Author: Denis Avetisyan
A new framework optimizes the discovery of meaningful sequential patterns within databases, drastically improving efficiency and relevance.
This review details a comprehensive approach to targeted sequential rule mining, leveraging pruning strategies, similarity metrics, and optimized database techniques.
Despite the power of sequential rule mining for uncovering temporal dependencies, existing methods often generate numerous irrelevant patterns, incurring significant computational cost and hindering effective analysis. This paper, ‘Guided Exploration of Sequential Rules’, addresses this challenge by introducing a targeted framework for efficiently discovering user-centric sequential rules. Utilizing pruning strategies, upper bounds, and novel similarity metrics, our approach minimizes computational overhead while maximizing the relevance of discovered patterns for both frequency and utility mining tasks. Can this targeted exploration of sequential data unlock more personalized and actionable insights across diverse application domains?
Data’s Paradox: From Volume to Value
The sheer volume of data generated daily – from financial transactions and social media interactions to sensor networks and scientific experiments – presents a paradox: while information abounds, meaningful understanding often remains elusive. Simply accumulating data, often referred to as ‘big data’, does not inherently translate to improved decision-making or innovation. The true value lies in extracting actionable insights – the identification of previously unknown, potentially useful patterns and relationships hidden within the data. These insights enable organizations to anticipate trends, optimize processes, and gain a competitive advantage. Consequently, the focus has shifted from mere data storage to sophisticated analytical techniques capable of transforming raw information into strategic knowledge, driving a demand for tools and methodologies that can effectively unlock the potential within these vast datasets.
Pattern mining transcends the limitations of basic data aggregation by employing algorithms designed to unearth previously unknown relationships within datasets. Rather than simply summing values or calculating averages, these techniques – encompassing association rule learning, sequence mining, and clustering – automatically identify recurring trends, predictable sequences, and groupings of similar data points. This automated discovery is crucial because many valuable insights are hidden within the sheer volume of modern data, too complex for manual analysis. For instance, market basket analysis, a common pattern mining application, reveals that customers who purchase diapers also frequently buy beer, a correlation unlikely to be discovered through simple sales reports. By moving beyond descriptive statistics, pattern mining empowers organizations to proactively anticipate future events, personalize customer experiences, and optimize operational efficiency.
Conventional data mining techniques frequently excel at identifying static associations – for example, customers who consistently purchase product A also buy product B. However, these methods often struggle to capture the dynamic interplay of events unfolding over time. Consider, for instance, the shifting correlation between weather patterns and ice cream sales; a hot day reliably boosts sales, but the strength of that connection might vary depending on the day of the week, promotional campaigns, or even concurrent news events. Traditional algorithms, designed to detect fixed relationships, miss these crucial temporal nuances, potentially leading to inaccurate predictions and ineffective strategies. Consequently, research is increasingly focused on developing more sophisticated techniques capable of modeling sequential data and uncovering patterns that evolve with time, recognizing that many real-world phenomena are not static but are, instead, processes unfolding across a timeline.
Sequential Insights: Uncovering Time’s Influence
Sequential rule mining differentiates itself from conventional pattern mining techniques by incorporating the temporal dimension of data. Traditional methods treat all item occurrences as independent, whereas sequential mining explicitly accounts for the order in which events happen. This is achieved by identifying patterns where the occurrence of one item or set of items is predictably followed by another, within a defined timeframe. Consequently, sequential rule mining is particularly useful in scenarios where the sequence of events is critical, such as customer purchase history, web clickstreams, or medical diagnosis sequences, allowing for the discovery of relationships that would be missed by order-agnostic approaches.
Sequential pattern mining enables the identification of temporal relationships between events, allowing for predictions about future occurrences based on past observations. For example, analysis of customer purchase history can reveal that a significant proportion of customers who purchase product X on a given date are likely to purchase product Y within a defined timeframe, such as the following week. This predictive capability extends beyond simple co-occurrence; it explicitly models the order and timing of events, providing insights into customer behavior, trend forecasting, and proactive recommendations. The identified patterns are not merely correlations but rather probabilistic sequences indicating a higher likelihood of a specific event following another within a specified period.
Association rules in sequential pattern mining establish relationships between items occurring within a defined sequence, utilizing metrics to assess their statistical significance. These rules are typically expressed in the form “If antecedent, then consequent,” where both are sets of items. The strength of a rule is quantified by support, which indicates the frequency of the itemset within the dataset, and confidence, representing the probability of the consequent occurring given the antecedent. Lift, another key metric, normalizes confidence by dividing it by the prior probability of the consequent, indicating whether the antecedent and consequent are statistically dependent. Support(X \rightarrow Y) = \frac{Number\, of\, transactions\, containing\, both\, X\, and\, Y}{Total\, number\, of\, transactions} and Confidence(X \rightarrow Y) = \frac{Support(X \rightarrow Y)}{Support(X)}. Higher values for these metrics generally indicate stronger and more reliable sequential relationships.
Confidence, a key metric in sequential rule mining, quantifies the reliability of identified patterns by calculating the probability that a subsequent item will occur given the presence of a preceding item or sequence. Formally, confidence is determined as the ratio of the number of transactions containing both the antecedent and consequent, divided by the number of transactions containing only the antecedent. A confidence value ranges from 0 to 1, with higher values indicating a stronger and more reliable association. For example, a rule stating “customers who buy X are likely to buy Y” with a confidence of 0.7 implies that 70% of transactions containing X also contain Y. This metric allows for the filtering of spurious or weak associations, focusing on patterns with statistically significant predictive power.
Targeted Discovery: Focusing the Search
Targeted pattern mining (TaPM) deviates from traditional, exhaustive pattern discovery by incorporating user-defined preferences and constraints directly into the mining process. This allows analysts to focus computational resources on identifying patterns relevant to specific objectives, rather than sifting through a potentially vast space of irrelevant results. These constraints can take various forms, including item selection, minimum or maximum lengths of patterns, or restrictions on the types of relationships discovered. By explicitly defining these parameters, TaPM enables a more efficient and directed search for actionable insights, particularly valuable in domains with large datasets and well-defined analytical goals.
Database filtering and upper bound calculation are core techniques employed in targeted pattern mining to optimize search efficiency. Database filtering pre-processes the dataset by removing items that do not meet pre-defined criteria, directly reducing the size of the search space. Upper bound calculation, utilizing techniques such as the max-min principle, establishes a theoretical maximum possible utility or support for a pattern; if this upper bound falls below a user-defined threshold, the pattern and all its extensions are pruned from the search, avoiding unnecessary computation. These methods operate prior to, or during, the pattern growth process, significantly decreasing the number of candidate patterns that require evaluation and thus improving performance, particularly on large datasets.
Targeted pattern mining (TaPM) utilizes quantitative metrics to refine the pattern discovery process by eliminating results lacking practical significance. Specifically, a minimum support threshold defines the percentage of transactions a pattern must appear in to be considered frequent, while utility thresholds assess patterns based on the total profit or benefit they contribute. Patterns failing to meet these pre-defined thresholds are discarded, substantially reducing the size of the output pattern set and focusing analysis on items of genuine interest. These thresholds allow users to define what constitutes a meaningful pattern within the context of their specific application and data characteristics.
Utility-based pattern mining evaluates itemsets based on a combined measure of frequency and profit, differing from traditional association rule mining which primarily focuses on frequency via support and confidence. The utility metric calculates the profit generated by a pattern, considering both the number of transactions containing the itemset and the associated profit margin of each item. To facilitate efficient computation, the utility-list data structure is employed, representing transactions in a condensed format optimized for utility calculations. Implementation of this approach, utilizing the utility-list, has demonstrated performance improvements of up to one order of magnitude – a ten-fold increase in speed – when compared to conventional utility mining algorithms across benchmark datasets.
Beyond Correlation: Defining Pattern Relevance
Determining whether a discovered pattern truly addresses a user’s intent necessitates a formal assessment of its resemblance to the original query or desired outcome. Simply identifying a frequent combination of items isn’t enough; a relevant pattern must closely align with what the user seeks. This evaluation hinges on quantifying the similarity between the discovered pattern and the target, moving beyond simple presence or absence to a graded measure of correspondence. Without such quantification, the system risks presenting numerous patterns, only a fraction of which are genuinely useful to the user, hindering effective data exploration and knowledge discovery. Establishing a robust method for assessing this relevance is therefore crucial for any pattern mining application, ensuring that the most pertinent insights are prioritized and delivered.
Determining how closely a discovered pattern aligns with a user’s intent necessitates quantifiable measures of similarity, and established metrics like Target Rule Dice Similarity (TROS) and Target Rule Jaccard Similarity (TRJS) offer formal approaches to this challenge. These metrics operate by comparing the sets of items comprising both the discovered pattern – the ‘rule’ – and the user’s initial query, or ‘target’. TROS calculates similarity based on the intersection of items, weighted by the total number of unique items in both sets, while TRJS focuses on the ratio of shared items to the total number of unique items. Both TROS and TRJS yield a value between zero and one, providing a standardized score that reflects the degree of overlap and, consequently, the relevance of the discovered pattern to the user’s specified criteria. A higher score indicates greater similarity and a stronger indication that the pattern addresses the user’s information need.
Beyond simply identifying patterns, understanding how common those patterns are within the data remains crucial for meaningful analysis. Support calculation, traditionally expressed as the proportion of transactions containing a given pattern, provides this essential prevalence measure. Frequency metrics further refine this understanding by quantifying how often individual items or combinations appear, offering insights into their statistical significance. These calculations aren’t merely academic; they directly inform the relevance of discovered patterns – a rare, highly specific combination holds different weight than a ubiquitous one. Consequently, even with advanced similarity metrics, robust support and frequency analysis continue to serve as foundational tools for extracting actionable intelligence from complex datasets, enabling researchers to distinguish between genuine discoveries and statistical noise.
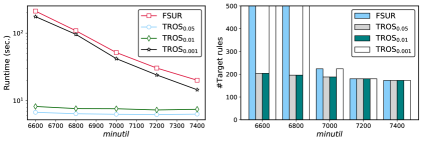
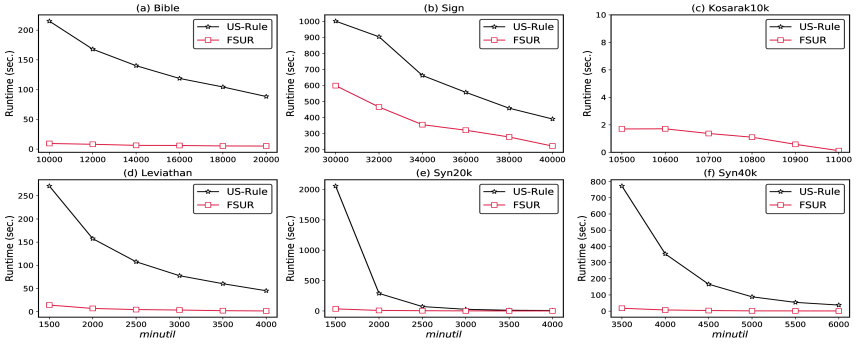
The developed solution demonstrates a significant advancement in frequent pattern mining, achieving performance levels comparable to the current state-of-the-art TaSRM algorithm. Critically, testing on the Bible dataset revealed a substantial reduction in computational effort – specifically, a 20-fold decrease in the number of expansions required compared to the baseline FSURfilter approach. This increased efficiency suggests the method can process larger datasets with fewer resources, potentially unlocking new insights from complex information while maintaining accuracy and relevance in pattern discovery. The observed performance indicates a practical and scalable solution for applications demanding robust and efficient frequent pattern analysis.
Refining Knowledge: Expanding and Iterating
The creation of increasingly sophisticated knowledge bases often necessitates moving beyond simple, initial rules; rule expansion techniques provide a means to achieve this. By systematically adding conditions to the left or right side of an existing rule, researchers can generate more nuanced and informative statements without sacrificing logical consistency. Left expansion narrows the rule’s applicability by adding preconditions, ensuring it holds true only under specific circumstances, while right expansion adds further consequences, detailing more of what follows from the initial conditions. This iterative process allows for the development of rules that are both precise and comprehensive, capturing a greater degree of complexity within the data and improving the overall predictive power of the system. The ability to build upon existing knowledge, rather than starting anew, represents a significant advancement in automated knowledge discovery and refinement.
The process of iteratively refining existing rules represents a powerful strategy for enhancing the precision and predictive capabilities of knowledge discovery systems. Rather than simply generating rules and accepting their initial accuracy, these techniques allow for a cycle of evaluation and adjustment. A rule’s performance is assessed against new data or refined metrics, and based on this assessment, the rule is modified – perhaps by adjusting thresholds, adding exceptions, or incorporating new conditions. This iterative process isn’t merely about correcting errors; it’s about progressively distilling knowledge, allowing rules to become more nuanced and better equipped to handle the complexities of real-world data. Consequently, the predictive power of the system improves over time, as rules become increasingly robust and reliable, offering a significant advantage over static, one-time rule generation.
The synergy between targeted pattern mining and rule expansion presents a powerful avenue for automated knowledge discovery. By first identifying frequently occurring, yet potentially overlooked, patterns within data, researchers can then strategically expand existing rules to incorporate these insights. This process moves beyond simple generalization; instead, it focuses rule refinement on areas where new, meaningful relationships are likely to exist. The result is a system capable of not only confirming known associations but also proactively uncovering previously hidden knowledge, offering a pathway to build more comprehensive and insightful models from complex datasets. This iterative approach, driven by data-derived patterns, promises to accelerate discovery across numerous scientific disciplines.
Analysis reveals that strategically limiting the scope of rule expansion-applying tighter boundaries to the process-yields a noteworthy reduction in the number of generated expansions. This effect is particularly pronounced when working with datasets characterized by lower density, suggesting that the benefits of constrained expansion are amplified in scenarios where data points are more sparsely distributed. These findings underscore the potential for significant optimization within rule-based systems; by carefully calibrating expansion parameters, computational resources can be conserved, and the efficiency of knowledge discovery processes improved, without necessarily sacrificing the accuracy or predictive capability of the resulting rules.
The pursuit of efficient sequential rule mining, as detailed in this exploration of pruning strategies and upper bounds, feels less like innovation and more like delaying the inevitable. The article meticulously outlines techniques to tame computational cost, a noble effort, but one destined to be outpaced by ever-growing datasets. It’s a temporary reprieve, a polishing of the chains. Robert Tarjan observed, “Programming is the art of defining a problem so that a computer can solve it.” This feels painfully apt; the problem isn’t finding patterns, it’s perpetually redefining ‘efficient’ to accommodate the limitations of the tools. The bug tracker will, inevitably, record the failures of even the most elegant upper bounds. It doesn’t deploy – it lets go.
What’s Next?
The pursuit of ‘efficient’ sequential rule mining feels…familiar. It’s always thus: a clean algorithm, a clever pruning strategy, and then production data arrives, cheerfully defying all assumptions. The initial elegance, inevitably, degrades into a tangled mess of edge cases and hastily-applied patches. They’ll call it AI and raise funding, naturally. The focus on utility and frequency is sensible, certainly, but it skirts the issue of meaning. A frequent sequence is not necessarily a useful one, and determining utility remains stubbornly subjective.
One anticipates the inevitable arms race of similarity metrics. Defining ‘interestingness’ will become a black art, a constant recalibration of thresholds to avoid either drowning in noise or missing genuinely novel patterns. The current framework offers optimization, yes, but optimization of a fundamentally limited process. The real bottleneck isn’t computational cost; it’s the human cost of interpreting the results.
It’s worth remembering that this entire field used to be a simple bash script. The complexity now suggests a creeping realization: the data doesn’t want to be understood. Or, more accurately, it resists any attempt at neat categorization. Future work will likely involve grappling with uncertainty, embracing approximation, and accepting that perfect patterns are a comforting illusion. Tech debt is just emotional debt with commits, after all.
Original article: https://arxiv.org/pdf/2602.16717.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- Gold Rate Forecast
- Wuchang Fallen Feathers Save File Location on PC
- Banks & Shadows: A 2026 Outlook
- Gemini’s Execs Vanish Like Ghosts-Crypto’s Latest Drama!
- HSR 3.7 breaks Hidden Passages, so here’s a workaround
- The 10 Most Beautiful Women in the World for 2026, According to the Golden Ratio
- QuantumScape: A Speculative Venture
- ETH PREDICTION. ETH cryptocurrency
2026-02-22 12:32