and the unavoidable presence of subjective judgment. These factors contribute to significant delays in publication, as manuscripts cycle through multiple rounds of evaluation and revision. Moreover, inherent biases – stemming from reviewer expertise, institutional affiliations, or even unconscious preferences – can unduly influence assessments of merit, potentially overlooking innovative research or favoring established paradigms. This isn’t necessarily indicative of malicious intent, but rather a consequence of relying on human evaluation within a system that lacks standardized criteria and transparent evaluation metrics, ultimately impacting the objectivity and fairness of the scientific record.
The academic peer review process, despite its crucial role in validating research, functions as a complex system best understood through the lens of game theory. Specifically, it resembles a Dynamic Game of Incomplete Information, where both authors and reviewers act strategically with imperfect knowledge. Reviewers, tasked with evaluating manuscripts, inherently lack complete insight into the author’s research goals, the nuances of the experimental design, or the full context of the findings. This informational asymmetry forces reviewers to make judgments based on limited data, potentially leading to misinterpretations or overlooked strengths. Simultaneously, authors must anticipate these potential shortcomings in reviewer understanding when preparing their submissions and, crucially, when crafting rebuttals. Recognizing this dynamic interplay is essential, as it moves beyond a simple assessment of merit and highlights the strategic communication required to navigate the review process effectively.
The peer review process isn’t simply an objective assessment of research quality; it functions as a strategic interplay between authors and reviewers, each acting with incomplete information. Recognizing this dynamic is crucial because traditional rebuttal strategies often fall short by addressing comments at a surface level. A more effective approach necessitates inferring the underlying reasoning and concerns of reviewers – understanding why a comment was made, not just what was said. Authors who can accurately assess reviewer intent and tailor responses accordingly are better positioned to navigate the process successfully, demonstrating not only the merit of their work but also a sophisticated understanding of the evaluation landscape itself. This shift from reactive defense to proactive clarification can significantly improve the likelihood of acceptance and foster a more constructive dialogue within the scientific community.
Contemporary rebuttal practices in academic peer review frequently address reviewer comments at a surface level, failing to discern the underlying motivations or specific concerns driving those criticisms. This superficial approach often results in responses that, while technically addressing the stated points, do not adequately resolve the fundamental issues a reviewer may have with the manuscript’s methodology, interpretation, or significance. A more strategic rebuttal requires inferring the reviewer’s intent – whether the critique stems from genuine methodological concerns, differing theoretical perspectives, or simply a lack of clarity in the presentation – and crafting a targeted response that directly addresses the root of the issue, rather than merely offering a point-by-point defense. This deeper level of engagement, however, is rarely prioritized in current rebuttal strategies, hindering the potential for constructive dialogue and efficient resolution of concerns.
Strategic Rebuttal: Modeling the Reviewer’s Mind
RebuttalAgent represents a novel approach to automated academic rebuttal by incorporating Theory of Mind (ToM) capabilities. Prior systems have treated reviewer comments as purely textual input, lacking the ability to infer the underlying beliefs, intentions, and potential reasoning of the reviewer. RebuttalAgent addresses this limitation by explicitly modeling the reviewer’s perspective, allowing the system to move beyond surface-level understanding and engage in more nuanced and strategically effective responses. This integration of ToM distinguishes RebuttalAgent as the first framework designed to reason about why a reviewer might have raised a particular concern, rather than simply what was stated in the review.
The ToM-Strategy-Response (TSR) pipeline is the foundational architecture of RebuttalAgent, structuring the rebuttal process into three distinct phases. Initially, the ‘Understanding the Reviewer’ phase analyzes the review text to identify stated concerns, underlying reasoning, and potential beliefs driving the critique. This analysis informs the ‘Formulating a Strategic Response’ phase, where RebuttalAgent determines the optimal rebuttal approach – such as directly addressing concerns, providing clarifying evidence, or respectfully disagreeing – based on the inferred reviewer intent. Finally, the ‘Generating the Actual Rebuttal Text’ phase translates the strategic response into coherent and persuasive language, producing the final rebuttal content. This decomposition allows for targeted and effective rebuttals by explicitly linking reviewer understanding to response strategy and text generation.
Supervised Fine-tuning (SFT) was utilized to establish RebuttalAgent’s initial understanding of the rebuttal process. This involved training the model on a large-scale dataset comprising paper-review-rebuttal triplets. The dataset consists of submitted research papers, corresponding reviewer comments, and the authors’ subsequent rebuttals, allowing the model to learn the relationships between critiques and appropriate responses. SFT optimizes the model’s parameters to predict effective rebuttal text given a paper and its associated review, effectively priming it for downstream strategic reasoning and response generation. The scale of this dataset is critical, providing sufficient examples for the model to generalize and avoid overfitting to specific review patterns.
The Hierarchical Reviewer Profile within RebuttalAgent is designed to represent reviewer perspectives at multiple levels of granularity. This profile consists of two primary components: a broad intent classification, which categorizes the overall stance of the review (e.g., positive, negative, mixed), and a set of specific concern extractions, detailing the individual criticisms and questions raised. The hierarchical structure enables the model to not only identify what the reviewer is questioning, but also why – allowing for rebuttals tailored to address the underlying motivations behind each comment. This profile is dynamically constructed from the review text using natural language processing techniques and serves as the foundational input for strategic rebuttal generation.
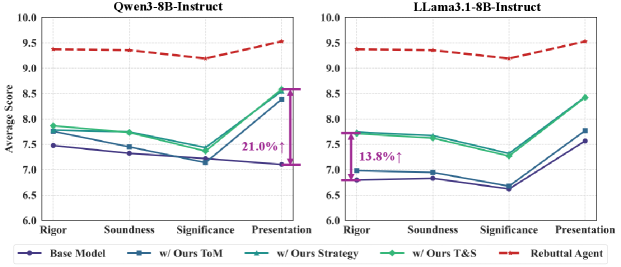
Reinforcement Learning and the Pursuit of Optimal Response
Reinforcement Learning (RL) was implemented to dynamically refine RebuttalAgent’s capabilities beyond pre-programmed responses. This involved training the agent to analyze the “Theory of Mind” (ToM) of the reviewer – specifically, their likely reasoning and concerns – and to formulate rebuttal strategies accordingly. The RL framework enables the agent to learn from interactions and iteratively improve its ToM-based analysis and policy selection, optimizing for effective responses that address reviewer concerns. This contrasts with static knowledge approaches, allowing RebuttalAgent to adapt to nuanced reviewer feedback and refine its rebuttal strategies over time based on observed outcomes.
The RebuttalAgent employs a Self-Reward Mechanism to overcome the difficulty of establishing an external reward function for rebuttal quality. This mechanism enables the agent to assess its own generated responses based on internal criteria related to relevance, coherence, and persuasiveness. Specifically, the agent analyzes its output to determine the extent to which it addresses the original claims and provides sufficient justification, assigning itself a reward score accordingly. This self-assessment process allows for continuous learning and refinement of rebuttal strategies without requiring extensive human-labeled data or pre-defined quality metrics, effectively transforming the agent into both a generator and evaluator of its own performance.
The system employs a Context Retrieval Pipeline to identify and isolate pertinent information from the original manuscript, enabling the generation of focused rebuttals. This pipeline utilizes a Large Language Model (LLM) functioning as an extractor to pinpoint relevant passages. Evaluation, based on manual review of a 100-sample dataset, demonstrates a comment extraction accuracy of 98%, indicating a high degree of precision in identifying content crucial for rebuttal construction.
RebuttalAgent’s performance is assessed using Rebuttal-RM, a dedicated evaluation model specifically trained to reflect human preferences for effective rebuttals. This evaluation process demonstrated an 18.3% overall performance increase compared to the baseline model. Human evaluation of RebuttalAgent’s output yielded a score of 9.57, representing the highest performance achieved among all models tested during the evaluation phase. This scoring indicates a strong alignment between the model’s generated rebuttals and human expectations for quality and relevance.
Toward a Streamlined Scholarly Discourse
RebuttalAgent represents a significant advancement in automated peer review, moving beyond simple critique to actively address reviewer concerns. This framework doesn’t merely identify weaknesses in a manuscript; it generates reasoned rebuttals, effectively simulating the author’s response to each point raised. By automating this traditionally time-consuming process, RebuttalAgent aims to drastically streamline the revision cycle and enhance the overall quality of academic discourse. The system’s ability to formulate responses allows researchers to focus on substantive improvements to their work, rather than being bogged down in administrative tasks, ultimately fostering a more efficient and productive research environment. This proactive approach to addressing feedback has the potential to reshape how scholarly work is evaluated and refined, encouraging more constructive dialogue and accelerating the dissemination of knowledge.
RebuttalAgent significantly eases the often-demanding task of responding to peer review comments. The framework automates the generation of rebuttals, effectively reducing the cognitive load on authors and freeing valuable time. This automation isn’t simply about speed; it allows researchers to dedicate more effort to substantive improvements to their work, rather than being consumed by the mechanics of addressing each critique. By handling the initial drafting of responses, RebuttalAgent empowers authors to critically evaluate reviewer feedback and refine their research with greater focus and precision, ultimately enhancing the quality and impact of published findings.
A significant challenge in peer review lies in accurately interpreting the nuances of reviewer feedback, often leading to defensive responses or misconstrued criticisms. RebuttalAgent addresses this by moving beyond simple keyword matching to infer the underlying intent of each review comment. This capability allows the system to not only identify what a reviewer is questioning, but also why – distinguishing, for example, between a request for clarification, a suggestion for improvement, or a fundamental disagreement with the methodology. By articulating this inferred intent alongside the original comment, RebuttalAgent fosters a more constructive dialogue between authors and reviewers, minimizing misunderstandings and ultimately leading to more productive revisions and a stronger final product. The framework aims to transform the review process from a potentially adversarial exchange into a collaborative effort focused on strengthening the scientific record.
The development of RebuttalAgent is not reaching a conclusion, but rather entering a phase of refinement and broadened applicability. Current efforts are directed towards equipping the framework to navigate the intricacies of more challenging review scenarios, extending beyond straightforward critiques to encompass nuanced arguments and multifaceted feedback. Crucially, this expansion will be guided by real-world implementation; data gathered from practical usage will be integrated to iteratively improve the system’s performance and ensure it effectively addresses the needs of the academic community. This feedback loop promises to not only enhance the accuracy and relevance of generated rebuttals, but also to identify unforeseen challenges and opportunities for innovation in automated peer review.
The pursuit of RebuttalAgent, as detailed in this work, embodies a rigorous approach to strategic reasoning. It isn’t merely about generating text that appears persuasive, but constructing an agent capable of modeling an opponent’s beliefs – a formalized Theory of Mind. This echoes Claude Shannon’s sentiment: “The most important thing in communication is to minimize errors.” RebuttalBench and Rebuttal-RM aren’t simply benchmarks; they are mechanisms to quantify those errors, to reveal the invariant – the underlying logic – of effective academic discourse. If the agent’s rebuttals feel clever, it suggests the underlying mathematical structure hasn’t been fully exposed, that the core principles governing persuasion remain obscured. The framework demands provability, not just empirical success on a test set.
What’s Next?
The construction of RebuttalAgent, while demonstrating a capacity for strategic response, merely scratches the surface of a far more profound challenge. The current formulation, reliant on reinforcement learning, implicitly assumes a convergent game within academic discourse. This is, of course, a fallacy. The asymptotic behavior of rebuttal – even strategically informed rebuttal – will inevitably trend toward infinite regress, a perpetual escalation of counter-arguments lacking a demonstrable, absolute ground. The efficacy of the approach, therefore, remains fundamentally bounded by the inherent incompleteness of any formal system attempting to model human argument.
Future work must address the limitations of relying solely on observable behavior to infer mental states. The presented Theory of Mind model, while functional, operates on a simplified representation of belief and intention. A more rigorous approach demands the incorporation of second-order logic, allowing for reasoning about reasoning – a formalization of metacognition. Furthermore, the dataset, RebuttalBench, is necessarily finite. Establishing provable guarantees about generalization requires a shift toward datasets constructed via formal methods, ensuring coverage of all logically possible rebuttal scenarios – a task bordering on the intractable.
Ultimately, the pursuit of automated academic rebuttal is not about achieving ‘intelligent’ response, but about exposing the limits of formalization itself. The true measure of success will not be in mimicking human argumentation, but in identifying those points where logic collapses, revealing the irreducibly subjective core of intellectual inquiry.
Original article: https://arxiv.org/pdf/2601.15715.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
2026-01-24 10:00