Author: Denis Avetisyan
Researchers have developed a novel framework that empowers large language models to independently explore and reason over knowledge graphs, dramatically improving their ability to answer complex questions.

Explore-on-Graph utilizes reinforcement learning and path-refined reward modeling to enhance autonomous exploration and achieve state-of-the-art knowledge graph question answering performance.
Despite advances in knowledge-grounded reasoning, large language models often struggle with factual accuracy and generalization in question answering. This work introduces ‘Explore-on-Graph: Incentivizing Autonomous Exploration of Large Language Models on Knowledge Graphs with Path-refined Reward Modeling’, a novel reinforcement learning framework designed to encourage LLMs to autonomously explore diverse reasoning paths on knowledge graphs. By incentivizing exploration with path-refined rewards, the approach achieves state-of-the-art performance on knowledge graph question answering benchmarks, exceeding even closed-source LLMs. Could this framework unlock more robust and adaptable reasoning capabilities in LLMs across a broader range of complex knowledge-intensive tasks?
The Erosion of Scale: Reasoning’s Limits in Language Models
Although Large Language Models demonstrate remarkable proficiency in various natural language tasks, their performance frequently falters when confronted with complex Question Answering scenarios due to inherent limitations in their internal knowledge representation. These models, while adept at identifying patterns and correlations within vast datasets, often struggle to synthesize information or draw inferences beyond their explicitly stored parametric knowledge. This results in “knowledge gaps” – areas where the model lacks the necessary information to formulate a correct or complete answer, even if that information is readily available in the broader world. Consequently, complex questions requiring multi-step reasoning, nuanced understanding, or the integration of disparate concepts often expose these limitations, hindering the model’s ability to provide accurate and reliable responses.
Large Language Models, while adept at statistically plausible text generation, frequently exhibit a disconcerting tendency toward hallucination – the confident presentation of factually incorrect information. This arises not from intentional deceit, but from the models’ fundamental reliance on parametric knowledge – the information encoded within the vast network of weights and biases learned during training. Unlike humans who integrate learned facts with external knowledge and reasoning, these models essentially predict the most probable continuation of a text sequence. Consequently, if a plausible but inaccurate statement aligns with the training data’s statistical patterns, the model may generate it as confidently as a truthful one. This limitation highlights a crucial distinction: the models excel at mimicking knowledge, but lack a grounded understanding of truth, making verification and reliability significant challenges in practical applications.
Large language models, while proficient at identifying patterns and generating text, frequently demonstrate limitations when confronted with reasoning tasks demanding more than simple recall. The difficulty arises from a reliance on statistical correlations within their training data, rather than a capacity for genuine, step-by-step deduction. Consequently, these models struggle to reliably navigate complex information landscapes – scenarios requiring the integration of multiple facts, the application of logical rules, or the consideration of nuanced relationships. Unlike human reasoning, which builds upon a foundation of structured knowledge and inferential capabilities, the models often falter when presented with novel situations or questions that require going beyond the explicitly stated information, highlighting a critical gap in their ability to perform robust and dependable reasoning.

Externalizing Reasoning: The Promise of Knowledge Graphs
Knowledge graphs function as structured representations of information, utilizing nodes to denote entities and edges to define relationships between them. This structure allows for the explicit storage of facts-statements about entities and their connections-and facilitates the representation of complex, interconnected data beyond the scope of a Large Language Model’s (LLM) parametric knowledge. By externalizing knowledge in this manner, LLMs can access and integrate factual information during inference, supplementing their internally stored data and enabling responses grounded in verifiable evidence. The graph format supports a diverse range of relationships – hierarchical, associative, temporal, and others – offering a flexible schema for representing domain-specific knowledge and facilitating more nuanced reasoning capabilities.
Grounding Large Language Model (LLM) reasoning in structured knowledge bases directly addresses the problem of hallucination – the generation of factually incorrect or nonsensical outputs. LLMs, trained on massive text corpora, can statistically generate plausible-sounding but ultimately untrue statements. By requiring the LLM to consult and validate information against a defined knowledge graph, the model is constrained to outputs supported by documented facts and relationships. This external validation process significantly reduces the likelihood of fabricating information and correspondingly improves the accuracy and reliability of generated responses. The knowledge graph serves as a source of truth, enabling the LLM to differentiate between learned statistical patterns and verified knowledge, ultimately leading to more trustworthy results.
Breadth-First Search (BFS) is an efficient algorithm for traversing knowledge graphs and constructing reasoning paths by systematically exploring nodes level by level. Starting from a given node, BFS prioritizes visiting all immediate neighbors before moving to the next level of connections. This approach ensures that the shortest path, in terms of the number of relationships traversed, is identified when seeking connections between entities within the graph. The algorithm maintains a queue of nodes to visit, processing each node and adding its unvisited neighbors to the queue. This iterative process continues until the target node is found or the entire relevant portion of the knowledge graph has been explored, making BFS particularly well-suited for tasks requiring the discovery of direct or closely-related information.
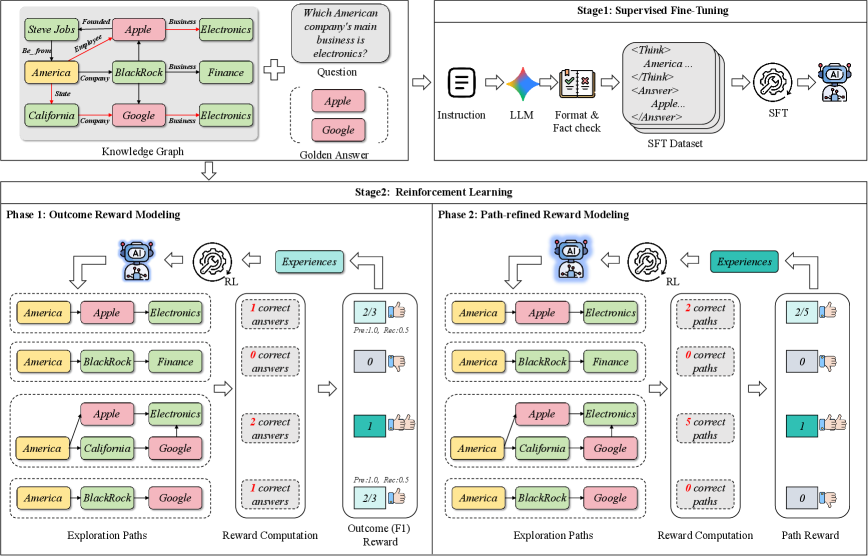
Autonomous Exploration: Guiding Reasoning with Reinforcement Learning
The Explore-on-Graph framework addresses the limitations of Large Language Models (LLMs) in complex reasoning tasks by integrating Reinforcement Learning (RL) to facilitate autonomous Knowledge Graph (KG) exploration. This approach moves beyond static KG traversal by training an RL agent to dynamically select which nodes and edges within the KG an LLM should query to answer a given question. The RL agent receives feedback based on the LLM’s performance, effectively incentivizing the discovery of relevant information and optimized reasoning paths within the KG. This allows the LLM to move beyond its pre-trained knowledge and actively seek information necessary for accurate and efficient problem-solving, ultimately improving its reasoning capabilities on tasks requiring external knowledge sources.
Group Relative Policy Optimization (GRPO) builds upon standard Reinforcement Learning (RL) techniques by addressing challenges inherent in exploring complex Knowledge Graphs. Traditional RL often struggles with sparse rewards and the need for efficient exploration in high-dimensional state spaces. GRPO introduces a relative policy update, focusing on the performance difference between multiple exploration paths rather than absolute reward values. This relative comparison stabilizes training and accelerates convergence, particularly in scenarios where reward signals are delayed or infrequent. By optimizing for relative improvement, GRPO enables the agent to more effectively refine its exploration policy and identify optimal reasoning paths within the Knowledge Graph, leading to improved performance compared to standard RL algorithms.
The Explore-on-Graph framework employs a Path-Refined Reward signal to guide autonomous Knowledge Graph exploration. This reward function considers not only the correctness of the final answer but also the efficiency and validity of the reasoning path taken to reach that answer. Evaluation across multiple datasets demonstrates state-of-the-art performance, achieving a Hit@1 score of 81.5 ± 0.33 and an F1 score of 81.5 ± 0.33, indicating improved accuracy and reasoning capability compared to existing methods.

Sculpting the Process: Supervised Fine-Tuning for Reasoning Proficiency
Supervised Fine-Tuning (SFT) enhances Large Language Model (LLM) reasoning capabilities by training the model on datasets comprising demonstrations of desired reasoning processes. Techniques like Long Context Chain-of-Thought (Long CoT) extend the standard Chain-of-Thought prompting by providing more extensive examples of step-by-step reasoning, allowing the LLM to learn complex patterns from longer sequences. During SFT, the LLM adjusts its internal parameters to predict the next token in these demonstrated reasoning paths, effectively learning to mimic the provided reasoning style. This process differs from pre-training, as it focuses on shaping the model’s reasoning process rather than general language understanding, and provides a targeted improvement in the model’s ability to solve reasoning-intensive tasks.
Pre-training an agent with high-quality reasoning examples establishes a beneficial prior for subsequent learning phases. This process involves exposing the language model to a dataset of problems paired with step-by-step reasoning traces, enabling it to learn patterns associated with successful problem-solving. The agent’s initial exploration strategy is then biased towards these demonstrated reasoning pathways, reducing the need for extensive random exploration and accelerating convergence during reinforcement learning or other autonomous refinement stages. This approach effectively initializes the agent with a functional, albeit potentially incomplete, understanding of effective reasoning techniques, leading to improved sample efficiency and performance on complex tasks.
Supervised fine-tuning, implemented as a pre-training step for Reinforcement Learning (RL), establishes a robust initial policy for the language model agent. This pre-training mitigates the challenges of early-stage RL exploration by providing the agent with demonstrated examples of successful reasoning. Consequently, the RL process focuses on refinement and adaptation of existing competencies rather than discovering fundamental reasoning strategies. This approach accelerates learning, improves sample efficiency, and enables the agent to achieve higher performance levels with fewer interactions during the RL phase. The pre-trained policy serves as a strong prior, guiding the agent’s exploration towards more promising solution spaces.

Toward Robust Intelligence: The Future of Reasoning Systems
Current large language models, while proficient at generating text, often struggle with tasks requiring reliable reasoning and factual accuracy. These models can be susceptible to generating plausible but incorrect answers due to their reliance on statistical patterns within training data. However, integrating these models with Knowledge Graphs-structured representations of facts and relationships-offers a powerful solution. By grounding language in a verifiable web of knowledge, this combined approach allows AI systems to not only generate answers, but also to validate them against established facts. This synergy leverages the strengths of both paradigms: the linguistic fluency of LLMs and the logical rigor of Knowledge Graphs, ultimately paving the way for more robust, accurate, and trustworthy artificial intelligence.
The Explore-on-Graph framework offers a promising route toward artificial intelligence systems distinguished by their reliability, precision, and transparency. This approach leverages the strengths of knowledge graphs – structured networks of facts and relationships – to guide the reasoning process of large language models. Rather than relying solely on statistical patterns within text, the framework allows the AI to ‘explore’ relevant knowledge within the graph, grounding its responses in verifiable information. Coupled with supervised pre-training, which refines the model’s ability to navigate and interpret this knowledge, the result is a system less prone to generating unsupported claims or illogical conclusions. This methodology not only enhances the accuracy of AI responses but also provides a clear audit trail, enabling users to understand why a particular answer was reached, thereby fostering trust and accountability.
The convergence of large language models with knowledge graphs promises substantial progress across several key application areas. Advancements in question answering systems are anticipated, moving beyond simple fact retrieval to nuanced understanding and reasoning. Furthermore, this approach facilitates more effective knowledge discovery, enabling the identification of previously unseen connections and insights within complex datasets. Crucially, it offers a pathway to tackle complex problem-solving tasks that demand logical inference and contextual awareness. Realizing these capabilities, however, necessitates significant computational resources; initial training of the model required 509.6 GPU hours utilizing the CWQ dataset and an additional 119.2 GPU hours on the WebQSP dataset, highlighting the demanding nature of building such robust and explainable AI systems.

The pursuit of enhanced autonomous exploration, as demonstrated by Explore-on-Graph, inevitably introduces complexities. Every abstraction carries the weight of the past, and the framework’s reliance on path-refined reward modeling reflects this principle. While EoG achieves state-of-the-art performance in knowledge graph question answering, the system’s longevity depends on its ability to adapt to evolving knowledge. As Paul Erdős observed, “A mathematician knows a lot of things, but a physicist knows a few.” This suggests a focus on core principles-in this case, robust exploration strategies-rather than exhaustive coverage, ensuring the system ages gracefully even as the underlying knowledge graph expands and changes. The framework’s success isn’t merely about immediate results, but about its resilience over time.
What Lies Ahead?
The framework presented here, while demonstrating enhanced autonomous exploration, merely delays the inevitable entropy. Knowledge graphs, however meticulously constructed, are static representations of a dynamic reality. The true challenge isn’t simply navigating existing knowledge, but adapting to its constant decay and reformation. Explore-on-Graph offers a more efficient path through the current landscape, yet it does not fundamentally alter the fact that the map will never perfectly reflect the territory.
Future work will likely focus on integrating mechanisms for continual learning, allowing these models to not only explore but also revise their understanding of the knowledge graph. The current emphasis on reward modeling, while effective, is predicated on the assumption of a stable ‘correct’ answer. A more nuanced approach might explore rewarding not just accuracy, but also the process of adaptation – the ability to gracefully incorporate new information and discard outdated assumptions.
Ultimately, the pursuit of autonomous exploration in knowledge graphs is a symptom of a larger ambition: to create systems that can reason effectively in a world defined by uncertainty. Stability, in this context, isn’t a destination, but a temporary reprieve. The question isn’t whether these systems will eventually fail, but how elegantly they will age.
Original article: https://arxiv.org/pdf/2602.21728.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Silver Rate Forecast
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- The Best Former NFL Players Turned Actors, Ranked
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- ONE PIECE Season 2 Confirms Sanji’s OTHER Backstory in the Live-Action
2026-02-26 14:15