Author: Denis Avetisyan
A new approach leverages machine learning to anticipate critical failures in marine diesel engines, offering a pathway to prevent costly downtime and damage.

This review details a method for early fault diagnosis using predicted sensor behavior and analysis of derivatives of deviation, improving condition-based maintenance strategies.
Sudden catastrophic failures pose a critical threat to marine diesel engines, often occurring with little warning and causing severe damage. This research, detailed in ‘On Using Machine Learning to Early Detect Catastrophic Failures in Marine Diesel Engines’, introduces a novel method for anticipating these events by leveraging machine learning to analyze the derivatives of deviations between predicted and actual sensor readings. This approach enables earlier anomaly detection than traditional threshold-based systems, potentially allowing for preventative engine shutdown and route adjustments. Could this proactive fault diagnosis significantly improve maritime safety and operational efficiency by shifting from reactive repair to predictive maintenance?
Unraveling the Architecture of Failure
Catastrophic failure, the abrupt and unintended loss of a component’s ability to perform its intended function, represents a critical concern across diverse sectors, from aerospace and automotive engineering to power generation and manufacturing. These events are rarely isolated incidents; instead, they frequently trigger cascading effects, impacting entire systems and potentially leading to substantial financial losses, operational downtime, and, in the most severe cases, posing significant risks to human life and environmental wellbeing. Unlike gradual degradation, which allows for planned maintenance and replacement, catastrophic failures offer little to no warning, demanding robust preventative measures and advanced diagnostic techniques to mitigate their occurrence. The unpredictable nature of these events necessitates a proactive approach to risk management, emphasizing redundancy, rigorous testing protocols, and the implementation of condition monitoring systems designed to detect subtle precursors to complete component breakdown.
The economic and ecological repercussions of mechanical failure within marine diesel engine systems are substantial, impacting global trade and sensitive ocean environments. A single engine breakdown can halt shipping operations, causing delays in the delivery of goods and incurring significant financial losses through repair costs, downtime, and potential contractual penalties. Beyond the immediate economic impact, failures frequently result in the release of heavy fuel oil or lubricating oils into the marine environment. These spills pose a severe threat to marine life, coastal ecosystems, and local economies reliant on fisheries and tourism, necessitating costly and complex cleanup operations. The interconnected nature of global shipping means that even localized engine failures can trigger cascading effects across international supply chains, highlighting the critical need for robust preventative maintenance and failure mitigation strategies.
Bearing collapse represents a particularly insidious pathway to mechanical failure across diverse engineering systems, yet often originates from subtle, initially undetectable processes. These critical events aren’t typically caused by sudden, dramatic breaks, but rather the gradual accumulation of wear, microscopic cracking, or the development of localized stress within the bearing’s components. This progressive degradation alters the bearing’s intended function, increasing friction, generating heat, and ultimately reducing its load-carrying capacity. Without timely detection – through methods like vibration analysis, oil debris monitoring, or temperature tracking – these seemingly minor changes escalate until the bearing’s structural integrity is compromised, leading to catastrophic failure and potentially widespread system disruption. The challenge lies in identifying these precursors to collapse before they manifest as overt symptoms, demanding proactive maintenance strategies and advanced diagnostic techniques.
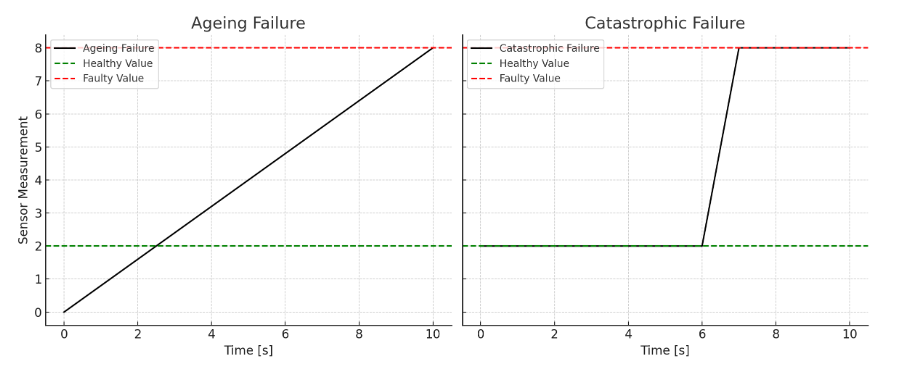
Beyond Reaction: The Architecture of Prediction
Traditional condition monitoring frequently employs time-based maintenance schedules, where equipment is inspected at predetermined intervals regardless of actual operational state. This reactive approach inherently limits the ability to detect gradual degradation or subtle anomalies that develop between inspections. Consequently, early warning signs of potential failures are often missed, as deviations from normal operation may not accumulate sufficiently to trigger alarms or exceed established thresholds before a critical event occurs. This reliance on scheduled checks introduces a delay in identifying developing issues, increasing the risk of unexpected downtime and potentially costly repairs, particularly in complex systems where failure modes are not always immediately apparent during routine visual inspections.
Continuous monitoring of key performance indicators (KPIs) offers a proactive alternative to scheduled inspections by providing a real-time assessment of system health. This methodology involves the persistent collection and analysis of relevant data points, enabling the identification of subtle performance drifts that might precede component failure. Sophisticated analytical tools, including statistical process control, machine learning algorithms, and time-series analysis, are then applied to this continuous data stream. These tools can establish baseline performance levels, detect deviations from expected behavior, and predict potential failures before they occur, thereby reducing downtime and maintenance costs. The efficacy of this approach relies on selecting appropriate KPIs representative of system health and employing analytical techniques capable of discerning meaningful anomalies from normal operational variance.
The Derivative of Deviation (DoD) offers improved anomaly detection capabilities by focusing on the rate of change in the difference between a system’s measured value and its expected value. Traditional monitoring relies on static thresholds or alarm signals triggered when a value exceeds a predetermined limit; however, the DoD identifies subtle, developing issues before they breach those thresholds. By calculating \frac{d}{dt}(MeasuredValue - ExpectedValue), the system highlights even small accelerations in deviations, indicating a potential future failure state. This proactive approach allows for earlier intervention and reduces the likelihood of unexpected downtime, as it doesn’t require a value to be definitively ‘wrong’ to generate a signal; instead, it flags changes towards a potentially erroneous state.
Our research employs a Variational Autoencoder (VAE) for both data augmentation and anomaly detection. The VAE learns a compressed, latent representation of normal operating conditions, enabling the generation of synthetic data to address data scarcity and improve model robustness. During inference, the reconstruction loss – measured at 2.792 in our experiments – quantifies the difference between the input data and its reconstructed output. A significant increase in this reconstruction loss indicates a deviation from learned normal behavior, signaling a potential anomaly. This approach allows for the identification of subtle anomalies that might be missed by traditional threshold-based methods, as the VAE is sensitive to deviations in the data distribution rather than absolute values.

Hy2Tech: Architecting Resilience in the Hydrogen Age
The emerging hydrogen economy hinges on the dependable performance of sophisticated mechanical systems – from high-pressure storage tanks and fuel cell stacks to electrolyzers and hydrogen pipelines. Recognizing this fundamental reliance, the IPCEI Hy2Tech program prioritizes the development of technologies that ensure these systems operate with unwavering robustness and longevity. Hydrogen, while promising as a clean energy carrier, presents unique challenges to material integrity and component durability due to its properties – including embrittlement and leak potential. Consequently, Hy2Tech focuses on bolstering the resilience of these critical mechanical elements, understanding that sustained public and investor confidence in hydrogen infrastructure is directly linked to demonstrable reliability and minimized risk of operational failure. This proactive stance is essential for scaling hydrogen technologies and realizing their full potential in a sustainable energy future.
The IPCEI Hy2Tech program prioritizes minimizing the potential for system failures within nascent hydrogen technologies through substantial investment in sophisticated monitoring and predictive maintenance. Recognizing that complex mechanical systems are integral to hydrogen applications – from production to storage and fuel cell operation – the initiative funds research dedicated to detecting subtle anomalies before they escalate into catastrophic events. This isn’t simply about reacting to breakdowns; it’s a proactive strategy leveraging sensor networks, data analytics, and machine learning algorithms to forecast component degradation and schedule maintenance precisely when needed. By anticipating and preventing failures, Hy2Tech not only bolsters the reliability and operational lifespan of hydrogen infrastructure, but also reduces costly downtime and reinforces the economic feasibility of this emerging energy sector.
The pursuit of hydrogen as a sustainable energy carrier demands more than just technological innovation; it requires demonstrable reliability. Investing in proactive strategies – such as advanced monitoring and predictive maintenance – directly addresses concerns surrounding the longevity and safety of hydrogen infrastructure. This focus isn’t simply about preventing component failure; it’s about building trust in a nascent technology. By minimizing downtime, maximizing operational lifespan, and establishing a clear path towards consistent performance, these efforts signal to investors, policymakers, and the public that hydrogen is a dependable and worthwhile long-term energy solution. Ultimately, this increased confidence is crucial for scaling hydrogen technologies and realizing its full potential in a cleaner energy future.
The pursuit of predictive maintenance, as detailed in the study of marine Diesel engines, necessitates a dismantling of conventional assumptions about engine health. This research doesn’t simply accept pre-defined failure points; instead, it actively seeks deviations from predicted sensor behavior, effectively reverse-engineering the engine’s operational ‘normal.’ Vinton Cerf aptly stated, “The Internet is not about technology; it’s about people.” Similarly, this approach isn’t solely about algorithms; it’s about understanding the language of the engine itself – its subtle shifts and anticipated responses. By focusing on the derivatives of deviation, the study reveals hidden patterns indicative of impending catastrophic failures, turning passive monitoring into a proactive interrogation of system integrity. It’s a methodology rooted in the belief that true insight comes from challenging established norms and probing for vulnerabilities.
What Breaks Down Next?
The presented methodology, while demonstrating predictive capability, fundamentally relies on the assumption that failure modes are – if not predictable in their timing – at least discernible in their manifestation within sensor data. This is a convenient, and potentially fragile, belief. The true test lies not in confirming existing failure signatures, but in identifying the unforeseen. Future work must actively court the anomalous – deliberately introducing noise and simulated, novel failure mechanisms to stress-test the system’s robustness. Only by attempting to break the predictive model can its true limitations be revealed.
Furthermore, the current approach, focused on derivative analysis of sensor deviations, treats the engine as a ‘black box’ – effectively mapping input-output relationships without necessarily understanding the underlying physics. This is pragmatic, but inherently incomplete. Integrating physics-informed machine learning – incorporating known engine characteristics into the model – could offer greater interpretability and, crucially, allow for prediction beyond the observed data. The question isn’t simply ‘will it fail?’, but ‘how will it fail, and what are the initiating conditions?’
Ultimately, the pursuit of perfect prediction is a fool’s errand. Complex systems will surprise. The real value lies in shifting the focus from prevention to mitigation – developing adaptive control systems that can rapidly respond to unexpected failures, even if they cannot be foreseen. If a machine is truly understood, it is not because its behavior is known, but because its points of weakness are systematically, and repeatedly, exploited.
Original article: https://arxiv.org/pdf/2603.12733.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Spotting the Loops in Autonomous Systems
- Seeing Through the Lies: A New Approach to Detecting Image Forgeries
- The Best Directors of 2025
- Staying Ahead of the Fakes: A New Approach to Detecting AI-Generated Images
- The Glitch in the Machine: Spotting AI-Generated Images Beyond the Obvious
- 20 Best TV Shows Featuring All-White Casts You Should See
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Gold Rate Forecast
- Umamusume: Gold Ship build guide
- Mel Gibson, 69, and Rosalind Ross, 35, Call It Quits After Nearly a Decade: “It’s Sad To End This Chapter in our Lives”
2026-03-16 08:07