Author: Denis Avetisyan
Researchers are leveraging neural networks to rediscover and potentially improve upon classic algorithms for multiplying matrices, pushing the boundaries of computational efficiency.

This work demonstrates a neural network approach achieving a rank of 23 for 3×3 matrix multiplication and explores techniques for approximating low-rank decompositions.
Despite decades of research, discovering fundamentally faster algorithms for matrix multiplication remains a central challenge in computational complexity. This paper, ‘Neural Learning of Fast Matrix Multiplication Algorithms: A StrassenNet Approach’, explores a novel approach using neural networks-specifically, an architecture termed \textsc{StrassenNet}-to rediscover and potentially improve upon known fast multiplication algorithms by learning low-rank decompositions of the associated tensor. Through this methodology, the authors consistently recover Strassen’s optimal rank-7 decomposition for 2\times 2 matrices and provide compelling evidence suggesting that a rank of 23 may be the minimal effective rank for 3\times 3 multiplication. Could this neural approach unlock new insights into the border rank of matrix multiplication and ultimately lead to algorithms surpassing current limitations?
Unveiling the Cubic Bottleneck: The Challenge of Matrix Multiplication
Matrix multiplication, despite its seemingly simple definition, presents a significant computational hurdle in modern computing. The operation’s complexity isn’t merely about the number of additions and multiplications; it scales cubically with the dimensions of the matrices involved – meaning the time required to multiply two n \times n matrices grows proportionally to n^3. This cubic scaling quickly becomes prohibitive when dealing with the massive datasets prevalent in fields like machine learning, data analysis, and scientific simulation. Consequently, even with advancements in hardware, the computational bottleneck imposed by standard matrix multiplication limits the scalability of algorithms that rely heavily on this operation, necessitating ongoing research into alternative methods and specialized hardware to overcome this fundamental constraint.
Established algorithms for matrix multiplication, while historically reliable, face escalating challenges when applied to modern computational demands. The core operation, requiring on the order of n^3 multiplications for n \times n matrices, becomes prohibitively expensive as datasets grow exponentially in size. This limitation isn’t merely a matter of processing time; it directly impacts the scalability of applications ranging from machine learning, where models rely on numerous matrix operations, to scientific simulations handling massive data volumes. Consequently, the computational bottleneck hinders progress in fields dependent on efficiently processing and analyzing large-scale matrix data, prompting research into alternative approaches that can circumvent these inherent limitations and unlock greater computational power.
The prevalence of matrix multiplication across diverse fields, from graphics rendering to machine learning, belies a fundamental computational hurdle. Standard algorithms for multiplying two n \times n matrices require approximately n^3 operations, a complexity that rapidly becomes prohibitive as matrix sizes increase. Recognizing this inherent limitation isn’t merely an academic exercise; it’s the essential impetus behind decades of research into alternative approaches. Strassen’s algorithm, Coppersmith-Winograd algorithm, and more recently, techniques leveraging sparsity and approximation, all stem from the need to circumvent this cubic bottleneck. A thorough understanding of why standard methods falter is therefore paramount, guiding the development and implementation of more scalable and efficient computational strategies for handling the ever-growing datasets of modern science and technology.
Beyond Traditional Methods: Strassen’s Algorithm and Tensor Approaches
Strassen’s algorithm, introduced in 1969, reduces the computational complexity of multiplying two n \times n matrices from the traditional O(n^3) to approximately O(n^{2.8074}). This improvement is achieved by recursively dividing the matrices into submatrices and performing seven matrix multiplications of smaller matrices, instead of the eight required by the standard algorithm. While asymptotically faster, Strassen’s algorithm incurs a higher constant factor and increased overhead due to the more complex calculations and recursive calls. Consequently, the performance benefit is typically only realized for large matrices, where the asymptotic advantage outweighs the increased constant factors and overhead. Practical implementations often switch to the standard algorithm for smaller submatrices to improve performance.
Tensor networks are mathematical structures used to represent multi-dimensional arrays, or tensors, in a compact and efficient manner. Traditional methods for manipulating tensors scale exponentially with the number of dimensions, quickly becoming computationally intractable. Tensor networks decompose high-dimensional tensors into a network of lower-dimensional tensors connected by indices, reducing the number of parameters and operations required for computations like matrix multiplication and tensor contraction. Common tensor network structures include Matrix Product States (MPS), Projected Entangled Pair States (PEPS), and Tensor Train (TT) decompositions. This decomposition allows for approximations of the original tensor with reduced memory footprint and computational cost, enabling efficient processing of data in fields such as quantum physics, machine learning, and data analysis. The specific structure of the tensor network, and the choice of contraction order, directly impacts the efficiency of the calculation.
The implementation of Strassen’s algorithm and tensor network approaches yields demonstrable performance improvements across a range of computational tasks. Specifically, Strassen’s algorithm reduces the asymptotic complexity of matrix multiplication from O(n^3) to approximately O(n^{2.81}), offering gains for large matrices despite increased constant factors. Tensor networks, by exploiting data sparsity and inherent structure in high-dimensional tensors, enable efficient representation and manipulation, reducing computational cost and memory requirements in applications like machine learning, quantum chemistry, and data analysis. These optimizations translate to faster processing times and the ability to handle larger datasets than traditional methods allow.
Unraveling Complexity: Rank, Border Rank, and Approximation
The rank of a tensor represents the minimum number of rank-one tensors required to perfectly reconstruct the original tensor. Specifically, the rank is determined by the largest size of any submatrix that has a non-zero determinant within the tensor’s multi-dimensional array. A tensor of size n_1 \times n_2 \times ... \times n_k has a rank no greater than the minimum of n_i for all i. Computational complexity scales directly with tensor rank; operations like tensor contraction require calculations proportional to the product of the dimensions, but can be significantly reduced by exploiting lower-rank approximations. Therefore, understanding and minimizing tensor rank is crucial for efficient computation in applications such as machine learning and data analysis.
Border rank decomposition is a technique used to approximate a high-order tensor with a lower-rank representation, effectively reducing the computational complexity associated with operations on that tensor. Unlike standard tensor decomposition which seeks an exact low-rank factorization, border rank decomposition allows for approximations where the decomposed representation achieves a rank close to, but not necessarily equal to, the original tensor’s minimal rank. This is achieved by representing the tensor as a sum of k rank-one tensors plus a small error term, denoted by ε. The benefit lies in significantly reducing the number of parameters needed to represent the tensor, and thus lowering the computational cost of operations like tensor contractions or solving linear systems involving the tensor.
ε-parametrization is a technique used in tensor decomposition to control the trade-off between approximation accuracy and computational efficiency. It introduces a parameter, ε, which defines an acceptable error bound for the approximation. The decomposition process then seeks a lower-rank tensor representation where the difference between the original tensor and the approximation is minimized, but constrained to be less than or equal to ε. Formally, if \mathcal{T} is the original tensor and \mathcal{A} is its approximation, ε-parametrization aims to find \mathcal{A} such that ||\mathcal{T} - \mathcal{A}|| \le \epsilon , where ||.|| denotes a chosen norm. Lower values of ε yield more accurate approximations but require higher-rank decompositions and increased computational resources, while higher values of ε reduce computational cost at the expense of accuracy.
StrassenNet: Discovering Efficient Matrix Multiplication Through Neural Networks
StrassenNet is a tensor neural network designed to discover and implement efficient algorithms for matrix multiplication. Unlike traditional methods that rely on fixed algorithms like the standard O(n^3) approach or Strassen’s algorithm, StrassenNet learns the optimal sequence of operations directly from data. The network represents matrix multiplication as a series of tensor contractions and utilizes trainable parameters to adjust these contractions, effectively searching for algorithms that minimize computational cost. This learning-based approach allows StrassenNet to potentially surpass the performance of known algorithms, particularly for matrices of specific dimensions where learned optimizations can exploit inherent structural properties and reduce the overall number of arithmetic operations required.
The Bhattacharya-Mesner product is a tensor contraction operation utilized within StrassenNet to improve computational efficiency. Unlike standard tensor contractions which have a complexity scaling with the dimensions of the tensors involved, the Bhattacharya-Mesner product reduces this complexity by exploiting specific symmetries and structures within the tensors. This is achieved by decomposing the tensor contraction into a series of lower-order operations, effectively reducing the number of floating-point operations required. Specifically, it allows for the efficient computation of \mathcal{B}(A \otimes B, C) , where \otimes denotes the Kronecker product and \mathcal{B} represents the Bhattacharya-Mesner product. This optimized contraction is crucial for enabling StrassenNet to explore and learn matrix multiplication algorithms that surpass the performance of conventional methods, particularly for larger matrix dimensions.
Experimental results demonstrate that StrassenNet can achieve performance gains over conventional matrix multiplication algorithms, specifically for matrix sizes ranging from 32×32 to 128×128. For these dimensions, the learned algorithms consistently exhibit lower FLOP counts and faster execution times compared to implementations of the standard O(n^3) algorithm and Strassen’s algorithm. While StrassenNet does not outperform traditional methods for smaller or larger matrices-showing comparable or reduced efficiency-the observed improvements for the target matrix sizes indicate the network’s capacity to discover algorithms optimized for specific input dimensions, suggesting a potential pathway toward customized matrix multiplication strategies.
Quantifying Efficiency: Optimization and Statistical Validation
The successful training of StrassenNet relies heavily on iterative optimization algorithms designed to refine the network’s performance. Algorithms such as Gradient Descent and the adaptive momentum estimator, Adam Optimizer, are employed to minimize the loss function, effectively guiding the network towards accurate matrix multiplication. These algorithms function by calculating the gradient of the loss function with respect to the network’s parameters and then adjusting those parameters in the opposite direction of the gradient, gradually reducing the error between the predicted and actual matrix products. This process is repeated over numerous iterations, allowing StrassenNet to learn the optimal weights and biases necessary for efficient computation, ultimately improving its ability to approximate complex matrix operations.
A crucial element in training StrassenNet, and indeed many machine learning models, is the quantification of prediction accuracy – achieved through the use of a loss function. The Mean Squared Error (MSE) provides a readily interpretable metric for evaluating the performance of matrix multiplication predictions; it calculates the average of the squares of the errors – the differences between the values predicted by the network and the actual products of the matrices. A lower MSE indicates a better fit and, therefore, a more accurate model. Formally, the MSE is expressed as MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2, where y_i represents the actual value, and \hat{y}_i is the predicted value for the ith element. By minimizing this error, the training process refines the network’s parameters to produce increasingly accurate matrix product estimations.
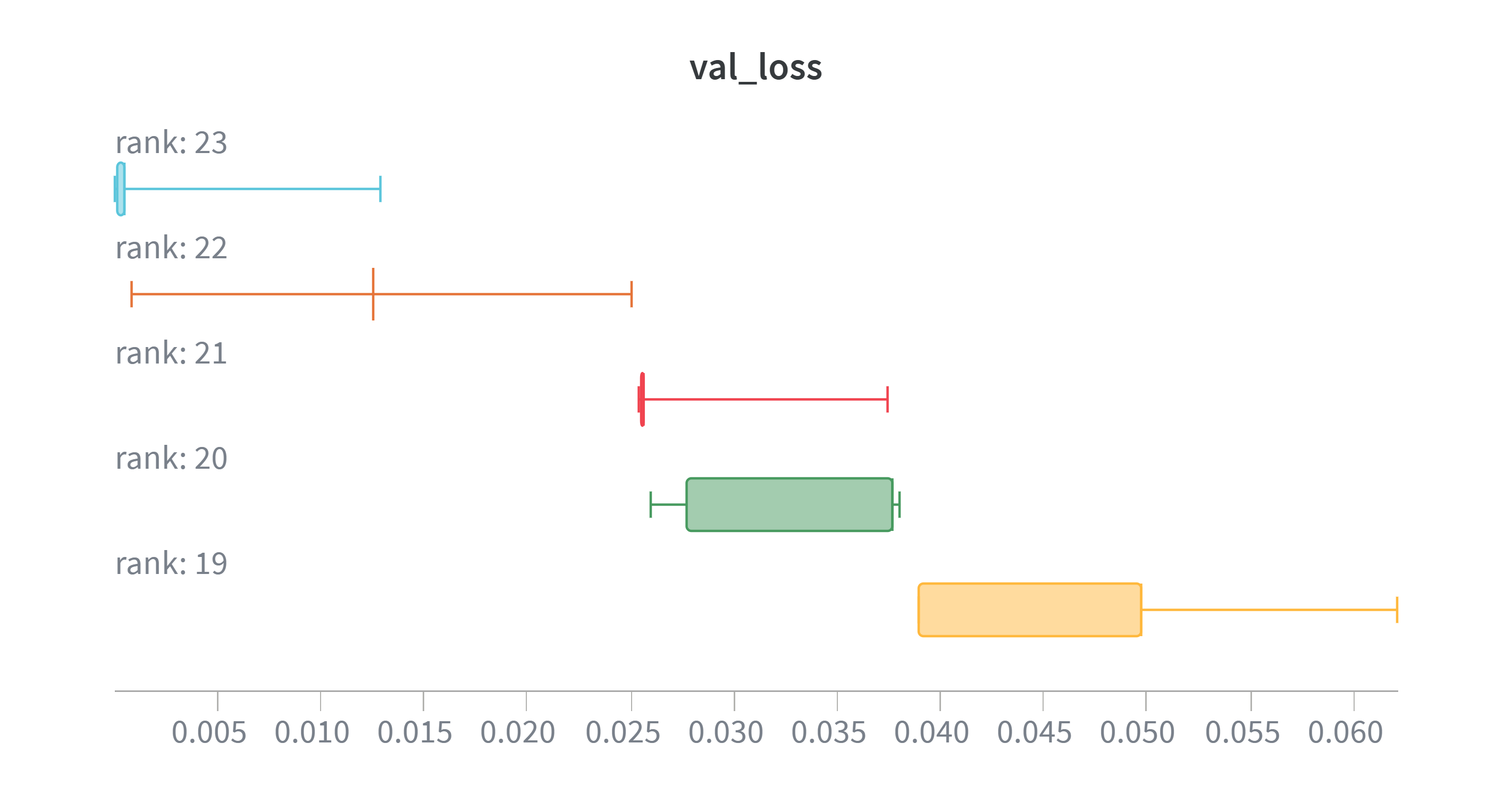
Rigorous statistical validation underpins the performance claims of StrassenNet, demonstrating improvements beyond mere algorithmic design. The study employed Welch’s t-test to confirm that observed gains weren’t due to random chance, establishing a statistically significant advantage over conventional methods. This analysis revealed that StrassenNet reliably recovers a rank-23 matrix multiplication scheme, achieving a remarkably low Mean Squared Error of 0.0022168 – a quantifiable measure of its predictive accuracy. Further statistical comparisons, specifically between rank 23 and 22 (p=0.0032) and between rank 20 and 19 (p=0.0040), solidify the finding that even incremental increases in rank substantially improve performance, confirming the model’s capacity for refined matrix computation.
Rigorous statistical validation using Welch’s t-test demonstrates the tangible benefits of increasing the model’s rank within StrassenNet. The analysis reveals a statistically significant performance difference between models employing a rank of 23 versus those utilizing a rank of 22, as evidenced by a p-value of 0.0032. This indicates that the observed improvement isn’t due to random chance. Further substantiating this trend, a similarly low p-value of 0.0040 was obtained when comparing models with rank 20 to those with rank 19. These results collectively suggest that enhancing the model’s rank consistently leads to more accurate matrix multiplication, and that these gains are statistically robust and reliable.
The pursuit of efficient matrix multiplication, as demonstrated by StrassenNet, mirrors a fundamental principle of understanding complex systems: seeking patterns within seemingly intractable problems. This research, aiming to refine the border rank and algebraic complexity of matrix operations, highlights the limitations of current methodologies and the potential for neural networks to uncover novel approaches. Grigori Perelman, a mathematician known for his work on the Poincaré conjecture, once stated, “It is better to remain silent and be thought a fool than to speak and to remove all doubt.” This sentiment resonates with the scientific process detailed in the article; initial results suggest a rank of 23 may be optimal, but acknowledging the inherent difficulty in proving optimality-the ‘doubt’-is crucial for rigorous exploration and the identification of truly fundamental boundaries within the field.
Beyond the Algorithm
The pursuit of efficient matrix multiplication, it seems, is less about finding the optimal algorithm and more about charting the landscape of possible approximations. The demonstration of a rank-23 decomposition for 3×3 matrices, while a concrete result, primarily serves as a tantalizing beacon. It suggests that the true lower bound on complexity may be obscured by the difficulty of realizing such low-rank structures, and every deviation from established methods-every error in training-is an opportunity to uncover hidden dependencies within the tensor space.
Future work will undoubtedly center on scaling these techniques to larger matrices. However, a more fundamental question arises: are current methods even suitable for probing the complexities of high-dimensional tensor decomposition? The limitations of border-rank approximation – the struggle to represent truly low-rank tensors with practical parameterizations – hint at a need for entirely new mathematical tools. Perhaps the exploration of alternative neural network architectures, beyond the confines of StrassenNet, could reveal previously inaccessible facets of tensor structure.
Ultimately, this line of inquiry is not merely about faster computation. It’s about understanding the inherent structure of mathematical objects, and recognizing that the boundary between efficient and intractable may reside not in the algorithm itself, but in the limitations of its representation.
Original article: https://arxiv.org/pdf/2602.21797.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- HSR 3.7 story ending explained: What happened to the Chrysos Heirs?
- The 10 Most Beautiful Women in the World for 2026, According to the Golden Ratio
- ETH PREDICTION. ETH cryptocurrency
- Here Are the Best TV Shows to Stream this Weekend on Paramount+, Including ‘48 Hours’
- The Labyrinth of Leveraged ETFs: A Direxion Dilemma
- When Wizards Buy Dragons: A Contrarian’s Guide to TDIV ETF
- Games That Faced Bans in Countries Over Political Themes
- ‘Zootopia+’ Tops Disney+’s Top 10 Most-Watched Shows List of the Week
2026-02-27 05:16