Author: Denis Avetisyan
Researchers have developed a new agent capable of planning and executing tasks that require extended reasoning and action sequences, pushing the boundaries of what’s possible with large language models.
KLong utilizes trajectory splitting and progressive reinforcement learning to effectively solve long-horizon challenges like research paper reproduction and automated training pipelines.
While large language models show promise in complex reasoning, effectively tackling extremely long-horizon tasks remains a significant challenge. This paper introduces KLong: Training LLM Agent for Extremely Long-horizon Tasks, detailing an open-source agent trained to address this limitation via a novel combination of trajectory-splitting supervised fine-tuning and progressive reinforcement learning. By leveraging an automated data pipeline-Research-Factory-and strategically managing context within long trajectories, KLong achieves superior performance on benchmarks like PaperBench, surpassing even models with significantly larger parameter counts. Could this approach unlock new capabilities for LLM agents in areas demanding sustained, complex problem-solving?
The Inevitable Constraints of Finite Context
Large Language Models, while demonstrating remarkable abilities in many areas, face inherent constraints when dealing with tasks requiring sustained reasoning or lengthy interactions. This limitation stems from the finite size of their ‘Context Window’ – the amount of text the model can consider at any given time. Essentially, LLMs process information in discrete chunks; when a task necessitates referencing information beyond this window, performance deteriorates significantly. Imagine attempting to understand a novel by only reading a few paragraphs at a time – crucial details and thematic connections are easily lost. Consequently, traditional LLMs often struggle with tasks like summarizing lengthy documents, engaging in extended dialogues, or following complex instructions that span numerous steps, hindering their application in scenarios demanding comprehensive understanding and persistent memory.
Successfully navigating long-horizon tasks demands a fundamental shift from how large language models currently operate; these tasks aren’t simply about providing an output based on a single input, but rather require sustained reasoning and action over extended periods. Traditional models excel at immediate responses, yet falter when faced with challenges that unfold over many steps, necessitating memory of past interactions and the ability to anticipate future needs. This necessitates a move beyond static input-output mappings towards a dynamic process where the model actively maintains an internal state, plans sequential actions, and adapts its strategy based on observed outcomes – essentially, a system capable of ‘thinking’ through a problem rather than merely ‘reacting’ to it. Such a capability is crucial for applications like robotic control, complex game playing, and sophisticated virtual assistance, where the ultimate goal is rarely achieved with a single, direct response.
Existing methods for complex problem-solving with large language models frequently demonstrate an inability to maintain coherence and accuracy over extended interactions or tasks. While proficient at immediate responses, these systems often falter when required to integrate information across numerous steps, remember prior actions, or adapt strategies based on evolving circumstances. This limitation highlights a critical need for LLM agents – systems designed not simply to react to prompts, but to proactively plan, execute, and refine operations over extended periods. Such agents necessitate robust memory capabilities, sophisticated reasoning engines, and the capacity for self-correction, enabling them to navigate intricate challenges that demand sustained cognitive effort – a significant departure from the current paradigm of short-lived, stateless interactions.
![Comparing performance on long-horizon tasks like SWE-bench Verified [21] and Terminal-Bench 2.0 [31] with extremely long-horizon tasks such as MLE-bench [5] and PaperBench [29] reveals significant increases in required time and interaction turns for the latter.](https://arxiv.org/html/2602.17547v1/2_turns.png)
KLong: Architecting for Extended Reasoning
KLong is a newly developed, open-source Large Language Model (LLM) agent designed to overcome limitations in handling tasks requiring extensive reasoning steps – commonly referred to as long-horizon tasks. Traditional LLM agents often struggle with these tasks due to context window constraints and the accumulation of errors over multiple steps. KLong directly addresses these challenges through architectural choices and training methodologies focused on enabling successful navigation of complex, multi-stage problems. The agent’s open-source nature facilitates community contribution, research, and customization for a wide range of applications requiring extended reasoning capabilities.
KLong utilizes the GLM-4.5-Air-Base large language model as its foundational component, enabling its advanced reasoning capabilities. GLM-4.5-Air-Base is a 13 billion parameter model pre-trained on a substantial corpus of text and code data. This base model provides KLong with inherent language understanding and generation abilities. Further enhancements are implemented on top of GLM-4.5-Air-Base, specifically tailored to improve performance on tasks requiring extended reasoning and planning, exceeding the typical context window limitations of standard LLMs. These techniques build upon the pre-trained knowledge within GLM-4.5-Air-Base to facilitate more complex problem-solving.
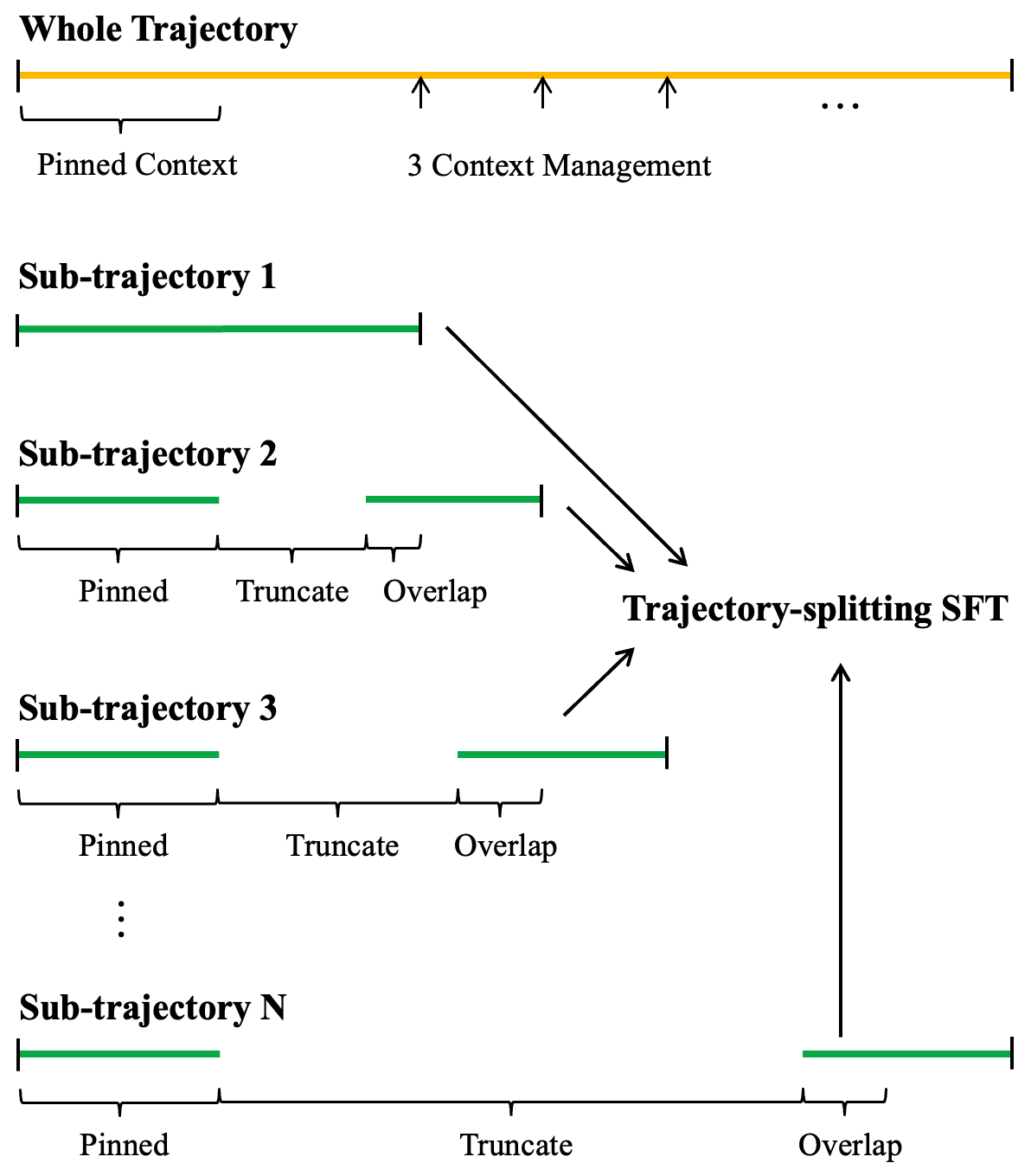
KLong utilizes Trajectory-Splitting Supervised Fine-Tuning (SFT) as a core mechanism for handling tasks exceeding the context window limitations of the underlying language model. This technique involves recursively decomposing a long-horizon task into a series of shorter, more focused sub-trajectories. Each sub-trajectory is then processed independently, allowing the agent to maintain reasoning coherence within the model’s context limits. The decomposed segments are sequentially executed, with the output of one segment serving as input for the next, effectively enabling KLong to address tasks that would otherwise be intractable due to length constraints. This approach improves performance on tasks requiring multi-step reasoning and planning.
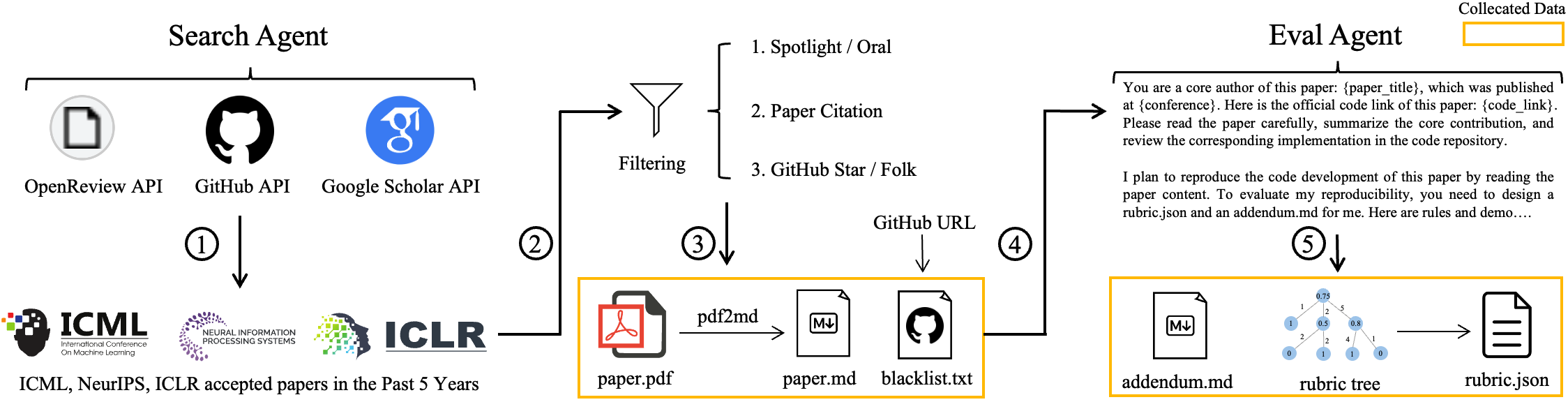
Evaluating Robustness: The Research-Factory Pipeline
Performance evaluation of KLong and similar models relies on the o3-mini judge model, a component within the Research-Factory automated pipeline. This pipeline is designed to generate a comprehensive suite of benchmarks used for assessment. Research-Factory systematically creates evaluation tasks and manages the execution of those tasks using o3-mini to score the outputs. The use of an automated pipeline ensures consistency and scalability in the evaluation process, allowing for reproducible results and efficient comparison of model performance across various tasks and configurations.
The Research-Factory pipeline incorporates automated generation of Automated Evaluation Rubrics to standardize performance assessment. These rubrics define objective criteria for evaluating model outputs, moving beyond subjective human judgment. This automation facilitates consistent scoring across diverse tasks and models, addressing potential evaluator bias and ensuring reproducibility. By formalizing the evaluation process, the Research-Factory enables scalable benchmarking, allowing for efficient comparison of numerous models and rapid iteration on research findings. The rubrics are designed to be task-specific, capturing the nuances of each benchmark and providing detailed feedback on model performance.
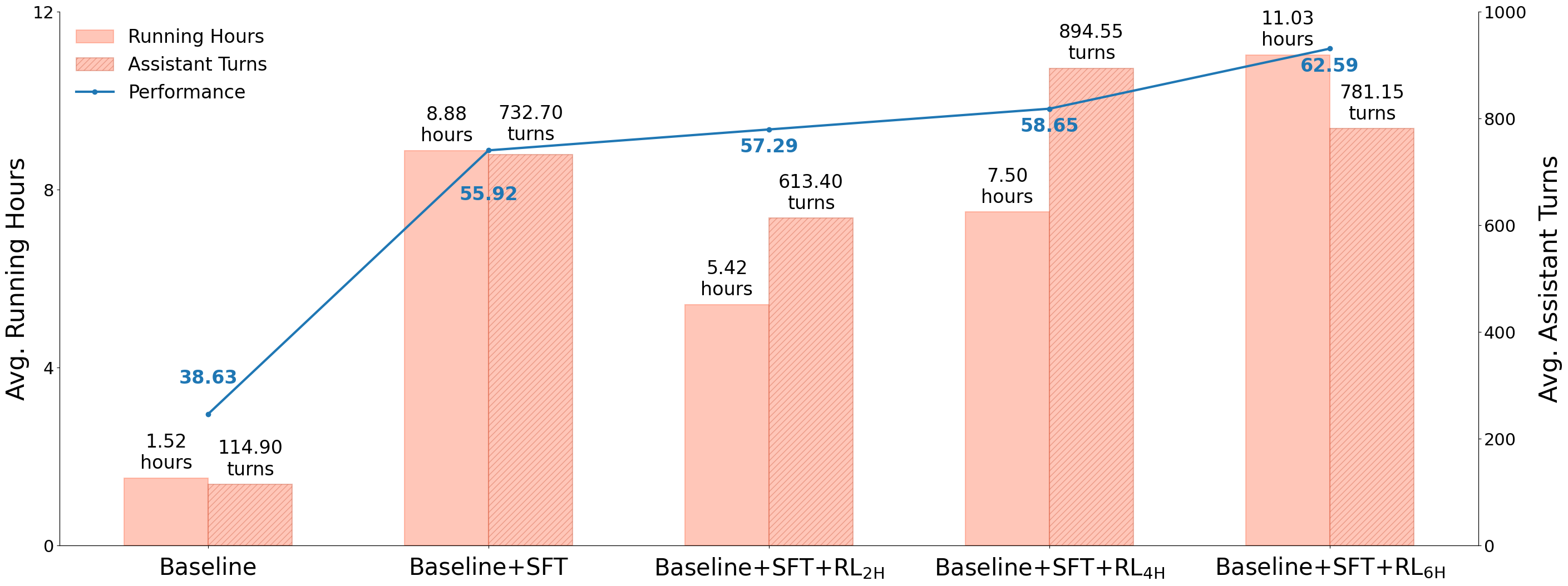
KLong’s capabilities were assessed through tasks requiring the reproduction of research papers, a methodology designed to evaluate both comprehension of complex algorithms and proficient coding skills. This evaluation utilized the PaperBench benchmark, which presents a series of tasks based on published research. KLong achieved an average score of 62.59 on PaperBench, indicating a moderate level of performance in replicating published results and demonstrating an ability to translate theoretical concepts into functional code. This score provides a quantitative measure of KLong’s capacity for complex problem-solving and implementation.
The Trajectory of Progress: Enhancing Long-Horizon Performance
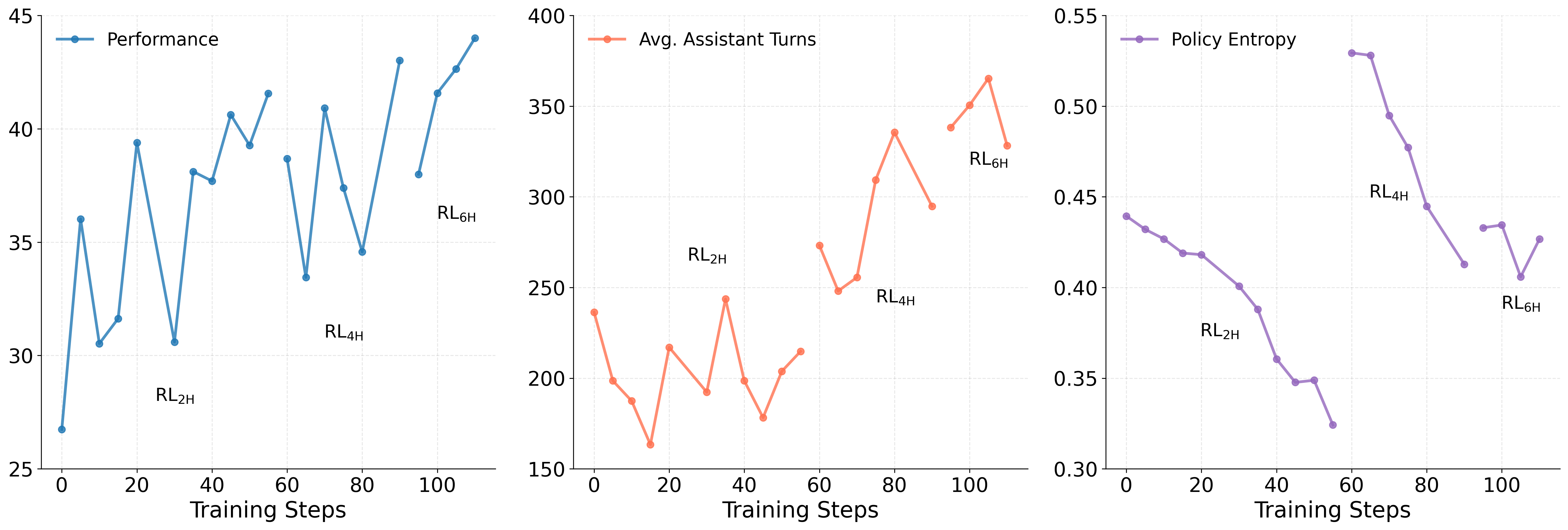
KLong’s performance benefits from a training methodology known as Progressive Reinforcement Learning, a technique designed to enhance its ability to tackle complex, extended tasks. Rather than immediately confronting the full scope of a long-horizon challenge, the system begins with simpler iterations, progressively increasing the difficulty and length of the problems it addresses. This gradual approach allows the model to build a robust foundation of knowledge and strategic thinking, effectively mastering foundational skills before moving on to more intricate scenarios. By incrementally raising the bar, Progressive RL fosters a more stable and efficient learning process, ultimately leading to significant improvements in KLong’s performance across sustained interactions and complex reasoning tasks.
To address the challenges of maintaining performance across lengthy interactions, KLong leverages techniques such as Loop and Iterative Research, both designed to enhance memory efficiency. Loop allows the model to selectively retain and revisit relevant information from past turns within a conversation, preventing the decay of crucial context. Simultaneously, Iterative Research enables KLong to dynamically refine its understanding by revisiting and updating its internal knowledge base as the task unfolds. This dual approach minimizes the computational burden of processing extensive histories while ensuring that the model’s responses remain coherent and grounded in the entirety of the preceding exchange, ultimately contributing to sustained, high-quality performance on long-horizon tasks.
Maintaining consistent coherence and relevance proves paramount when navigating extended conversational turns, and KLong addresses this challenge through sophisticated context management strategies. These techniques allow the model to effectively track and utilize information accumulated throughout a prolonged interaction, preventing the decay of understanding often seen in simpler models. Empirical results demonstrate the efficacy of this approach, with KLong achieving a notable 23.96% performance improvement over a standard Supervised Fine-Tuning (SFT)-only baseline. This advancement signifies a substantial leap in the model’s ability to engage in meaningful, sustained dialogue, offering a more fluid and logically consistent user experience across longer conversational horizons.
Towards Adaptive Intelligence: Future Directions
The adaptability of KLong is poised to significantly improve through the expansion of its OpenHands Scaffolding. This framework, designed to break down complex tasks into manageable steps, currently facilitates reasoning and action within a defined scope; however, extending its capabilities to encompass a broader spectrum of challenges is crucial for real-world application. By increasing the diversity of tasks OpenHands can support – from intricate robotic manipulation to nuanced conversational scenarios – KLong gains the flexibility to address previously insurmountable problems. This isn’t merely about adding more skills, but fostering a systemic ability to learn and generalize across domains, ultimately creating an agent capable of tackling unforeseen complexities with greater robustness and efficiency.
The true potential of KLong lies in its ability to move beyond simulated environments and address challenges within the complexities of the real world. Integrating this agent with a diverse toolkit – encompassing everything from web browsers and database interfaces to robotic control systems and specialized APIs – dramatically expands its sphere of influence. This broadened connectivity isn’t simply about accessing more functions; it’s about enabling KLong to perceive, interact with, and ultimately solve problems situated within authentic, dynamic contexts. Such integration promises a shift from narrowly defined tasks to holistic problem-solving, allowing the agent to manage multifaceted scenarios requiring adaptability and resourcefulness – a crucial step towards genuinely versatile artificial intelligence.
Advancements in reinforcement learning algorithms, coupled with sophisticated context management techniques, are dramatically extending the capacity of artificial agents to engage in long-horizon reasoning. Recent studies demonstrate a substantial leap in performance, with agents now capable of sustaining conversations and complex task execution over significantly longer durations – an impressive increase from 114.90 assistant turns achieved with trajectory-splitting supervised fine-tuning, to a remarkable 732.70 turns. This progress suggests that by optimizing how agents learn from experience and retain relevant information across extended interactions, their ability to tackle intricate, multi-step problems will continue to expand, paving the way for more versatile and robust AI systems capable of handling increasingly complex real-world scenarios.
The pursuit of increasingly complex systems invariably reveals their inherent temporality. KLong, with its approach to long-horizon tasks through trajectory splitting and progressive reinforcement learning, exemplifies this principle. The architecture isn’t static; it evolves through training, adapting to the demands of extended reasoning. As Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” This echoes within KLong’s design; the agent’s capabilities are defined not by inherent creativity, but by the structured knowledge and training it receives, extending its reach across complex, multi-step problems. Every architecture lives a life, and we are just witnesses to its progression.
What Remains to be Seen?
The pursuit of long-horizon agency, as exemplified by KLong, inevitably reveals the brittleness inherent in any system attempting to span extended periods. While trajectory splitting and progressive reinforcement learning offer pragmatic improvements, they address symptoms, not the underlying decay of information and the compounding of error. Each successful reproduction of a research paper, each extended task completion, is not a step toward true intelligence, but a temporary deferral of inevitable entropic drift. The question isn’t merely whether an agent can complete a long task, but how gracefully it degrades as its internal model diverges from reality.
Future work will undoubtedly focus on enhancing context management and reward shaping. However, a more fundamental challenge lies in developing architectures that embrace, rather than resist, the passage of time. An agent capable of forgetting strategically, of pruning irrelevant information, may prove more robust than one attempting to retain an ever-expanding, ultimately unmanageable, knowledge base. Architecture without history is fragile; an architecture aware of its own historical limitations may be the only path to genuine longevity.
Every delay in achieving generalized long-horizon agency is, in a sense, the price of understanding. The true measure of progress will not be speed, but the elegance with which these systems accommodate their own inevitable obsolescence-a quiet acceptance of decay as a fundamental principle of existence.
Original article: https://arxiv.org/pdf/2602.17547.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Gold Rate Forecast
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- Banks & Shadows: A 2026 Outlook
- Gemini’s Execs Vanish Like Ghosts-Crypto’s Latest Drama!
- The 10 Most Beautiful Women in the World for 2026, According to the Golden Ratio
- QuantumScape: A Speculative Venture
- ETH PREDICTION. ETH cryptocurrency
- Wuchang Fallen Feathers Save File Location on PC
- 9 Video Games That Reshaped Our Moral Lens
2026-02-22 19:14