Author: Denis Avetisyan
Researchers have developed a novel framework that uses artificial intelligence to realistically generate urban mobility patterns, offering potential benefits for traffic simulation and autonomous driving.
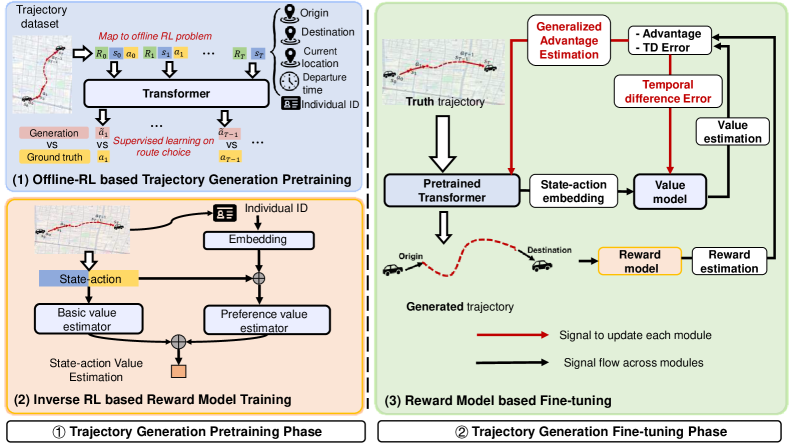
TrajGPT-R leverages transformer architectures and reinforcement learning to produce diverse and reliable urban mobility trajectories.
Access to detailed urban mobility data is often restricted due to privacy concerns, hindering comprehensive analysis and effective urban planning. This paper introduces TrajGPT-R: Generating Urban Mobility Trajectory with Reinforcement Learning-Enhanced Generative Pre-trained Transformer, a novel framework leveraging transformer architectures and inverse reinforcement learning to synthesize realistic and diverse mobility trajectories. By conceptualizing trajectory generation as a reinforcement learning problem and utilizing a learned reward model, TrajGPT-R demonstrably surpasses existing methods in both reliability and diversity of generated data. Could this approach unlock new possibilities for simulating urban dynamics and informing data-driven urban development strategies?
The Imperative of Realistic Urban Flow Modeling
The burgeoning field of smart city development increasingly relies on comprehensive understanding of urban mobility, achieved through analysis of `Urban Mobility Trajectory` data – detailed records of how people and vehicles move through cityscapes. However, translating this data into genuinely realistic movement simulations presents a formidable challenge. Simply replicating observed paths isn’t enough; accurate modeling demands capturing the nuanced decision-making processes behind each trajectory, including responses to congestion, adherence to traffic laws, and even seemingly random deviations. Current methodologies often fall short in replicating this complexity, resulting in simulations that, while computationally efficient, lack the fidelity needed for reliable predictions regarding traffic flow, infrastructure planning, and emergency response strategies. Bridging this gap between data collection and realistic representation remains a critical hurdle in realizing the full potential of data-driven urban planning.
Conventional approaches to modeling urban movement frequently fall short when replicating the nuanced behaviors observed in real-world scenarios. These methods often rely on simplified assumptions about travel choices and route selection, failing to account for the heterogeneity of individual preferences, unpredictable events like traffic congestion, or the influence of social networks. Consequently, simulations built upon these foundations can produce trajectories that lack the fidelity needed for accurate predictions, potentially misrepresenting peak hour flows, emergency evacuation routes, or the impact of new infrastructure. The resulting inaccuracies limit the effectiveness of urban planning tools and hinder the development of truly responsive and intelligent city systems, as models struggle to reflect the dynamic and often chaotic nature of human mobility.

The Transformer Architecture: A Mathematically Sound Solution
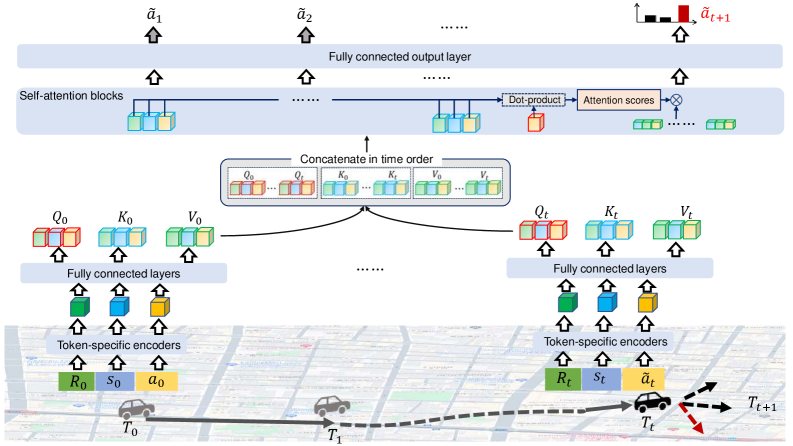
The Transformer architecture addresses sequential data modeling through self-attention mechanisms, which allow the model to weigh the importance of different parts of the input sequence when predicting the next element. Unlike recurrent neural networks (RNNs) that process data sequentially, Transformers process the entire input sequence in parallel, enabling significant computational speedups. Self-attention calculates a weighted sum of the input sequence, where the weights are determined by the relationships between elements within the sequence. This allows the model to capture long-range dependencies without the vanishing gradient problems often encountered in RNNs. Specifically, for movement patterns, this means the model can consider past positions and actions to more accurately predict future states, regardless of the time elapsed between them. The core of the mechanism involves three learned weight matrices – Query, Key, and Value – used to compute attention scores and generate context vectors representing the relevant information from the input sequence.
Trajectory generation, when implemented with models such as BERT and Decision Transformer, leverages the Transformer architecture by recasting the problem as a sequence modeling task. These models treat observed and predicted states as elements within a sequence, allowing them to learn dependencies between past and future movements. Specifically, the model is trained to predict future locations – or states – given a history of past states and actions. This approach differs from traditional methods by directly modeling the probability distribution over trajectories, enabling the generation of diverse and contextually relevant paths based on learned patterns from training data. The efficacy of this method relies on the model’s ability to capture long-range dependencies within the sequential data and extrapolate plausible future states based on preceding observations.
Trajectory generation using Transformer models necessitates the conversion of continuous state and action spaces into discrete tokens for processing. This is achieved through a specific tokenization scheme involving three primary token types: State Tokens, which represent the observed environment state at a given timestep; Action Tokens, denoting the control signal or action taken by the agent; and Return-to-Go Tokens, which indicate the remaining cumulative reward to achieve, providing the model with a sense of progress towards a goal. Effective tokenization is critical, as the Transformer architecture operates on discrete sequences; the quality of these tokens directly impacts the model’s ability to learn and predict future trajectories based on past experience. The discretization process involves mapping continuous values into a finite vocabulary of tokens, often utilizing techniques like uniform or learned codebooks.
Rigorous Validation: Quantifying Realism and Diversity
Evaluating the quality of generated trajectories requires metrics that assess both diversity and realism, moving beyond simple endpoint error calculations. The BLEU score measures n-gram overlap with reference trajectories, indicating similarity in sequential patterns. Jaccard Similarity quantifies the overlap of unique trajectory segments between generated and real-world data. Cosine Similarity evaluates the angular difference between trajectory vectors, providing a measure of directional agreement. To capture the complexity of trajectory patterns, Unigram Entropy and Bigram Entropy are employed; these metrics quantify the unpredictability of sequential elements, with higher values indicating greater diversity and more realistic movement patterns. These metrics, used in combination, provide a comprehensive assessment of generated trajectory quality beyond basic positional accuracy.
Trajectory generation models are evaluated using publicly available datasets representing real-world movement patterns. The Toyota Dataset, comprised of vehicle trajectories, provides a large-scale evaluation resource. Complementing this, the T-Drive Dataset focuses on taxi trajectories in Tokyo, offering a different urban environment. Finally, the Porto Taxi Dataset, sourced from Porto, Portugal, adds further geographical diversity and scale. Utilizing these datasets in conjunction with metrics like BLEU score and Jaccard similarity allows for a comprehensive assessment of generated trajectories, ensuring they reflect realistic and diverse movement behaviors observed in real-world transportation systems.
The TrajGPT-R model has been evaluated on the Toyota Dataset, yielding specific performance metrics related to trajectory generation. Quantitative results indicate a Jaccard Similarity of 0.524, a Cosine Similarity of 0.575, and a BLEU score of 0.383. Beyond these similarity measures, the model achieves a Unigram Entropy of 14.85 and a Bigram Entropy of 14.82 when assessed using the same dataset, demonstrating its capacity to generate diverse and realistic trajectories as measured by these entropy-based metrics.
Reward Modeling enhances trajectory generation by providing a feedback mechanism that aligns generated paths with desired characteristics. This process involves training a reward model to predict a scalar reward value representing the quality of a given trajectory, based on factors like smoothness, goal completion, and adherence to traffic rules. The resulting reward signal, applied on a trajectory-wise basis – meaning the entire path receives a single reward – is then used during training to optimize the generative model, effectively reinforcing the creation of higher-quality and more realistic trajectories. This approach allows for the incorporation of complex, non-differentiable criteria into the training process, improving performance beyond metrics based solely on positional accuracy.
Towards Efficient Simulation: Beyond the Limitations of Diffusion
Diffusion models have emerged as a potent technique for generating plausible and diverse trajectories, particularly in complex systems where predicting future movement is crucial. However, this power comes at a significant computational cost; the iterative refinement process inherent to diffusion requires numerous forward passes through the model, making real-time or large-scale applications challenging. Each step in the diffusion process demands substantial processing power, hindering their deployment in scenarios requiring rapid simulations – such as city-wide traffic modeling or coordinating fleets of autonomous vehicles. Consequently, researchers are actively exploring methods to enhance the efficiency of these models, seeking to reduce computational demands without sacrificing the quality and realism of the generated trajectories.
Recent advancements in trajectory generation are increasingly focused on transformer-based models as a computationally efficient alternative to diffusion methods. These models excel at capturing the complex dependencies inherent in movement patterns, allowing for the creation of realistic simulations with significantly reduced processing demands. However, realizing the full potential of these models requires rigorous evaluation beyond simple visual inspection. Researchers are now employing diverse metrics – encompassing kinematic properties, social interactions, and predictive accuracy – alongside comprehensive datasets representing varied scenarios. This careful validation process not only ensures the fidelity of the generated trajectories but also identifies areas for model refinement, paving the way for practical applications in fields such as autonomous navigation and large-scale urban planning.
The advancements in trajectory generation modeling extend far beyond theoretical improvements, offering tangible benefits to several critical sectors. In traffic management, these models can simulate vehicle flows with unprecedented accuracy, enabling proactive adjustments to signal timings and lane configurations to mitigate congestion and enhance overall efficiency. Urban planners can utilize these simulations to assess the impact of new infrastructure projects – such as roads, pedestrian zones, or public transportation routes – before implementation, optimizing designs for minimal disruption and maximum benefit. Perhaps most significantly, the development of realistic and efficient trajectory models is crucial for the progress of autonomous vehicle technology; enabling these vehicles to accurately predict the movement of other agents – pedestrians, cyclists, and other cars – is fundamental to ensuring safe and reliable navigation in complex, real-world environments.
The pursuit of realistic trajectory generation, as exemplified by TrajGPT-R, demands a rigorous adherence to logical completeness. The framework’s integration of inverse reinforcement learning to model rewards echoes a mathematical purity, striving not merely for functional output but for a provable representation of urban mobility. This is aligned with the sentiment expressed by Alan Turing: “Sometimes people who are not very good at games, or at anything much, can change their luck by a different approach.” TrajGPT-R represents such a change – a different approach to generating diverse and reliable trajectories, moving beyond simple imitation towards a system grounded in reward maximization and logical consistency.
Future Directions
The presented TrajGPT-R framework, while demonstrating a capacity for trajectory generation, ultimately highlights the enduring chasm between statistical mimicry and genuine understanding of urban mobility. The reliance on inverse reinforcement learning, however sophisticated, merely infers a reward function – a shadow of the true, multifaceted incentives governing agent behavior. Future work must confront the limitations of this inductive bias; a perfectly inferred reward is still only an approximation, and thus, generated trajectories, however plausible, remain fundamentally constrained by the model’s imperfect perception of the environment.
The true challenge lies not in generating more trajectories, but in generating those possessing provable characteristics. The current evaluation metrics, largely focused on empirical observation, fail to address the question of algorithmic robustness. Scalability is not simply a matter of computational efficiency, but of ensuring that generated trajectories remain valid-free from logical inconsistencies or physically impossible maneuvers-as the complexity of the urban environment increases. A formal verification of these trajectories, perhaps leveraging techniques from formal methods or control theory, remains a crucial, largely unexplored avenue.
Ultimately, the field requires a shift in focus. The pursuit of increasingly elaborate generative models must be tempered by a commitment to mathematical rigor. Until algorithms can not only produce trajectories but also guarantee their correctness, the promise of truly intelligent urban mobility systems will remain elusive. The elegance of a solution is not measured by its fidelity to observed data, but by the purity of its underlying logic.
Original article: https://arxiv.org/pdf/2602.20643.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Gold Rate Forecast
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- HSR 3.7 story ending explained: What happened to the Chrysos Heirs?
- Gay Actors Who Are Notoriously Private About Their Lives
- ETH PREDICTION. ETH cryptocurrency
- Games That Faced Bans in Countries Over Political Themes
- Uncovering Hidden Groups: A New Approach to Social Network Analysis
- The Best Actors Who Have Played Hamlet, Ranked
- The 10 Most Beautiful Women in the World for 2026, According to the Golden Ratio
2026-02-25 19:51