Author: Denis Avetisyan
A new approach balances exploration and exploitation in generative flow networks, enabling more efficient learning and improved sample quality.

Adaptive Complementary Exploration balances trajectory divergence in Generative Flow Networks via a novel loss function.
Efficient exploration remains a key challenge in reinforcement learning, particularly when learning complex generative models. This is addressed in ‘Avoid What You Know: Divergent Trajectory Balance for GFlowNets’, which introduces Adaptive Complementary Exploration (ACE) to improve sample efficiency in Generative Flow Networks (GFlowNets) by explicitly incentivizing the discovery of underexplored, high-reward states. ACE achieves this through a novel ‘divergent trajectory balance’ loss, effectively coordinating exploration and exploitation via complementary GFlowNets. Could this principled approach to balancing exploration and exploitation unlock more robust and scalable generative models for diverse applications?
The Elegance of Compositional Systems
A vast array of natural and artificial systems are best understood not by their individual parts, but by the relationships between those parts. This compositional structure is prevalent in fields ranging from genomics – where gene expression levels collectively determine cellular behavior – to materials science, where the proportions of different elements dictate a material’s properties. Consider the simple example of a recipe; the individual ingredients are meaningless without their precise ratios and interactions during the cooking process. Similarly, in finance, a portfolio’s performance isn’t determined by the value of each stock in isolation, but by how those assets combine and respond to market forces. These datasets, where the meaning arises from the interplay of components that inherently sum to a constant – like percentages or probabilities – pose a significant challenge for conventional modeling techniques that treat each element as independent.
Conventional generative models often falter when tasked with replicating datasets defined by compositional relationships – those where the meaning arises not from individual components, but from their interactions. This difficulty stems from the models’ inherent limitations in representing dependencies and constraints between variables; as a result, sampling from these models yields outputs that lack realism or coherence. Attempts to force these models to learn such complex relationships typically require exponentially more data and computational resources, hindering their scalability and practical application. The limited expressiveness manifests as a failure to capture the full range of variation present in the data, leading to generated samples that are either overly simplistic or demonstrably unrealistic, particularly when extrapolating beyond the training distribution.
To accurately represent and generate compositional data, modeling frameworks must move beyond treating components in isolation and instead prioritize the relationships between them. Simply learning the distribution of each component independently ignores the inherent constraints – such as fixed sums or proportional relationships – that define the system. Approaches that explicitly incorporate these structural dependencies, through techniques like specialized transformations or constrained generative processes, demonstrate significantly improved performance. These methods allow models to capture the intricate interplay between parts, leading to more realistic samples and a greater ability to generalize to unseen data, ultimately unlocking insights hidden within complex compositional structures.
Deconstructing Complexity: The GFlowNet Framework
GFlowNets represent compositional data using a directed acyclic graph where nodes define distinct states and edges represent transitions between them. This graph-based structure enables the modeling of complex systems by decomposing them into manageable, interconnected components. The use of a graph allows for flexible representation of data with varying lengths and structures, overcoming limitations of fixed-dimensional representations. Scalability is achieved through the modularity of the graph; new states and transitions can be added without requiring retraining of the entire model. The state graph facilitates efficient computation of probabilities and gradients during training and sampling, enabling GFlowNets to handle high-dimensional and complex datasets effectively.
GFlowNets employ distinct forward and backward policies to traverse the state graph during both sample generation and probability estimation. The forward policy defines the probability distribution for transitioning from one state to another, effectively constructing a sample by sequentially selecting states. Conversely, the backward policy estimates the probability of reaching a particular state given a terminal state, facilitating efficient computation of likelihoods and enabling gradient-based learning. These policies are parameterized and learned during training, allowing the model to adapt its traversal strategy based on the underlying data distribution and optimize for both sample quality and accurate probability estimation. P(s_{t+1}|s_t) represents the forward policy and P(s_t|s_T) the backward policy, where s_t denotes a state at time step t and s_T represents a terminal state.
GFlowNets differentiate from conventional generative models, such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs), by explicitly representing the data’s underlying compositional structure as a state graph rather than learning a latent space representation. Traditional methods often struggle with complex, hierarchical data due to the difficulty of accurately capturing dependencies within a lower-dimensional latent space. By directly modeling these relationships within the graph structure, GFlowNets achieve improved performance in areas such as molecule generation and image synthesis, particularly when dealing with data exhibiting long-range dependencies or intricate compositional rules. This direct modeling approach facilitates more accurate probability estimation and sample generation, circumventing the limitations inherent in indirect, latent variable-based methods.

Navigating the State Space: Adaptive Complementary Exploration
GFlowNets rely on effective state space exploration to produce diverse and high-quality samples; inadequate exploration leads to mode collapse and suboptimal performance. The state graph, representing the possible states within a given problem, requires broad coverage to identify and sample from all relevant modes of the target distribution. Insufficient exploration results in the network focusing on a limited subset of states, failing to capture the full complexity of the data. Conversely, efficient exploration techniques ensure that the sampling process reaches under-represented regions of the state space, promoting the generation of more varied and representative samples and ultimately improving the quality and reliability of the generated data.
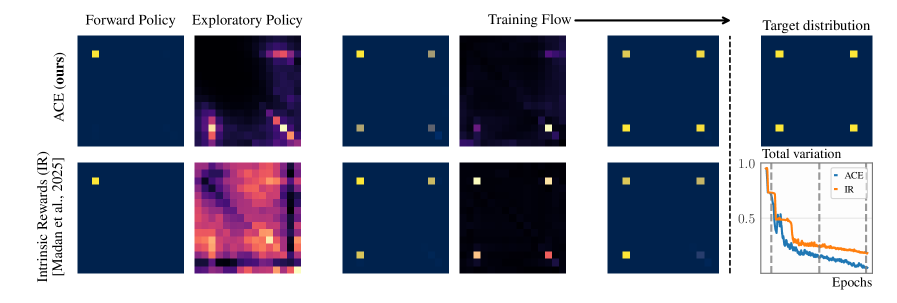
Adaptive Complementary Exploration integrates GFlowNets with trajectory-based sampling methods, specifically Divergent Trajectory Balance (DTB), to address deficiencies in conventional exploration strategies. Standard exploration policies often struggle with inefficient sampling and can become trapped in limited regions of the state space. DTB extends the principles of Trajectory Balance by actively penalizing trajectories leading to frequently sampled states. This penalty encourages the model to prioritize exploration of under-represented areas, effectively diversifying the generated samples and improving the overall sampling process. The combination of GFlowNets’ generative capabilities with DTB’s targeted exploration yields a more robust and efficient sampling methodology.
Divergent Trajectory Balance (DTB) builds upon the Trajectory Balance method to maintain sampling correctness during the generation process. DTB actively discourages sampling from regions of the state space that have already been frequently visited by introducing a penalty proportional to the sampling density. This penalty dynamically redirects exploration towards under-represented areas, effectively improving the efficiency of state space coverage. Experimental results demonstrate accelerated convergence using DTB across a diverse set of environments, including sequence design, bit sequences, the knapsack problem, grid worlds, bags, lazy random walks, and the AMPs (Asymmetric Markov Processes) benchmark.
Evaluations of the Adaptive Complementary Exploration method demonstrate quantifiable performance gains. Specifically, a significant reduction in Total Variation (TV) Distance was observed in the Rings environment, indicating improved sample quality and coverage. Furthermore, the method exhibits robust performance characteristics, maintaining stability and effectiveness across a wide range of hyperparameter settings for both α and β. This hyperparameter insensitivity suggests a lessened need for extensive tuning and increased reliability in diverse application contexts.
Intrinsic Motivation: Fueling Discovery in Complex Systems
The pursuit of effective exploration in complex environments benefits significantly from policies driven by intrinsic motivation. Rather than relying solely on external rewards, these policies incentivize the agent to seek out novel states, effectively encouraging it to venture beyond familiar territory. This approach fosters a more comprehensive understanding of the environment, as the agent is rewarded simply for discovering the unfamiliar. By quantifying novelty and translating it into an intrinsic reward signal, the exploratory process becomes self-directed, allowing the agent to proactively seek out information and improve its overall performance without needing constant external guidance. This ultimately leads to more robust and efficient learning, particularly in scenarios where external rewards are sparse or delayed.
The system leverages Random Network Distillation (RND) to establish an intrinsic reward signal, effectively gauging the novelty of each encountered state during exploration. RND operates by training a random neural network to predict the output of another network exposed to the environment; discrepancies between these outputs quantify how ‘surprising’ a given state is. A larger difference indicates a state the system hasn’t frequently seen, thus generating a higher reward. This allows the agent to actively seek out and investigate unfamiliar areas of the data space, driving exploration beyond what would be possible with purely extrinsic rewards and enabling the discovery of genuinely new and potentially valuable compositional patterns.
A novel framework combining GFlowNets, a differentiable tree builder, and exploration driven by intrinsic rewards has demonstrated exceptional performance in generative modeling of compositional data, specifically in the challenging domain of antimicrobial activity prediction. This integrated approach not only generates plausible molecular structures but also accurately forecasts their efficacy against a diverse range of bacterial and fungal pathogens. Rigorous evaluation reveals area under the receiver operating characteristic curve (AUC) scores of 0.944 for E. coli, 0.942 for S. aureus, 0.913 for P. aeruginosa, 0.905 for B. subtilis, and 0.930 for C. albicans, indicating a robust and highly predictive model capable of accelerating the discovery of new antimicrobial compounds.

The pursuit of efficient exploration, as detailed in this work concerning Generative Flow Networks, inherently involves navigating a complex interplay between exploitation and discovery. This balancing act resonates with the sentiment expressed by Edsger W. Dijkstra: “It is not enough to have good intentions; one must also have good tools.” Adaptive Complementary Exploration (ACE) embodies this principle; it’s not simply about wanting to explore more effectively, but about designing a ‘divergent trajectory balance’ loss function – a precise tool – to actively manage the tension between exploiting known rewards and discovering novel possibilities. The architecture, in this instance, directly shapes the behavior of the network, demonstrating that a well-crafted system isn’t merely a theoretical construct but a pragmatic solution to a defined challenge.
Where Do We Go From Here?
The pursuit of efficient exploration in generative models invariably encounters the fundamental tension between venturing into the unknown and capitalizing on existing knowledge. This work, by focusing on trajectory balance, offers a refined mechanism for navigating this trade-off within the GFlowNet framework. However, the elegance of the solution does not erase the underlying complexity. The ‘divergent trajectory balance’ loss, while demonstrably effective, remains a heuristic. It implicitly assumes that a balanced divergence equates to optimal exploration – a proposition that, while plausible, lacks a broader theoretical justification. Future work must address whether this balance is merely a symptom of improved optimization, or a genuine advancement in the model’s ability to construct a meaningful representation of the environment.
A critical consideration lies in the scalability of this approach. The computational cost associated with maintaining and evaluating divergent trajectories may become prohibitive in high-dimensional or complex environments. The simplicity of the loss function is appealing, but any practical deployment will demand careful attention to these computational bottlenecks. Moreover, the reliance on reward shaping, even with adaptive techniques, introduces a degree of fragility. Dependencies on carefully engineered reward signals are the true cost of freedom, and a more robust solution would minimize this external dependency.
Ultimately, the field requires a shift in focus. Rather than chasing ever more sophisticated exploration strategies, the emphasis should be on architectures that inherently encourage discovery. Good architecture is invisible until it breaks; a truly robust generative model should learn effectively with minimal explicit guidance. The current work provides a valuable incremental improvement, but the ultimate goal remains a system that learns not just how to explore, but what is worth knowing.
Original article: https://arxiv.org/pdf/2602.17827.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Gold Rate Forecast
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- Banks & Shadows: A 2026 Outlook
- Gemini’s Execs Vanish Like Ghosts-Crypto’s Latest Drama!
- ETH PREDICTION. ETH cryptocurrency
- Uncovering Hidden Groups: A New Approach to Social Network Analysis
- Gay Actors Who Are Notoriously Private About Their Lives
- The 10 Most Beautiful Women in the World for 2026, According to the Golden Ratio
- The Weight of Choice: Chipotle and Dutch Bros
2026-02-23 18:52