Author: Denis Avetisyan
Researchers are shifting the focus from directly identifying AI-generated images to better understanding what constitutes a ‘real’ image, leading to more reliable detection methods.

SimLBR utilizes latent blending regularization to define a robust boundary around authentic images, improving generalization and reliability in AI-generated image detection.
Despite advances in generative modeling, current fake image detection methods frequently overfit and fail when faced with distribution shifts. This work introduces ‘SimLBR: Learning to Detect Fake Images by Learning to Detect Real Images’, a novel framework that prioritizes learning a robust decision boundary around real images, effectively treating fake images as outliers. By employing Latent Blending Regularization, SimLBR achieves significant improvements in cross-generator generalization, alongside substantial gains in efficiency and reliability. Could this approach of focusing on ‘realness’ rather than ‘fakery’ represent a fundamental shift in how we assess the trustworthiness of digital images?
The Erosion of Visual Truth: A Challenge to Algorithmic Certainty
The proliferation of sophisticated generative models, particularly Generative Adversarial Networks (GANs) and Diffusion Models, is rapidly eroding the boundaries between authentic and synthetic imagery. These algorithms, fueled by advancements in deep learning, no longer simply reproduce images; they create entirely novel visuals with astonishing fidelity. Early iterations produced easily discernible artifacts, allowing for relatively straightforward detection. However, contemporary models now generate images that are increasingly indistinguishable from photographs captured by conventional means, even under close scrutiny. This accelerating realism poses a significant challenge across numerous domains, from journalism and social media to legal proceedings and national security, as the potential for malicious use – including disinformation campaigns and identity theft – expands alongside the technology’s capabilities.
Conventional methods for detecting AI-generated images often falter when faced with novel generative models or subtly altered content. These techniques, frequently reliant on identifying specific artifacts or statistical anomalies inherent to known generators, demonstrate limited ability to generalize beyond their training data. Consequently, a detector proficient at flagging images from one Generative Adversarial Network (GAN) may prove remarkably ineffective against a different, yet equally convincing, AI. This vulnerability is further exacerbated by the increasing sophistication of diffusion models, capable of producing perceptually realistic images that skillfully evade detection by exploiting the limitations of existing anomaly-based approaches. The result is an ongoing arms race, demanding more robust and adaptable detection strategies to counter the ever-improving realism of AI-synthesized visuals.
Current anomaly detection methods, while effective at flagging grossly distorted or unrealistic images, frequently stumble when confronted with the sophisticated manipulations characteristic of AI-generated content. These techniques often rely on identifying statistical outliers – deviations from the expected distribution of natural images – but generative models are now capable of producing outputs that convincingly mimic this distribution, masking subtle artifacts. The issue isn’t necessarily a lack of detectable flaws, but rather that these imperfections are increasingly imperceptible to existing algorithms, which lack the granular sensitivity to differentiate between genuine photographic nuances and the model’s attempts at replication. Consequently, systems designed to identify fakes often misclassify AI-generated images as authentic, highlighting a critical need for detection methods capable of discerning increasingly refined and realistic manipulations.

SimLBR: A Latent Space Formulation for Robust Classification
SimLBR utilizes DINOv3, a self-supervised vision transformer pretrained on a large dataset, to generate a Latent Space representation of input images. This process involves extracting high-dimensional feature vectors that capture semantic information about image content, rather than relying on raw pixel values. DINOv3’s self-distillation training objective encourages the learning of robust and transferable features, resulting in a Latent Space where similar images are clustered closely together, and dissimilar images are well-separated. By projecting images into this Latent Space, SimLBR effectively reduces the dimensionality of the input data while preserving crucial semantic information relevant for object detection and adversarial robustness.
Traditional image analysis methods often rely on pixel-level comparisons, which are susceptible to noise, minor alterations, and adversarial attacks. SimLBR circumvents these limitations by performing detection within the Latent Space generated by the DINOv3 feature extractor. This approach shifts the focus from analyzing raw pixel data to identifying discrepancies in high-level, semantic features. By operating on these abstracted features, the system becomes more robust to perturbations that would significantly impact pixel-level analyses, enabling it to better distinguish between genuine and manipulated images based on underlying content rather than superficial details.
Latent Blending Regularization (LBR) operates by creating blended latent representations during training. This is achieved by linearly interpolating between the latent features of real and fake images, generating synthetic latent vectors. The detector is then trained to discern these blended representations from authentic latent features of real images. This process forces the detector to focus on subtle, high-level discrepancies between real and fake data, rather than relying on easily manipulated pixel-level characteristics. By explicitly exposing the detector to these intermediate latent states, LBR improves its generalization capability and robustness against adversarial examples and out-of-distribution samples.
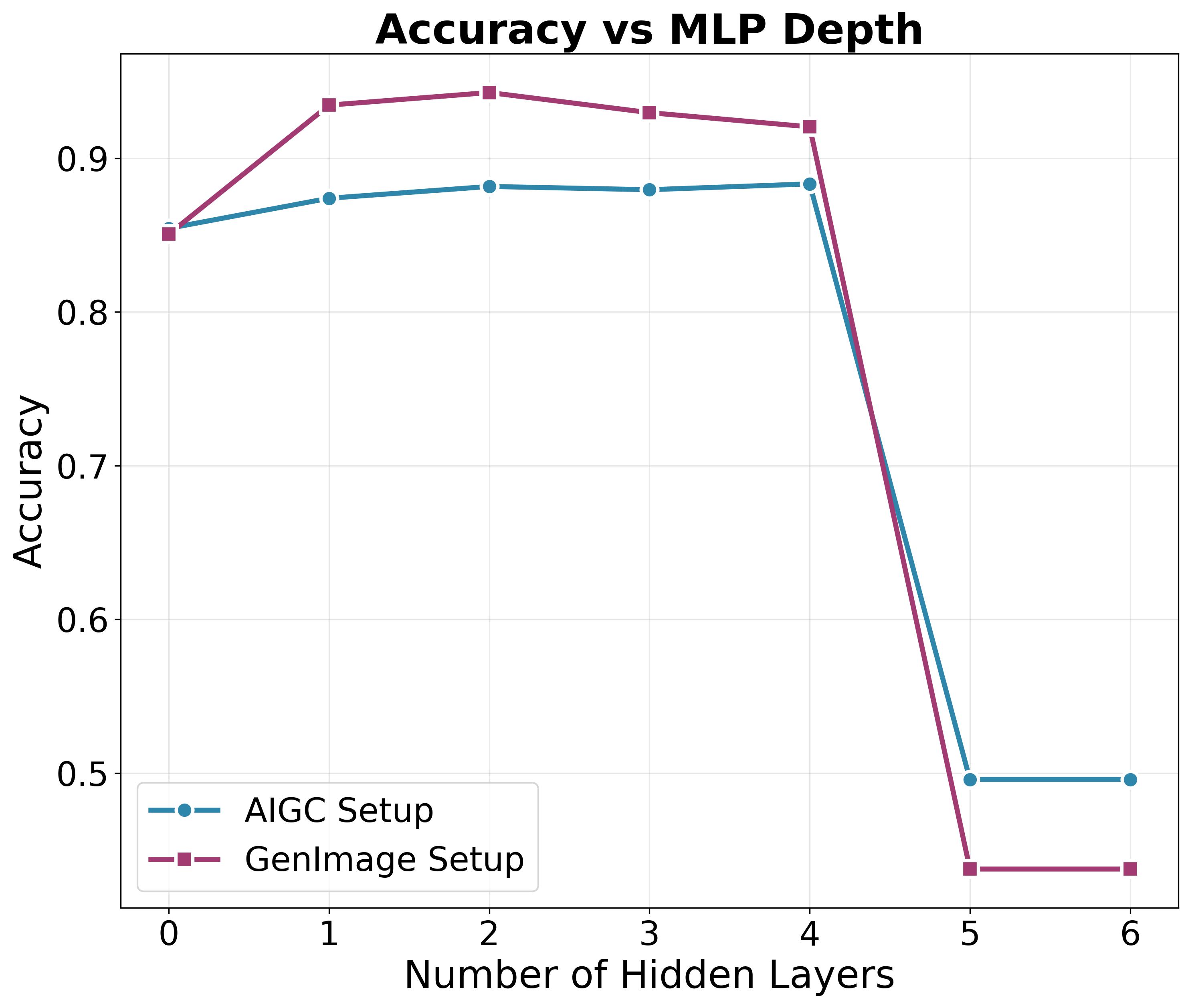
Empirical Validation: Performance on Challenging Benchmarks
SimLBR’s robustness was evaluated using the Chameleon, RSFake-1M, and GenImage datasets, revealing performance advantages over existing methods. Specifically, on the Chameleon dataset, SimLBR achieved accuracy gains of up to 25% compared to baseline detectors. These results indicate a heightened ability to correctly identify manipulated images across diverse generation techniques and potential adversarial attacks, demonstrating improved generalization capability and resistance to overfitting commonly observed in competing systems. The use of these datasets, each representing unique challenges in fake image detection, provides a comprehensive assessment of SimLBR’s reliability.
The Reliability Score metric assesses a detector’s consistency across diverse generative models, revealing that SimLBR exhibits stable performance regardless of the generator used. Unlike many existing detectors, which demonstrate significant performance degradation when evaluated on generators differing from their training data – indicating overfitting – SimLBR maintains consistent accuracy. This is evidenced by its stable Reliability Score across a range of generators, suggesting a greater capacity for generalization and robustness to variations in image generation techniques. The metric quantifies the standard deviation of performance across generators, with lower scores indicating more reliable detection capabilities, a characteristic strongly demonstrated by SimLBR.
Evaluation of SimLBR on the GenImage dataset yielded an accuracy of 94.54%. This result represents a 7.66% improvement over the performance of existing state-of-the-art methods on the same dataset. The GenImage dataset is utilized to assess the detector’s ability to generalize to images generated by diverse generative models, and SimLBR’s performance indicates a substantial advancement in this capacity. This accuracy level was achieved using a standardized evaluation protocol to ensure comparability with previously published results.
SimLBR demonstrates a substantial reduction in training time when compared to the AIDE detector. Utilizing a comparable hardware configuration of eight NVIDIA A100 GPUs, SimLBR completes training in under 3 minutes. This represents a significant efficiency gain, as AIDE requires approximately 2 hours to achieve comparable training on the same hardware. This accelerated training time allows for faster iteration and experimentation during development and deployment phases.
Worst-case performance analysis of SimLBR indicates a marked ability to maintain accuracy even when presented with adversarial or deceptive image manipulations. This robustness is quantified by achieving the highest reported worst-case accuracy on benchmark datasets. This metric assesses performance under the most challenging conditions, focusing on scenarios designed to intentionally mislead the detector. The results demonstrate that SimLBR minimizes accuracy degradation when confronted with these intentionally manipulated images, exceeding the performance of existing detection methods under similar conditions.
SimLBR achieves a 10% accuracy improvement when evaluated against out-of-distribution image generators, specifically utilizing the GenImage dataset. This performance gain indicates a substantial advancement over baseline models in generalizing to generators with differing architectural designs and training procedures. The ability to maintain accuracy across diverse generative models highlights SimLBR’s robustness and reduced reliance on specific generator characteristics, demonstrating a key strength in real-world deployment scenarios where the source of generated images may vary.

Beyond Detection: Towards a Principled Understanding of Visual Integrity
The efficacy of SimLBR in identifying manipulated images underscores a powerful shift in fake image detection: moving beyond pixel-level analysis to embrace semantic understanding. By utilizing pretrained feature extractors – models already trained on vast image datasets – the framework effectively bypasses the need to learn low-level image characteristics from scratch. This approach allows SimLBR to operate within a ‘Latent Space’, a high-dimensional representation where images are defined by their meaning rather than their specific pixel arrangements. Consequently, the system demonstrates improved generalization to unseen manipulation types and greater robustness against adversarial attacks, as it focuses on detecting inconsistencies in the underlying semantic structure of an image rather than subtle pixel artifacts. This reliance on semantically rich representations offers a promising pathway towards more reliable and adaptable fake image detection technologies.
The demonstrated generalization and robustness of SimLBR extend its potential far beyond simple fake image detection. This framework offers a powerful tool for content authentication across various digital platforms, enabling verification of media integrity and combating the spread of misinformation. Furthermore, its capacity to reliably identify manipulated imagery has significant implications for security monitoring applications, where accurate identification of altered evidence or fabricated scenarios is crucial. Beyond identifying obvious forgeries, SimLBR’s approach promises to detect subtle manipulations designed to bypass traditional detection methods, offering a proactive defense against increasingly sophisticated threats in both the digital information landscape and critical security infrastructures.
The SimLBR framework’s development is not reaching a conclusion, but rather transitioning to more complex media formats. Current research prioritizes extending its capabilities beyond static images to encompass the challenges presented by video and three-dimensional content, areas where subtle manipulations are considerably more difficult to detect. Simultaneously, investigations are underway to refine the regularization techniques employed within SimLBR. These adaptive methods aim to dynamically adjust the model’s learning process, potentially leading to improved generalization and robustness – particularly when confronted with increasingly sophisticated forms of digital forgery and manipulation. This continued development promises a future where content authentication systems are more resilient and versatile, capable of safeguarding against a wider spectrum of threats to digital integrity.
The pursuit of reliable AI-generated image detection, as demonstrated by SimLBR, hinges on establishing a provably correct boundary between real and synthetic data. This isn’t merely about achieving high accuracy on benchmark tests; it’s about crafting a solution grounded in mathematical principles. As David Marr aptly stated, “A good theory explains a lot with a little.” SimLBR, with its latent blending regularization, exemplifies this by distilling the essential characteristics of real images into a compact, learnable representation. This approach isn’t about adding complexity; it’s about revealing the underlying invariant properties that define authenticity, creating a decision boundary that isn’t empirically derived but mathematically justified.
What’s Next?
The presented framework, SimLBR, achieves a notable, if predictable, improvement through tighter constraint of the learned manifold. However, the fundamental problem remains: detection relies on discerning statistical artifacts, a game of cat and mouse with increasingly sophisticated generative models. A truly robust solution demands a departure from this empirical approach. The current reliance on latent space properties, while demonstrably effective, begs the question of what constitutes ‘real’. Defining this, axiomatically, is the necessary, though likely arduous, next step.
Future work must address the limitations inherent in anomaly detection. The framework implicitly assumes that deviations from the learned manifold signify fabrication. This assumption, while currently supported by empirical results, lacks mathematical grounding. A formal specification of ‘realness’ – perhaps rooted in information-theoretic principles or formal grammars of visual structure – could provide the necessary foundation. Such a definition would allow for provable guarantees of detection, rather than merely improved performance on benchmark datasets.
Ultimately, the pursuit of increasingly complex detectors is a palliative measure. The ideal solution is not to identify how an image is fake, but to establish, with mathematical certainty, whether it conforms to a definition of authentic visual information. Only then can the field transcend the limitations of pattern recognition and approach a truly elegant, and reliable, solution.
Original article: https://arxiv.org/pdf/2602.20412.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Gold Rate Forecast
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- HSR 3.7 story ending explained: What happened to the Chrysos Heirs?
- ETH PREDICTION. ETH cryptocurrency
- Games That Faced Bans in Countries Over Political Themes
- Gay Actors Who Are Notoriously Private About Their Lives
- The Best Actors Who Have Played Hamlet, Ranked
- USD PHP PREDICTION
- 9 Video Games That Reshaped Our Moral Lens
2026-02-26 02:30