Author: Denis Avetisyan
New research demonstrates a method for reliably identifying whether a language model was trained on a specific piece of data, raising critical privacy concerns.
This paper introduces Active Data Reconstruction Attack (ADRA), a reinforcement learning-based approach that outperforms existing methods for membership inference by reconstructing latent signals in model weights.
Detecting whether a given text was used to train a large language model remains a critical challenge, often framed as a passive inference problem. This work, ‘Learning to Detect Language Model Training Data via Active Reconstruction’, introduces a novel approach-Active Data Reconstruction Attack (ADRA)-that actively elicits latent membership signals by finetuning a language model to reconstruct candidate texts. We demonstrate that training data are demonstrably more reconstructible than non-members, enabling significantly improved detection accuracy. Could this active approach unlock more robust defenses against data extraction and better safeguard the privacy of training datasets?
The Memorization Risk: Unveiling Model Vulnerabilities
Despite their remarkable capabilities, modern language models exhibit a concerning vulnerability to membership inference attacks. These attacks exploit the model’s tendency to “memorize” specific details from its training data, allowing an adversary to determine whether a particular data point was used during the learning process. This isn’t about extracting the data itself, but rather confirming membership – establishing that a record contributed to the model’s creation. The implications are substantial; even if the model doesn’t directly output sensitive information, revealing whether a patient’s medical record, a user’s financial data, or a private communication was part of the training set represents a significant breach of privacy. The success of these attacks underscores a fundamental trade-off between model performance – often enhanced by memorization – and the safeguarding of confidential training data, prompting a critical need for robust privacy-preserving techniques.
Current strategies for mitigating membership inference attacks frequently center on obscuring the training data through techniques like differential privacy or employing model regularization to limit overfitting. However, research demonstrates these defenses often provide a false sense of security. Adaptive adversaries, capable of analyzing the model’s behavior and tailoring their attacks accordingly, can frequently circumvent these protections. Specifically, adversaries can exploit subtle patterns in the model’s outputs – even after obfuscation or regularization – to accurately determine if a particular data point was used during training. This highlights a critical limitation: defenses designed against non-adaptive attacks are often ineffective against more sophisticated adversaries, necessitating the development of robust, adaptive defense mechanisms that account for evolving attack strategies.
The potential for membership inference attacks introduces substantial privacy concerns, particularly within applications handling sensitive data like healthcare records, financial details, or personal communications. A successful attack doesn’t reveal the model’s learned knowledge, but rather confirms whether a specific data point was used during its training. This distinction is critical; even if a model accurately predicts outcomes without memorizing data, it can still inadvertently disclose private information through the inference attack. Consequently, individuals could be identified or re-identified from seemingly anonymized datasets, potentially leading to discrimination, reputational damage, or other harms. The risk is amplified in federated learning scenarios, where models are trained on decentralized data sources, and the privacy of each contributing dataset becomes paramount. Therefore, robust defenses against membership inference are not merely a technical challenge, but an ethical imperative for responsible AI development and deployment.
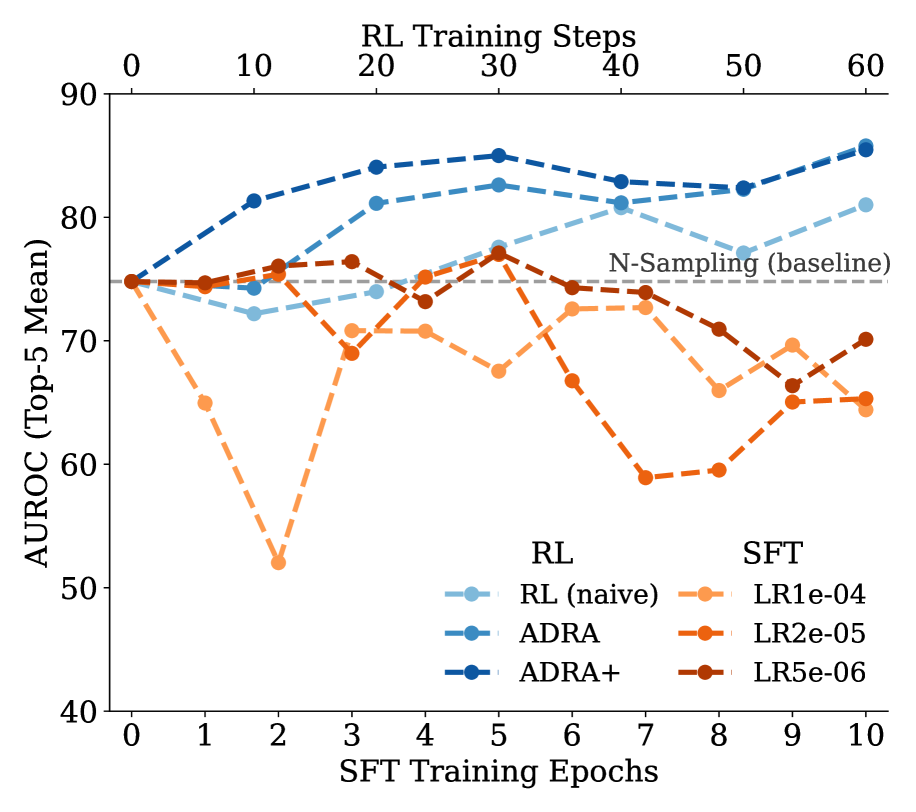
Beyond Passive Observation: The Rise of Active Reconstruction
Active Data Reconstruction Attacks (ADRA) redefine membership inference by formulating it as a reinforcement learning (RL) problem. Instead of passively querying a model, ADRA employs an agent that learns a policy for generating data instances. This agent iteratively constructs data, receiving rewards based on the similarity of the generated data to the original training set. The objective is to maximize the reconstruction accuracy of training data, effectively using the model itself as a component of the reconstruction process. Through this active probing, ADRA aims to identify data points used during model training, thereby inferring membership without direct access to the training data or model parameters.
Active Data Reconstruction Attacks (ADRA) leverage a reinforcement learning policy to generate synthetic data instances and assess their similarity to the target model’s training data. The policy is trained to maximize a reward function based on the generated data’s ability to elicit responses consistent with those observed during training. By comparing the model’s output on generated data to its behavior on known training examples, ADRA effectively differentiates between data points that were and were not used during model training. A higher degree of similarity between generated and training data suggests membership, while substantial divergence indicates a non-member example. This process allows for a quantifiable assessment of membership, enabling the attacker to infer whether a specific data record contributed to the model’s training process.
Traditional membership inference attacks are typically passive, relying on observation of a model’s outputs given specific inputs to determine if those inputs were part of the training dataset. Active Data Reconstruction Attacks (ADRA) deviate from this by actively probing the model; the attacker utilizes a reinforcement learning policy to generate inputs and observes the resulting outputs. This active probing allows the attacker to strategically explore the model’s decision boundary and identify vulnerabilities related to memorization of training data. By optimizing the generation policy to produce outputs similar to those observed during training, ADRA effectively increases the signal indicating membership, improving the accuracy of membership inference beyond what is achievable through passive observation alone.
Decoding the Signal: Refinement of Reconstruction Metrics
ADRA employs a ‘Reconstruction Reward’ to evaluate the fidelity of generated data by measuring its similarity to the training dataset. This reward is calculated using several distinct metrics: Token Set Similarity, which assesses overlap in unique tokens; Longest Common Subsequence, quantifying the length of the longest sequence of tokens shared between generated and training data; and N-gram Set Coverage, which measures the proportion of N-grams present in the training data that are also found in the generated output. These metrics provide a quantitative assessment of reconstruction quality, allowing the reinforcement learning agent to refine its policy based on the degree to which generated data replicates characteristics of the original training examples.
The Reconstruction Reward in ADRA utilizes similarity metrics – including Token Set Similarity, Longest Common Subsequence, and N-gram Set Coverage – to assess the overlap between generated samples and the original training data distribution. These metrics provide a granular signal to the reinforcement learning agent beyond simple binary acceptance or rejection; for example, Token Set Similarity calculates the Jaccard index between the tokens present in the generated and training examples. Longest Common Subsequence identifies the length of the longest sequence of tokens shared between the two, while N-gram Set Coverage measures the proportion of N-grams in the generated data also found within the training set. By quantifying this alignment, the reward function guides the agent towards generating data that maintains the characteristics of the training distribution, improving sample quality and reducing the risk of mode collapse or divergence.
ADRA+ enhances reward signaling through the implementation of a ‘Contrastive Reward’ component. This reward functions by explicitly evaluating the dissimilarity between generated samples and non-member examples – data deliberately excluded from the training set. By assigning higher rewards for generated data that demonstrably differs from non-member examples, the policy is encouraged to learn more robust and discriminating features. This contrastive element supplements the Reconstruction Reward, guiding the reinforcement learning agent to not only replicate the training data distribution but also to actively avoid generating samples resembling out-of-distribution data, thereby improving generalization and robustness.
Empirical Validation: Models and Datasets Under Scrutiny
Adversarial Data Reconstruction Attacks (ADRA) and its variants have undergone empirical validation using several prominent large language models (LLMs). Specifically, ADRA’s performance was assessed on Llama2-7B, Qwen2-7B, Olmo3, and Gemini-2.0-Flash. This testing demonstrates the attack’s applicability across diverse model architectures and sizes, indicating its potential as a generalized threat to LLM privacy. The evaluation framework utilized these models to determine the effectiveness of ADRA in inferring membership of training data, providing a basis for comparison with other existing attacks.
Evaluation of the ADRA attack across multiple datasets – WikiMIA2024-Hard, BookMIA, AIME, and Olympia Math – demonstrates its robustness to variations in data distribution and model architecture. Performance on these diverse datasets indicates ADRA’s ability to successfully infer membership across different task types, ranging from general knowledge and book content to mathematical reasoning. This cross-dataset efficacy highlights the transferability of the attack, suggesting its applicability beyond the specific training conditions of any single model or dataset. The consistent performance across these benchmarks supports the conclusion that ADRA is not reliant on dataset-specific artifacts and represents a broadly effective membership inference technique.
Performance evaluations demonstrate the efficacy of the ADRA attack across multiple datasets. Specifically, on the WikiMIA2024-Hard dataset, ADRA achieved an Area Under the Receiver Operating Characteristic curve (AUROC) of 60.6%, representing a 10% performance increase compared to the Min-K%++ attack. Further testing on the AIME (post-training) dataset resulted in an AUROC of 85.9% for ADRA, which is a 13.2% improvement over the N-Sampling attack and a 7.6% improvement over Min-K%++. These results indicate ADRA’s superior ability to accurately infer membership in these datasets compared to the baseline attacks.
ADRA demonstrates high efficacy in membership inference attacks when applied to models distilled from Deepseek-R1. Evaluation results indicate an Area Under the Receiver Operating Characteristic curve (AUROC) of 98.4%, signifying near-perfect accuracy in determining whether a given data point was used during the training of the distilled model. Furthermore, ADRA consistently outperforms existing methods; across all tested configurations, it achieves an average improvement of 10.7% in AUROC compared to the previously best-performing technique.
Toward Robust Privacy: Charting Future Directions
The success of the Adversarial Data Reconstruction Attack (ADRA) in reliably identifying data used to train language models underscores a critical need for advanced privacy defenses. This demonstrated vulnerability reveals that simply removing direct identifiers from training data is insufficient to prevent membership inference – the ability to determine if a specific data point contributed to a model’s learning process. Consequently, researchers are compelled to develop novel techniques that go beyond data sanitization, focusing instead on actively obscuring the model’s sensitivity to individual training examples. Effective defenses will likely involve strategies that inject controlled noise into the learning process, limit the model’s memorization capacity, or fundamentally alter the model’s architecture to reduce its reliance on specific data points – ultimately safeguarding sensitive information while preserving model utility.
Addressing the growing need for robust model privacy, future investigations are poised to integrate techniques such as differential privacy, federated learning, and adversarial training. Differential privacy introduces carefully calibrated noise to model outputs, obscuring individual contributions to the training data. Federated learning enables model training across decentralized datasets – like those held on individual devices – without directly exchanging the data itself. Complementing these, adversarial training fortifies models against malicious inputs designed to reveal sensitive information. By synergistically combining these approaches, researchers aim to create language models that not only perform with high accuracy but also demonstrably protect the privacy of the data used to build them, paving the way for responsible innovation in artificial intelligence.
The increasing integration of large language models into sensitive domains – healthcare, finance, and legal services, for example – demands a shift toward prioritizing privacy by design. Simply reacting to vulnerabilities after deployment is insufficient; a proactive stance necessitates anticipating potential privacy breaches and embedding preventative measures directly into model development and training pipelines. This includes robust data anonymization techniques, rigorous testing for membership inference attacks, and the exploration of privacy-enhancing technologies like differential privacy and federated learning. Responsible deployment isn’t merely about algorithmic accuracy; it’s fundamentally about building and maintaining public trust by demonstrably safeguarding sensitive user data and ensuring equitable access to these powerful technologies without compromising individual privacy rights.
The pursuit of identifying training data within language models, as demonstrated by the Active Data Reconstruction Attack (ADRA), echoes a fundamental tenet of elegant design. This work isn’t about adding layers of complexity to detect membership; rather, it’s about discerning the signals already present within the model’s weights. As Brian Kernighan aptly stated, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” Similarly, ADRA doesn’t rely on intricate methods but extracts latent information through reinforcement learning, revealing membership with consistent efficacy. The essence lies in what remains – a clear signal amidst the complexity, achieved through focused extraction rather than convoluted addition.
Where to Next?
The presented work demonstrates a predictable, yet necessary, escalation. Membership inference, once a theoretical concern, solidifies as a practical threat, and this approach – actively probing model weights – offers a sharper instrument than passive observation. The consistent outperformance is not surprising; signal exists, and directed elicitation invariably outperforms hoping for its spontaneous revelation. The question, then, shifts from ‘can membership be inferred?’ to ‘how much of the training data can be reconstructed, and with what fidelity?’
Future efforts must address this reconstruction fidelity. The current paradigm, focused on identifying that a sample was present, feels… incomplete. A more precise attack – one reconstructing significant portions of the original data – presents a far more substantial risk. Mitigation strategies, beyond differential privacy or federated learning, will necessitate a deeper understanding of information encoding within model parameters – a cartography of knowledge, if one will.
Ultimately, the field circles a fundamental truth: models do not forget; they distill. The challenge isn’t to prevent learning, but to manage the residue. Simplicity, in model design and training protocols, remains the most potent defense. Complicated architectures and elaborate training regimes offer more surface area for these attacks to exploit, a lesson often overlooked in the pursuit of incremental gains.
Original article: https://arxiv.org/pdf/2602.19020.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Gold Rate Forecast
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- HSR 3.7 story ending explained: What happened to the Chrysos Heirs?
- Games That Faced Bans in Countries Over Political Themes
- ETH PREDICTION. ETH cryptocurrency
- Gay Actors Who Are Notoriously Private About Their Lives
- Banks & Shadows: A 2026 Outlook
- The 10 Most Beautiful Women in the World for 2026, According to the Golden Ratio
- The Best Actors Who Have Played Hamlet, Ranked
2026-02-25 23:08