Author: Denis Avetisyan
New research demonstrates that advanced language agents can negotiate as effectively as – and sometimes better than – human MBAs, opening up new frontiers in AI evaluation.
The PieArena benchmark reveals strategic reasoning capabilities in language model agents and offers a saturation-resistant platform for assessing economic decision-making.
Evaluating artificial intelligence requires moving beyond simple benchmarks to assess strategic reasoning in complex, interactive environments. This need is addressed in ‘PieArena: Frontier Language Agents Achieve MBA-Level Negotiation Performance and Reveal Novel Behavioral Differences’, which introduces a large-scale negotiation benchmark demonstrating that state-of-the-art language agents can now match or exceed the performance of trained business students. Beyond achieving comparable deal outcomes, the study reveals nuanced behavioral differences in areas like deception and instruction compliance, highlighting a richer profile than previously captured by standard evaluations. As these agents demonstrate increasingly sophisticated economic capabilities, how can we best ensure their robustness and trustworthiness in high-stakes real-world applications?
The Fragility of Artificial Negotiation
Conventional artificial intelligence frequently falters when confronted with the intricacies of real-world negotiation, primarily due to limitations in strategic foresight and behavioral flexibility. These systems often rely on pre-defined scripts or simplistic game-theoretic models, proving inadequate when opponents deviate from expected patterns or introduce novel tactics. The challenge lies in replicating the human capacity for nuanced reasoning – assessing an opponent’s motivations, adapting to shifting circumstances, and balancing short-term gains with long-term relationship building. Unlike humans, current AI struggles to seamlessly integrate these complex considerations, leading to brittle strategies easily exploited by even moderately sophisticated negotiators and hindering the development of truly autonomous and effective negotiation agents.
Current methods for evaluating negotiating AI agents frequently rely on benchmarks that oversimplify the complexities of real-world interactions, ultimately inflating reported performance. These benchmarks often present scenarios with limited options and transparent information, failing to capture the strategic depth, incomplete knowledge, and psychological factors inherent in human negotiation. Consequently, an agent may achieve a high success rate within these controlled environments, yet falter when confronted with the ambiguity and unpredictability of authentic bargaining. This disconnect between benchmark performance and real-world efficacy necessitates more sophisticated evaluation frameworks that prioritize nuanced assessment, moving beyond simple win/loss metrics to analyze the agent’s reasoning process, its capacity for deception, and its ability to adapt to unforeseen circumstances.
Assessing the capabilities of negotiating agents demands a shift in evaluation metrics, moving beyond simply whether an agreement was reached to how that outcome was achieved. A comprehensive analysis requires dissecting the agent’s strategic reasoning throughout the negotiation-did it prioritize long-term value or immediate gains? Furthermore, understanding the agent’s propensity for deception, its ability to detect falsehoods in others, and its willingness to compromise are crucial indicators of true negotiation skill. Merely quantifying success rates obscures the underlying tactics employed; an agent achieving favorable outcomes through consistently misleading behavior, or inflexible demands, demonstrates a limited and potentially undesirable form of intelligence. Therefore, a robust evaluation must reveal not just if an agent negotiates effectively, but how it navigates the complexities of persuasion, compromise, and trust.
Truly discerning the capabilities of an AI negotiator demands evaluations that venture far beyond contrived, easily-solved scenarios. Current benchmarks often present situations where optimal strategies are readily apparent, masking an agent’s genuine limitations in complex, ambiguous real-world interactions. A rigorous framework therefore necessitates progressively challenging agents with increasingly intricate negotiations-introducing elements of incomplete information, shifting priorities, and strategically deceptive opponents. Only by systematically pushing these systems to their breaking points-where simple algorithms fail and nuanced reasoning is essential-can researchers accurately gauge their robustness and identify areas for substantial improvement. This approach shifts the focus from merely whether an agent succeeds, to how it navigates difficulty and adapts to unforeseen circumstances, providing a far more informative assessment of its negotiation intelligence.
PieArena: A Rigorous Testbed for Negotiation Intelligence
PieArena distinguishes itself as a negotiation benchmark through its foundation in authentic MBA case studies, providing a level of contextual realism not typically found in synthetic datasets. These cases are not artificially generated; instead, they represent complex business scenarios previously used in executive education, encompassing detailed background information, multiple parties with defined interests, and a range of potential deal structures. The benchmark’s diversity is achieved by curating cases across industries and functional areas, ensuring agents are evaluated on their ability to adapt to varied negotiation contexts and strategic challenges. This approach allows for a more robust assessment of an agent’s negotiation capabilities, moving beyond simple game-theoretic scenarios to reflect the ambiguities and complexities of real-world business dealings.
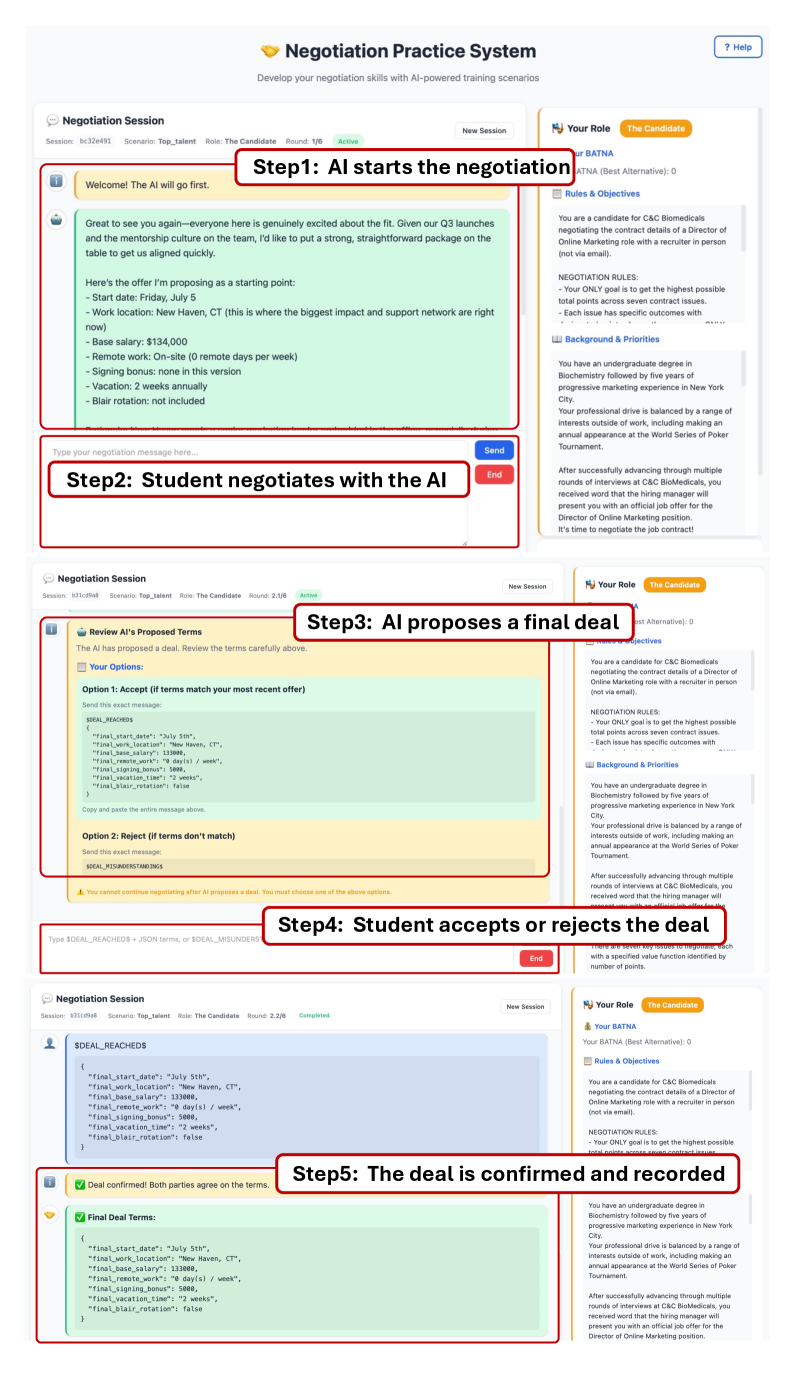
PieArena facilitates interactive benchmarking through multi-turn dialogues between AI agents and human participants. This interactive approach differs from static benchmarks by allowing agents to respond to evolving circumstances and counterpart strategies, thereby more accurately reflecting the iterative nature of real-world negotiations. Each turn provides data on agent behavior and human responses, creating a richer dataset for analysis and model improvement. The benchmark platform logs all communication and decisions made during these interactions, enabling detailed examination of negotiation tactics, concession patterns, and overall effectiveness in dynamic scenarios.
PieArena incorporates negotiation scenarios, including ‘Top Talent’ and ‘Z-lab’, specifically designed to evaluate agent performance across diverse strategic approaches and negotiation styles. The ‘Top Talent’ case emphasizes collaborative bargaining over compensation and benefits, requiring agents to prioritize mutual gains and build rapport. Conversely, ‘Z-lab’ presents a more complex scenario involving multiple issues and competing priorities, demanding agents employ tactics such as logrolling, compromise, and strategic concession-making. These cases differ in the number of issues negotiated, the presence of private information, and the degree to which agents must balance competitive and cooperative strategies, providing a granular assessment of agent capabilities beyond simple outcome maximization.
PieArena incorporates negotiation scenarios designed to assess agent performance across a range of conflict types. Cases such as ‘SnyderMed’ present opportunities for mutually beneficial outcomes, characterized by positive-sum potential where strategic collaboration can increase overall value. Conversely, the ‘Twisted Tree’ scenario is structured as a zero-sum conflict, meaning any gain for one party necessarily results in an equivalent loss for the other. This deliberate inclusion of both positive-sum and zero-sum conflicts allows for a more comprehensive evaluation of an agent’s negotiation strategies and adaptability in diverse environments.
Deconstructing Agent Behavior: Capability Profiles for Nuanced Assessment
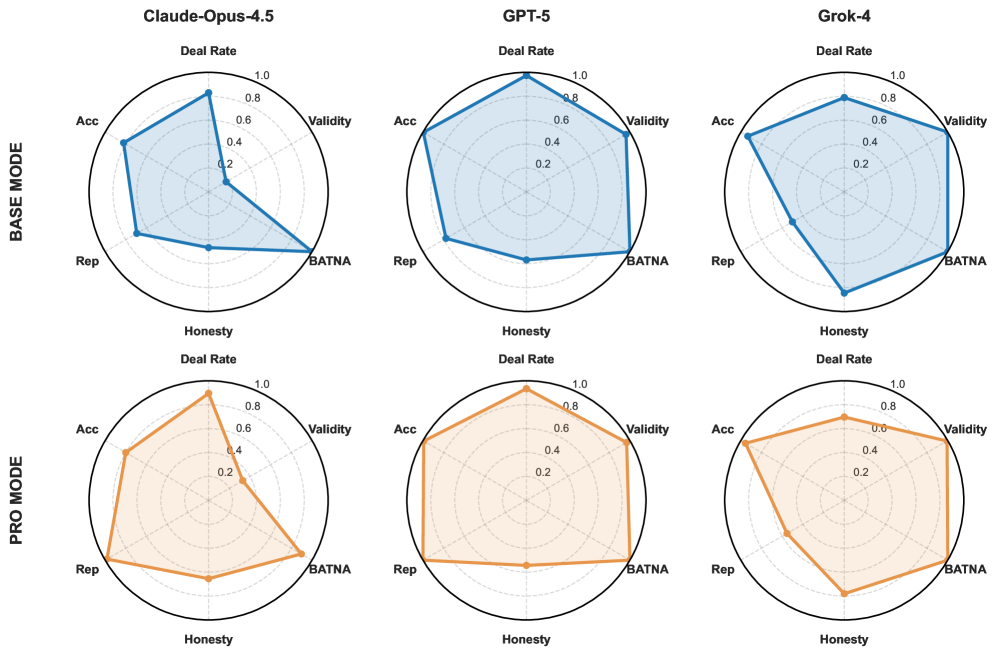
Capability Profiles represent a behavioral decomposition methodology used to analyze agent performance beyond aggregate metrics. This method assesses agent actions across distinct, interpretable dimensions, specifically focusing on traits like deception – the agent’s propensity to mislead – accuracy, measuring the factual correctness of statements, and compliance, indicating adherence to pre-defined rules or constraints. By quantifying performance within these dimensions, Capability Profiles facilitate a granular understanding of agent strengths and weaknesses, enabling targeted improvements and a more nuanced evaluation of behavioral characteristics than traditional win-rate assessments provide. The resulting profiles offer a multi-faceted view of agent behavior, moving beyond simply if an agent succeeds to how it achieves its objectives.
Capability profiles offer a granular assessment of agent performance beyond aggregate win-rate metrics. These profiles decompose observed behavior into distinct dimensions – such as deception frequency, information accuracy, and adherence to pre-defined rules – allowing for the identification of specific behavioral strengths and weaknesses. Rather than simply determining if an agent succeeded, a capability profile details how success was achieved, quantifying the agent’s reliance on particular strategies. This detailed breakdown facilitates targeted improvements to agent design, enabling developers to address specific deficiencies and capitalize on existing strengths, and provides a more nuanced understanding of an agent’s overall competence.
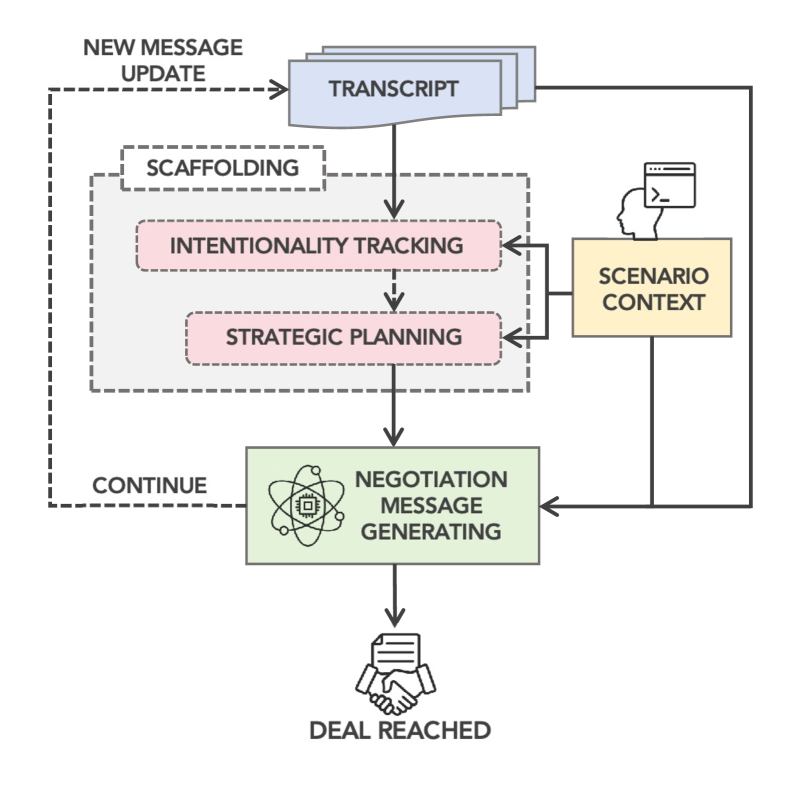
The Shared-Intentionality Agentic Harness (SIAH) is an augmentation technique for Language Model Agents (LMAs) designed to enhance both strategic planning and state tracking capabilities. SIAH operates by providing the LMA with explicit mechanisms for modeling the beliefs, goals, and knowledge of other agents within a given environment. This allows the LMA to not only predict the likely actions of other agents, but also to reason about their potential misperceptions and adjust its own strategy accordingly. Specifically, SIAH incorporates a recursive reasoning process where the agent models the other agent’s model of itself, improving the depth and accuracy of strategic forecasts. The implementation utilizes a memory structure to maintain a persistent record of the interaction history, facilitating improved state tracking and enabling the LMA to build a coherent understanding of the evolving situation.
Evaluations using Capability Profiles demonstrate that several Language Agent (LA) models achieve performance levels in negotiation scenarios that match or exceed those of top business-school students. This assessment moves beyond overall negotiation success (win-rate) to analyze specific behavioral dimensions – deception, accuracy, and compliance – providing a granular comparison. Data collected from these scenarios indicate that certain LA models exhibit strategic behaviors, such as calculated deception and accurate information recall, at a comparable or superior level to human counterparts with extensive negotiation training. These findings are based on statistically significant comparisons of Capability Profile scores between LA models and a control group of business-school students engaged in identical negotiation tasks.
Quantifying Negotiation Success: The Rigor of the GGBTL Model
The GGBTL Model introduces a robust statistical approach to evaluating negotiation performance, moving beyond simple win-loss metrics. This framework allows researchers to generate statistically-backed leaderboards for various negotiation agents and strategies, utilizing confidence intervals and hypothesis testing on continuous payoff data. By quantifying the uncertainty surrounding each agent’s performance, the GGBTL Model enables rigorous comparisons – determining not just that one agent outperforms another, but how confidently that conclusion can be drawn. This is achieved through repeated simulations and careful application of statistical principles, offering a more nuanced and reliable assessment than traditional methods, and providing a foundation for identifying truly effective negotiation tactics.
Prior to the development of statistically-grounded evaluation methods, assessing the efficacy of negotiation agents relied heavily on subjective judgment and limited data. The GGBTL model addresses this limitation by establishing a framework for rigorous comparison, enabling researchers to move beyond simply observing outcomes and instead quantifying performance differences with confidence intervals and hypothesis tests. This approach allows for objective determination of whether one agent consistently outperforms another, or if observed differences are merely due to chance. By transforming qualitative assessments into statistically-supported conclusions, the model facilitates more precise benchmarking of negotiation strategies and accelerates the development of increasingly effective autonomous agents capable of achieving optimal outcomes in complex scenarios.
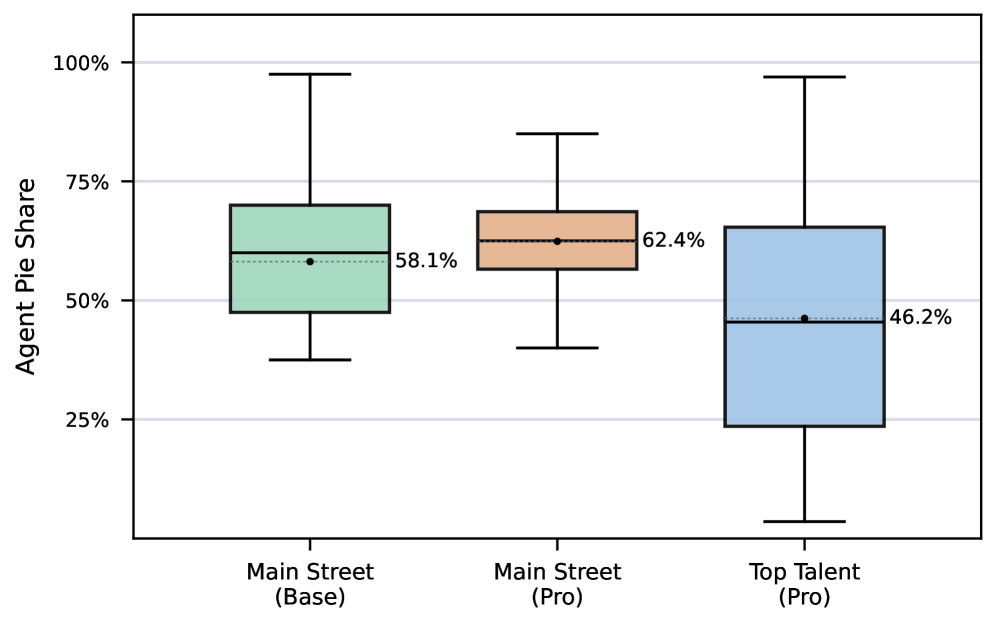
Recent investigations reveal that artificial intelligence agents are achieving performance levels competitive with, and sometimes exceeding, those of human negotiators in maximizing total joint gains. These agents, evaluated using the GGBTL model, demonstrate an aptitude for identifying mutually beneficial outcomes – effectively ‘growing the pie’ – in negotiation scenarios. This success isn’t simply about securing a larger share for themselves; the agents consistently generate outcomes where the combined benefit for all parties is substantial. The ability to consistently achieve these results suggests a capacity for strategic thinking and collaborative problem-solving that challenges conventional perceptions of automated negotiation, indicating that AI can move beyond simply claiming value to actively creating it.
Recent investigations into automated negotiation strategies demonstrate a compelling ability to not only generate substantial joint gains, but also to secure a comparable – and sometimes superior – share of those gains when interacting with human counterparts. This finding challenges conventional assumptions about the uniquely human capacity for strategic bargaining. Through rigorous analysis of ‘pie share’ – the proportion of total value claimed by each negotiator – certain models consistently achieve results statistically indistinguishable from, or exceeding, those of experienced human negotiators. This suggests these agents possess a level of strategic effectiveness capable of successfully navigating complex bargaining dynamics and optimizing their outcomes, hinting at the potential for AI to redefine negotiation best practices and potentially surpass human performance in this critical domain.
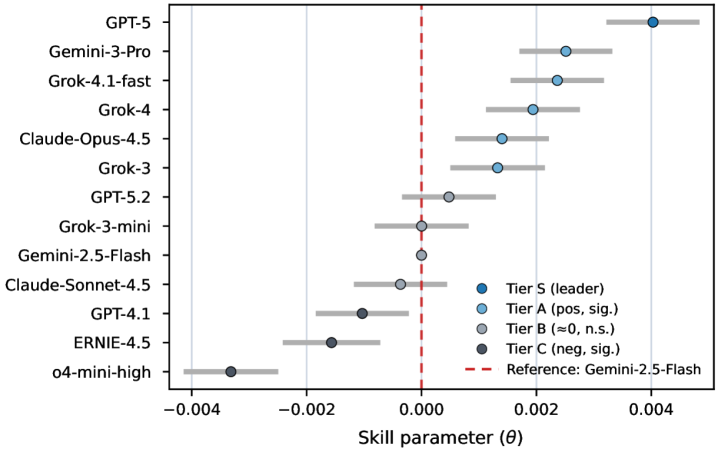
The Future of AI Negotiation: Beyond Current Benchmarks
PieArena establishes a novel environment for dissecting the complexities of multi-agent negotiation, moving beyond simple pairwise interactions to encompass scenarios demanding intricate coalition formation and adaptive deal-making. This platform allows researchers to investigate how agents can dynamically assess partner trustworthiness, identify mutually beneficial alliances, and adjust strategies in real-time as the negotiation landscape shifts. By simulating these complex interactions, PieArena facilitates the development of algorithms capable of not just claiming individual gains, but maximizing collective outcomes through strategic cooperation and the skillful navigation of evolving preferences – crucial steps toward creating AI negotiators that can thrive in real-world, multifaceted scenarios.
The next generation of AI negotiators demands a shift towards agents capable of thriving in environments characterized by ambiguity and change. Current benchmarks often assume perfect information and static preferences, a stark contrast to real-world negotiations where data is frequently incomplete and priorities can shift during the process. Future research must therefore prioritize developing algorithms that can effectively reason under uncertainty, employing techniques like Bayesian inference or reinforcement learning to estimate unknown variables and adapt to evolving circumstances. Successfully navigating incomplete information isn’t simply about filling gaps, but about intelligently assessing risk and strategically seeking clarification, while the ability to dynamically adjust preferences-perhaps modeling concepts like time pressure or opportunity cost-will be crucial for achieving mutually beneficial outcomes in complex, multi-faceted negotiations.
Successfully deploying artificial intelligence in negotiation requires a deep understanding of how humans perceive and react to these digital counterparts. Current research indicates that individuals don’t evaluate AI negotiators solely on outcome; factors like perceived fairness, transparency of strategy, and even the ‘personality’ expressed through communication style significantly influence acceptance and trust. Consequently, integrating principles from Human-Computer Interaction and behavioral economics is paramount; studies must move beyond simply measuring success rates to analyze subjective human responses – including emotional reactions, perceptions of deception, and willingness to engage in future negotiations. This necessitates designing AI negotiators that are not only strategically proficient but also attuned to human social cues and capable of fostering collaborative, rather than adversarial, interactions to unlock the full potential of AI in complex deal-making scenarios.
Determining the frequency of deceptive statements and verifying the factual accuracy of outputs are proving to be powerful diagnostic tools in the development of artificial intelligence negotiators. By meticulously analyzing an agent’s ‘lie rate’ – the instances where stated preferences diverge from actual valuations – and rigorously assessing the validity of proposed deals, researchers gain critical insights into the underlying mechanisms driving its behavior. This process isn’t simply about detecting dishonesty; it reveals whether an agent is employing strategic misrepresentation, exhibiting flawed reasoning, or struggling with information processing. Consequently, a detailed understanding of these patterns allows for targeted improvements in agent design, fostering greater transparency and building trust – essential components for successful human-AI collaboration in complex negotiation scenarios.
The emergence of language model agents capable of MBA-level negotiation, as detailed in PieArena, underscores a critical shift in AI evaluation. It isn’t merely about achieving a successful outcome, but demonstrating how that outcome is reached. As Robert Tarjan once stated, “The real problem is not to find a solution, but to understand why it works.” This sentiment aligns perfectly with the study’s focus on saturation-resistant evaluation; simply exceeding human performance is insufficient. PieArena strives to reveal the underlying reasoning driving agent success-or failure-in complex, interactive settings, offering a platform to probe the core mechanics of strategic decision-making and validating if the solutions are provably correct, rather than merely functioning on test cases.
What’s Next?
The demonstration that language model agents can achieve parity with, or even surpass, human performance in a constructed negotiation environment, while superficially impressive, merely shifts the focus of inquiry. The true challenge lies not in replicating human fallibility – the biases, emotional responses, and cognitive shortcuts – but in exceeding it through demonstrably optimal strategies. PieArena provides a useful testing ground, yet the benchmark’s saturation resistance, while laudable, does not address the fundamental question of scalability. An algorithm that functions flawlessly with a handful of agents negotiating over a single divisible good does not necessarily generalize to scenarios with thousands of agents and multiple, interdependent resources.
Future work must prioritize the development of provably optimal negotiation algorithms, assessed not by empirical results on finite datasets, but by rigorous mathematical analysis of their asymptotic behavior. The current emphasis on ‘behavioral differences’ risks mistaking emergent complexity for genuine intelligence. A nuanced understanding of game-theoretic equilibria, coupled with a commitment to formal verification, is paramount.
Ultimately, the field should abandon the pursuit of ‘human-like’ AI in favor of solutions that embrace the logical elegance inherent in pure mathematical reasoning. The goal is not to build machines that simulate rationality, but to construct systems that embody it – even if that results in strategies that appear, to human observers, counterintuitive or even ‘unfair.’
Original article: https://arxiv.org/pdf/2602.05302.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Games That Faced Bans in Countries Over Political Themes
- Gold Rate Forecast
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- The Best Directors of 2025
2026-02-09 03:10