Author: Denis Avetisyan
Accurate question answering over long financial reports hinges on effective information retrieval, but current systems often struggle to find the right data.
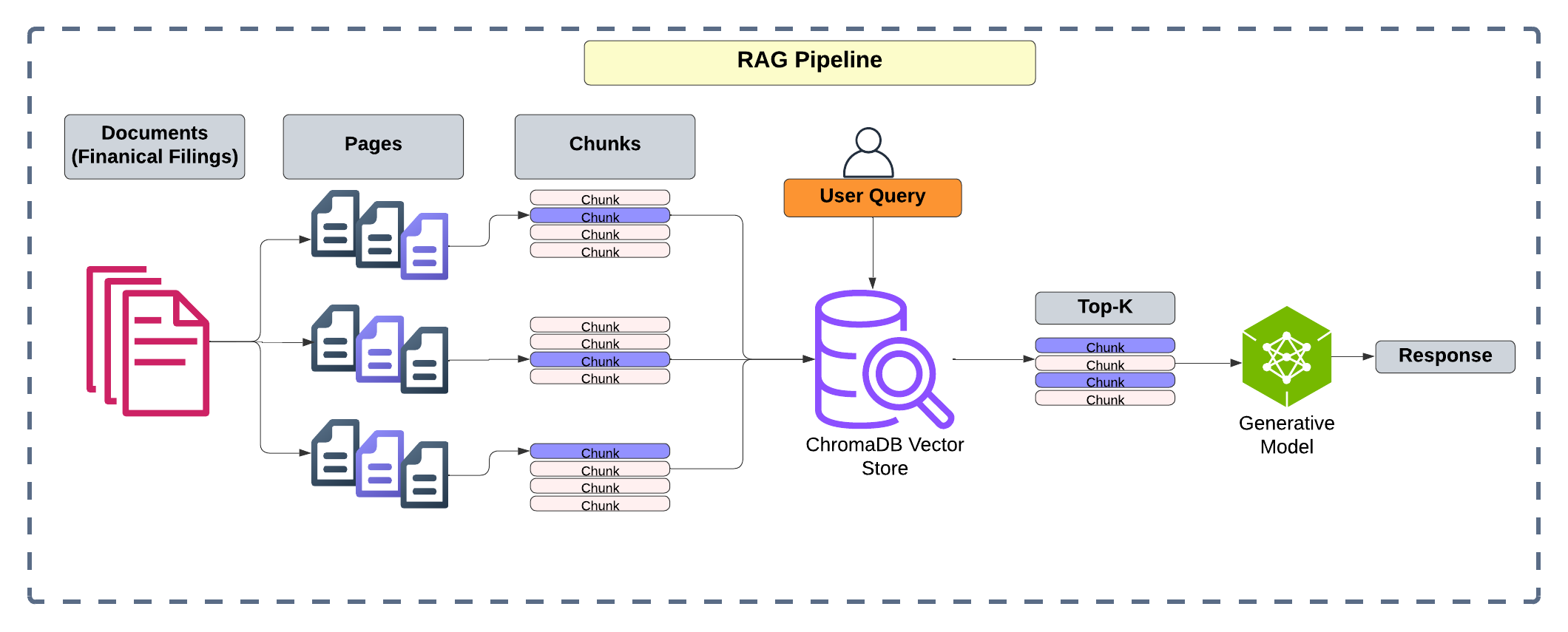
A new analysis decomposes retrieval failures in Retrieval-Augmented Generation for long-document financial question answering, identifying page-level retrieval as a key bottleneck and proposing a domain-tuned page scoring method to improve accuracy.
Despite advances in retrieval-augmented generation (RAG), reliably answering complex questions from lengthy financial documents remains challenging due to failures in pinpointing relevant contextual information. This paper, ‘Decomposing Retrieval Failures in RAG for Long-Document Financial Question Answering’, systematically investigates these failures, revealing that while document retrieval is often successful, performance significantly degrades at the page and chunk levels. Our analysis demonstrates that a domain-fine-tuned page scorer, treating pages as an intermediate retrieval unit, substantially improves both page recall and downstream chunk retrieval accuracy. Could this hierarchical approach unlock more robust and trustworthy financial question answering systems, particularly when dealing with the complexities of regulatory filings?
The Evolving Landscape of Financial Inquiry
The exponential growth of financial data presents a significant hurdle for conventional information retrieval systems. Historically, these systems relied on matching keywords between a query and document, a strategy proving increasingly inadequate when confronted with the sheer volume of reports, filings, and analyses generated daily. This challenge is particularly acute with lengthy documents such as 10-K filings – comprehensive annual reports that can exceed one hundred pages – where relevant information may be buried within dense prose and complex financial statements. Simple keyword searches often return a deluge of irrelevant results, or, crucially, fail to identify the precise passages containing the answer to a specific question, highlighting the limitations of traditional methods in navigating this complex information landscape.
Financial question answering systems face a significant hurdle when dealing with the sheer length of critical documents; traditional methods falter as they struggle to locate precise answers buried within extensive reports like 10-K filings. Simple keyword searches, while useful for initial filtering, often return a deluge of irrelevant passages or, crucially, miss the nuanced information required to address complex inquiries. The problem isn’t merely finding words that match the question, but discerning the meaning within lengthy and dense prose, requiring systems to understand context, relationships between data points, and the specific financial implications described. This demands a move beyond lexical matching toward semantic understanding, where the system can effectively pinpoint the relevant sentences or paragraphs – a task far exceeding the capabilities of basic information retrieval techniques.
Financial language presents unique challenges to question answering systems due to its specialized terminology, nuanced phrasing, and reliance on implicit contextual understanding. Unlike general language, financial texts frequently employ jargon, acronyms, and complex sentence structures that demand a deeper level of semantic analysis. Furthermore, answering questions often requires not merely locating information, but also performing reasoning – interpreting trends, assessing risk, and understanding the relationships between different financial metrics. Consequently, traditional information retrieval techniques, which primarily rely on keyword matching, prove inadequate. A truly effective system must incorporate advanced natural language processing techniques – including semantic parsing, knowledge graph integration, and reasoning capabilities – to decipher the meaning embedded within financial documents and provide accurate, insightful answers.
Retrieval-Augmented Generation: A Synthesis of Approaches
Retrieval-Augmented Generation (RAG) addresses the inherent limitations of both purely retrieval-based and generative models. Standalone retrieval systems, while capable of providing factual responses, are constrained by the information present in their indexed knowledge base and lack the ability to synthesize new insights. Conversely, standalone generative models, such as large language models, can produce fluent and creative text but are prone to inaccuracies due to their reliance on parametric knowledge and potential for hallucination. RAG mitigates these issues by first retrieving relevant documents from a knowledge source based on a user query, and then using these retrieved documents as context for a generative model to formulate a response. This combination allows the system to ground its responses in factual information while still benefiting from the generative model’s ability to produce coherent and nuanced text.
Dense retrieval in Retrieval-Augmented Generation (RAG) systems relies on transforming both search queries and documents into vector embeddings, also known as semantic representations. Models like BGE-M3 are utilized to generate these embeddings, capturing the semantic meaning of the text rather than relying on keyword matching. This allows the system to identify documents that are conceptually similar to the query, even if they don’t share the same keywords. The similarity between the query and document embeddings is then calculated – typically using cosine similarity – to rank documents based on their relevance. This approach significantly improves retrieval accuracy compared to traditional sparse retrieval methods, particularly for nuanced or complex queries where semantic understanding is crucial.
Hybrid retrieval strategies integrate the benefits of both sparse and dense retrieval methods to optimize information retrieval performance. Sparse retrieval, typically utilizing lexical matching with techniques like BM25, excels at precision by identifying exact keyword matches within documents. Conversely, dense retrieval, employing semantic embeddings and vector search, prioritizes recall by identifying documents conceptually similar to the query, even without direct keyword overlap. Combining these approaches allows a system to achieve a more balanced profile, capturing both the accuracy of sparse methods and the broader coverage of dense methods, resulting in improved overall effectiveness and a reduction in missed relevant documents.
Refining the Search: From Retrieval to Precision
Reranking techniques address the inherent limitations of initial retrieval stages by reordering results based on a more nuanced assessment of relevance. While initial retrieval methods, such as those employing keyword searches or Boolean logic, efficiently identify a broad set of potentially relevant documents, they often lack the capacity to precisely rank these results according to their actual relevance to the user’s query. Reranking models, frequently leveraging machine learning techniques, analyze the query and the retrieved documents to assign a relevance score, effectively reordering the initial result list to prioritize documents with higher scores. This process often incorporates features beyond simple keyword matching, including semantic similarity, contextual understanding, and query intent, leading to improved precision and a more satisfying user experience.
Hierarchical Retrieval addresses the scalability challenges of searching large document collections by decomposing the search process into multiple stages. Initially, the system identifies broad, coarse-grained sections – such as document categories or specific chapters – that are potentially relevant to the query. This first-pass filtering significantly reduces the number of documents requiring detailed analysis. Subsequently, a more precise search is conducted within these pre-selected sections, focusing on finer-grained elements like paragraphs or sentences. This two-stage approach minimizes computational cost by avoiding exhaustive searches across the entire corpus and concentrating resources on the most promising subsets of data, improving both retrieval speed and efficiency.
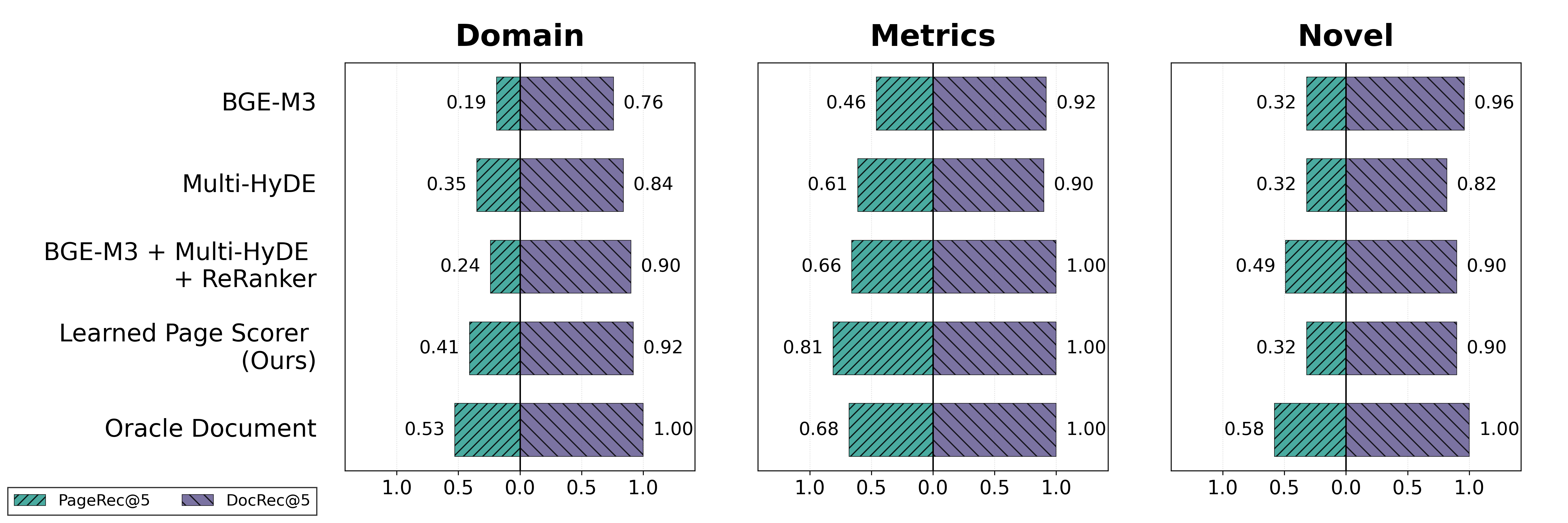
Page Scorer models function by evaluating the relevance of individual pages within a retrieved document to the user query, enabling a ranking of these pages independent of their position within the document. This intra-document ranking improves precision by prioritizing the most pertinent content. Performance evaluations utilizing the FinanceBench dataset demonstrate a Page Recall of 55%, indicating the model’s ability to identify and rank 55% of the relevant pages within a document collection. Further performance gains are achievable through domain-specific fine-tuning of these models, tailoring their relevance assessments to the nuances of particular subject areas.
Validating Performance: Benchmarks and the Measure of Understanding
The development of FinanceBench addresses a critical need for robust evaluation in financial question answering systems. This benchmark dataset isn’t merely a collection of questions; it’s meticulously constructed with accompanying ‘gold’ evidence – verified passages from source documents that definitively support the correct answers. This feature enables researchers to move beyond simple accuracy metrics and assess whether a system truly understands the reasoning behind its responses, rather than simply matching keywords. By providing these annotated sources, FinanceBench facilitates reliable and reproducible evaluations, allowing for meaningful comparisons between different approaches and accelerating progress in building trustworthy artificial intelligence for the complex domain of finance. The inclusion of this verified evidence also helps pinpoint areas where systems struggle, guiding future development and refinement.
Evaluating the effectiveness of information retrieval systems within complex financial datasets hinges on precisely measuring their ability to locate pertinent information. Document Recall and Page Recall serve as crucial metrics in this assessment; Document Recall quantifies the proportion of all relevant documents successfully retrieved, while Page Recall focuses on identifying the relevant pages within those documents. A high Page Recall indicates the system efficiently pinpoints the specific sections containing answers, avoiding the need to sift through irrelevant content. These metrics are particularly vital in finance, where accuracy and completeness are paramount, and the volume of data necessitates robust retrieval capabilities to deliver timely and reliable insights.
The evaluation on FinanceBench demonstrates a substantial advancement in pinpointing relevant information within financial documents. A learned page scorer achieved a Page Recall of 55%, indicating its ability to identify pertinent pages within the dataset. This performance nears the theoretical limit set by an ‘Oracle Document’ setting – a perfect retrieval system – which achieves 60%. Importantly, this result represents a considerable improvement over existing baseline methods, signifying a meaningful step towards more accurate and efficient financial question answering systems. The system’s capability to locate crucial pages with such precision suggests a robust approach to navigating the complexities of financial documentation and delivering reliable answers.
The system demonstrated a substantial improvement in identifying precise numerical answers within financial documents, achieving a Numeric Match Accuracy of 0.30. This represents a significant leap forward from the baseline performance of 0.12, indicating a heightened ability to correctly extract and match numerical data. While still slightly below the theoretical limit set by the Oracle Document setting of 0.26, the result suggests the approach is nearing optimal performance in this critical area of financial question answering, proving its capability to provide accurate and verifiable responses based on numerical evidence.
Evaluations on a substantial dataset of 10K filings reveal the approach’s strong performance, as evidenced by a leading ROUGE-L score of 0.46, indicating high-quality generated responses. Critically, the system achieves a Page Recall of 0.62 on these filings, surpassing the performance of an Oracle Document setting-a theoretical upper bound established by human experts-which attained a Page Recall of 0.56. This result suggests the model not only provides accurate answers but also effectively identifies the most relevant information within complex financial documents, demonstrating a significant advancement in automated financial analysis and knowledge retrieval.
The study of retrieval failures within Retrieval-Augmented Generation (RAG) systems, as detailed in the paper, highlights a critical truth about complex systems: their inherent fragility over time. Just as architecture without history is ephemeral, retrieval mechanisms reliant on static assumptions quickly degrade when confronted with the nuances of long financial documents. Grace Hopper observed, “It’s easier to ask forgiveness than it is to get permission.” This resonates with the need for adaptive, domain-tuned approaches – like the proposed page scorer – to circumvent rigid limitations and proactively address performance decay. The work acknowledges that even sophisticated systems require continuous refinement to remain robust, accepting that initial assumptions will inevitably require iterative correction and, occasionally, a willingness to deviate from established protocols to achieve accurate retrieval.
What Lies Ahead?
The decomposition of retrieval failures, as presented, offers a valuable, if sobering, assessment. Every commit is a record in the annals, and every version a chapter; this work clearly demarcates a problematic chapter in the deployment of Retrieval-Augmented Generation against complex, long-form financial data. The identification of page-level retrieval as a central bottleneck isn’t a surprise – systems invariably degrade most visibly at their interfaces. The proposed page scorer represents a pragmatic, domain-tuned intervention, but it’s a local fix for a systemic issue. The underlying tension remains: can semantic search, even when refined, truly grapple with the nuance and implicit knowledge embedded within lengthy financial reports?
Future work must address the temporal dimension of decay. Financial data isn’t static; regulations shift, markets evolve, and language itself mutates. A scorer effective today will inevitably require recalibration, and delaying fixes is a tax on ambition. More fundamentally, the field needs to move beyond simply improving retrieval accuracy and consider retrieval resilience – the ability to maintain performance despite data drift and evolving query intent.
The long arc bends toward increasing abstraction. Perhaps the true challenge isn’t retrieving the ‘right’ pages, but constructing a dynamic, knowledge graph capable of synthesizing answers from fragmented information. Such an approach acknowledges that perfect retrieval is an asymptotic ideal; graceful degradation, however, is a design goal worth pursuing.
Original article: https://arxiv.org/pdf/2602.17981.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Gold Rate Forecast
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- Banks & Shadows: A 2026 Outlook
- Gemini’s Execs Vanish Like Ghosts-Crypto’s Latest Drama!
- ETH PREDICTION. ETH cryptocurrency
- Uncovering Hidden Groups: A New Approach to Social Network Analysis
- Gay Actors Who Are Notoriously Private About Their Lives
- The 10 Most Beautiful Women in the World for 2026, According to the Golden Ratio
- The Weight of Choice: Chipotle and Dutch Bros
2026-02-23 17:34