Author: Denis Avetisyan
Researchers have developed a data augmentation framework that leverages round-trip prediction to significantly improve the performance of dense retrieval systems on challenging, long-tail question answering tasks.
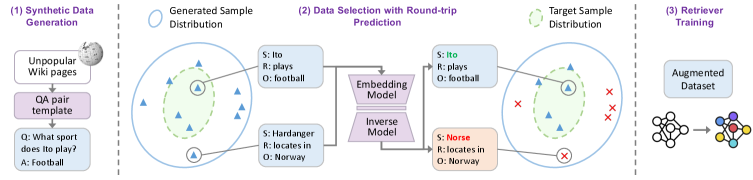
The RPDR framework utilizes round-trip prediction to enhance knowledge embeddings and improve retrieval accuracy for questions with limited training examples.
Large language models struggle to recall and apply less common knowledge, hindering performance on long-tail question answering tasks. To address this, we introduce ‘RPDR: A Round-trip Prediction-Based Data Augmentation Framework for Long-Tail Question Answering’, a novel approach that enhances dense retrieval by strategically augmenting training data with easy-to-learn instances identified via round-trip prediction. Our experiments on PopQA and EntityQuestion demonstrate that RPDR significantly improves retrieval accuracy, particularly for extremely rare categories, outperforming both BM25 and existing dense retrievers. Could dynamic routing to specialized retrieval modules further refine performance and unlock even greater gains in long-tail question answering systems?
Navigating the Long Tail: The Challenge of Sparse Knowledge
Question answering systems, while increasingly sophisticated, face a significant hurdle with what are known as “long-tail questions.” These aren’t queries about commonly known facts, but rather those concerning obscure entities, highly specific concepts, or niche areas of knowledge. The challenge arises because these systems are largely trained on prevalent data, creating a knowledge bias towards frequently discussed topics. As a result, when presented with a question referencing something outside of this common core – a rare disease, a little-known historical figure, or a specialized technical term, for example – the system’s ability to provide accurate and reliable answers diminishes considerably, highlighting a critical gap in comprehensive knowledge representation and retrieval.
Current question answering systems, powered by large language models, predominantly operate on parametric knowledge – information encoded within the model’s billions of weights during training. While remarkably effective for common queries, this approach faces inherent limitations when addressing the sheer breadth of real-world information. The vast majority of potential questions concern rare entities, niche concepts, or specific details not adequately represented in the training data. Consequently, the model’s internal knowledge base proves insufficient to cover the “long tail” of all possible inquiries – those beyond frequently encountered topics. This reliance on a fixed, finite knowledge store creates a fundamental bottleneck, as the model cannot reliably generalize to unseen or sparsely represented information, hindering its ability to accurately answer questions outside its core training distribution.
The tendency of question answering systems to generate factually incorrect responses, often termed “hallucination,” becomes particularly pronounced when addressing niche or uncommon queries. This isn’t simply a matter of lacking a direct answer; the model, trained on vast datasets but inevitably containing gaps in its knowledge, attempts to extrapolate or infer information, leading to plausible yet ultimately fabricated statements. This behavior erodes user confidence, as even a single instance of hallucination can cast doubt on the reliability of the entire system. The problem is amplified by the models’ inherent design – they prioritize generating an answer over admitting uncertainty, creating a convincing illusion of knowledge even when lacking genuine understanding. Consequently, mitigating hallucination is crucial not merely for improving accuracy, but for establishing trust and fostering the responsible deployment of these increasingly powerful technologies.
RPDR: A System for Data-Driven Knowledge Enhancement
Retrieval-Augmented Generation (RAG) systems demonstrate considerable potential for improving the performance of large language models by grounding responses in external knowledge sources. However, the efficacy of RAG is fundamentally limited by the quality of the retrieved documents; irrelevant or inaccurate information can negatively impact generated outputs. While increasing the size of the retrieval corpus is a common strategy, it does not inherently guarantee improved performance and can introduce noise. Therefore, focusing on retrieving highly relevant and informative documents is crucial for maximizing the benefits of RAG, necessitating techniques for both effective retrieval and quality control of the retrieved data.
The RPDR framework addresses limitations in retrieval-augmented generation (RAG) systems, specifically concerning performance on long-tail queries – those with limited training examples. It introduces a data augmentation technique designed to improve retrieval accuracy by strategically expanding the training dataset. Unlike random augmentation, RPDR focuses on identifying and adding data samples that the retrieval model can reliably learn, thereby increasing the relevance of retrieved information. This targeted augmentation aims to mitigate the negative impact of sparse data in long-tail scenarios, ultimately enhancing the overall effectiveness of the RAG pipeline.
Round-trip prediction, as implemented in RPDR, assesses data sample learnability by evaluating the consistency between an original input and its reconstruction after encoding and decoding via the retrieval model. Specifically, the input is first encoded into a vector representation, then decoded back into a textual form. The similarity between the original text and the reconstructed text-measured using metrics like cosine similarity-serves as an indicator of how easily the model can learn and reliably represent that particular sample. Samples exhibiting high reconstruction fidelity are identified as ‘easy-to-learn’ and prioritized for data augmentation, as they contribute to more robust and accurate retrieval performance.
The RPDR framework employs an inverse embedding model to quantify the learnability of potential data augmentation samples; this model assesses how reliably the retrieval system can encode and decode given data points. By prioritizing samples demonstrating high learnability – those easily and accurately represented within the embedding space – RPDR ensures that augmented data consistently improves retrieval performance. Evaluation on the PopQA dataset’s long-tail category demonstrates a substantial improvement of 19.5% in Recall@10 (R@10) compared to a strong baseline, NV-Embed, validating the efficacy of this learnability-focused data augmentation strategy.
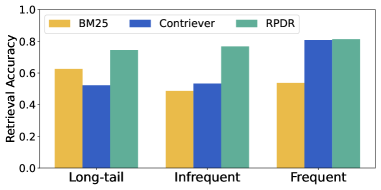
Dynamic Routing: Orchestrating Retrieval Strategies
Retrieval Performance Dynamic Routing (RPDR) incorporates a routing mechanism to optimize retrieval effectiveness by adaptively selecting between multiple retrieval strategies. This system does not rely on a single approach for all queries; instead, it dynamically chooses the most appropriate method based on query characteristics. The routing mechanism allows RPDR to leverage the strengths of different techniques, such as BM25 or its own retrieval process, for individual queries, resulting in improved overall performance compared to using a fixed retrieval strategy.
The retrieval routing mechanism utilizes a sentence-BERT model to categorize incoming queries based on semantic understanding. This model classifies each query and subsequently directs it to either the RPDR (Retrieval-Augmented Generation with Dynamic Routing) system or a conventional BM25 retrieval method. The sentence-BERT model’s output determines which retrieval strategy is most appropriate for the given query, allowing the system to leverage the strengths of both approaches; RPDR for complex queries and BM25 for those better suited to keyword matching. This classification is performed at query time, enabling dynamic selection of the retrieval process.
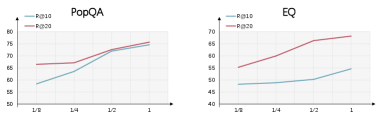
Training of the dynamic routing mechanism utilizes the PopQA Dataset and the EntityQuestions Dataset, both specifically curated for challenging retrieval scenarios. The PopQA Dataset focuses on long-tail questions – those infrequently asked and lacking extensive training examples – sourced from Reddit discussions. EntityQuestions, conversely, centers on questions requiring reasoning about entities and their relationships. Both datasets contribute to the system’s ability to generalize beyond common queries and effectively address information needs related to less frequent topics and complex entity-based inquiries, improving performance on real-world, diverse question sets.
Data filtering is a critical component of the retrieval performance optimization process; training datasets are curated to include only high-quality examples, thereby minimizing the impact of noisy or irrelevant data on model learning. Evaluation on the PopQA dataset demonstrates that incorporating this filtering process into the routing mechanism results in a 4.6% improvement in Recall at 10 (R@10) compared to utilizing the retrieval mechanism – RPDR – without data filtering. This indicates a significant enhancement in the system’s ability to return relevant results within the top 10 retrieved documents.
Dense Retrieval: Capturing Semantic Meaning for Enhanced Accuracy
The retrieval process within RPDR centers on a ‘dense retrieval model’, a sophisticated system designed to represent both questions and relevant passages as numerical vectors, known as ‘embeddings’. These embeddings aren’t simply keyword matches; instead, they capture the semantic meaning of the text. By transforming text into these dense vector representations, the model facilitates a comparison of meaning, rather than just textual similarity. Essentially, questions and passages with similar meanings will have embeddings that are close together in this multi-dimensional vector space, allowing the system to efficiently identify the most relevant information even if the exact keywords don’t align. This approach is crucial for understanding nuanced queries and retrieving accurate answers, forming the foundation of RPDR’s ability to process complex information.
The retrieval model’s effectiveness hinges on a training process called contrastive learning, a technique designed to refine its understanding of semantic relationships. This approach doesn’t simply teach the model to recognize correct answers; it actively shapes its internal representation of language by emphasizing distinctions. During training, the model receives pairs of questions and passages, and its goal is to increase the similarity score between relevant pairs – those where the passage genuinely answers the question. Simultaneously, it’s penalized for assigning high similarity scores to irrelevant pairs, effectively learning to discriminate between meaningful and meaningless connections. This process results in embedding vectors that accurately capture the nuances of language, allowing the model to retrieve passages that are not just superficially similar, but truly relevant to the given query.
The effectiveness of dense retrieval hinges on the quality of its embedding vectors, and recent advancements demonstrate significant improvements through a focus on ‘learnable data’ identified via ‘round-trip prediction’. This technique involves predicting whether a given passage is the correct answer to a question, and then using this prediction to refine the embedding space. By concentrating on data points where the model can reliably learn these relationships – effectively, examples it can confidently predict – the resulting embeddings become more discriminative. This refined representation allows the retrieval model to more accurately gauge the semantic similarity between questions and passages, leading to a substantial increase in retrieval accuracy and a reduction in irrelevant results. The approach ensures that the embedding space effectively captures the nuances of language, enabling the system to confidently address complex queries and minimize the potential for generating inaccurate or unsupported answers.
The refined retrieval model demonstrates a marked ability to confidently answer complex, less frequent questions – often termed ‘long-tail’ queries – and crucially, minimizes the generation of inaccurate or nonsensical responses, known as hallucinations. This enhancement stems from the improved quality of the embedding vectors, allowing for more precise matching of questions to relevant passages. Quantitative evaluation reveals a significant performance gain, with the system achieving an 11.7% improvement in Exact Match (QA Accuracy) when paired with GPT-3.5 for answer generation, compared to utilizing the Contriever retriever. This represents a substantial step towards more reliable and trustworthy question-answering systems, particularly in scenarios demanding nuanced understanding and factual correctness.
The pursuit of robust retrieval systems, as demonstrated by RPDR, echoes a fundamental principle of system design: interconnectedness. The framework’s success isn’t merely about augmenting data, but about establishing a predictive loop – a holistic approach to knowledge representation. Robert Tarjan aptly stated, “Data structures and algorithms are at the heart of computer science.” This sentiment underscores RPDR’s innovation; by focusing on round-trip prediction, the framework builds a more resilient and accurate system, recognizing that improvements in one area-dense retrieval-inevitably impact the broader landscape of long-tail question answering. The study highlights that structure, embodied in the round-trip prediction mechanism, truly dictates behavior.
Beyond the Round Trip
The demonstrated efficacy of RPDR hinges on a deceptively simple premise: a well-trained retriever, seeded with augmented data, can circumvent the need for increasingly complex generative architectures. However, if the system survives on duct tape – consistently requiring carefully crafted augmentation strategies – it’s probably overengineered. The long tail, after all, isn’t a fixed distribution; it shifts, grows, and bifurcates. A framework reliant on pre-defined augmentation risks becoming brittle in the face of true distributional drift.
The focus now must move beyond simply generating more data to understanding what data is truly informative. Round-trip prediction, while effective, is ultimately a proxy. The real signal lies in the underlying semantic space – the relationships between questions, documents, and the subtle nuances of meaning. Modularity, in the form of separate retrieval and generation stages, is appealing, but without a holistic understanding of information flow, it’s an illusion of control.
Future work should explore methods for adaptive augmentation, systems that learn to identify knowledge gaps and generate data tailored to address them. Perhaps the long tail isn’t best tackled by brute force, but by elegant distillation – extracting core principles and representing knowledge in a more compact, transferable form. The goal isn’t simply to answer more questions, but to build a system that understands why it knows, and when it doesn’t.
Original article: https://arxiv.org/pdf/2602.17366.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Gold Rate Forecast
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- Banks & Shadows: A 2026 Outlook
- Gemini’s Execs Vanish Like Ghosts-Crypto’s Latest Drama!
- Wuchang Fallen Feathers Save File Location on PC
- The 10 Most Beautiful Women in the World for 2026, According to the Golden Ratio
- ETH PREDICTION. ETH cryptocurrency
- QuantumScape: A Speculative Venture
- Gay Actors Who Are Notoriously Private About Their Lives
2026-02-23 00:09