Author: Denis Avetisyan
A new framework uses the power of large language models and contextual retrieval to automatically generate human-understandable topic labels for short-form text.

NTLRAG leverages retrieval-augmented generation to create narrative topic labels, improving upon traditional topic modeling techniques for short texts.
While topic modeling effectively identifies themes within large text corpora, interpreting the resulting clusters often relies on unstructured keyword lists that lack semantic clarity. This paper introduces ‘NTLRAG: Narrative Topic Labels derived with Retrieval Augmented Generation’-a framework leveraging retrieval-augmented generation to create human-interpretable narrative labels for topic model outputs. By synthesizing information via RAG and employing chain-of-thought reasoning, NTLRAG generates context-rich descriptions that demonstrably improve interpretability and usability compared to traditional methods. Can this approach unlock more nuanced understandings of complex datasets and facilitate more effective communication of topic modeling results?
The Inherent Limitations of Superficial Analysis
Conventional topic modeling approaches frequently falter when applied to short-form text, such as tweets or text messages. These techniques, designed for longer documents with richer contextual cues, often generate overly broad or nonsensical topic labels because they struggle to discern subtle semantic differences. The inherent brevity of short texts limits the statistical information available for accurate analysis, leading algorithms to group diverse content under vague umbrellas like “general news” or “social commentary.” This lack of granularity diminishes the utility of topic modeling for tasks requiring precise categorization or insightful content discovery, highlighting a significant challenge in the field of natural language processing and the need for specialized methods tailored to the unique characteristics of short text data.
While algorithms like Latent Dirichlet Allocation and Non-Negative Matrix Factorization represent cornerstones of topic modeling, their effectiveness diminishes when applied to short texts. These methods fundamentally operate by identifying statistical co-occurrence of terms, assuming that words appearing together signal a shared topic. However, brevity often strips away crucial contextual cues, leading these algorithms to misinterpret nuanced meaning or conflate disparate concepts. The reliance on simple term frequency can result in generic topic labels that fail to capture the specific intent or subject matter embedded within short texts, particularly in domains characterized by ambiguity, slang, or evolving language use. Consequently, more sophisticated techniques are needed to discern meaning from these data-scarce environments, incorporating semantic understanding and contextual awareness beyond basic statistical analysis.
The Necessity of Contextual Enrichment
Recent advancements in natural language processing have yielded techniques like Word Embeddings and Contextual Topic Models that enhance topic coherence by moving beyond simple co-occurrence statistics. Word Embeddings, such as Word2Vec, GloVe, and FastText, represent words as dense vectors in a multi-dimensional space, where semantically similar words are positioned closer together. Contextual Topic Models, building on this foundation, further refine understanding by considering the surrounding text when generating these embeddings; models like BERT, RoBERTa, and Sentence Transformers create dynamic word representations that are sensitive to context. This allows topic modeling algorithms to identify more nuanced relationships between terms and produce topics that are more semantically cohesive and interpretable, addressing a limitation of traditional methods like Latent Dirichlet Allocation (LDA) which treat words in isolation.
BERTopic and the Structural Topic Model (STM) represent advancements in topic modeling by integrating the strengths of word embeddings with traditional clustering and statistical techniques. BERTopic leverages pre-trained language models, such as BERT, to generate document and word embeddings, which are then clustered to identify topics. STM, conversely, explicitly models topic prevalence and document-specific topic proportions using statistical priors and covariates-metadata associated with each document-to enhance topic coherence and interpretability. Both methods move beyond simple co-occurrence statistics by capturing semantic relationships between terms and allowing for the incorporation of external knowledge, leading to more refined and actionable topic discovery compared to methods like Latent Dirichlet Allocation (LDA).
Traditional topic modeling frequently relies on document-term matrices without explicitly considering the broader contextual information surrounding those terms. Robust information retrieval – encompassing techniques like semantic search and knowledge graph traversal – addresses this limitation by identifying documents or passages that are semantically related to the initial seed terms, even if they don’t share direct keyword matches. This contextual enrichment is crucial because it provides additional data points for embedding models to learn more nuanced semantic relationships. Without effective information retrieval, the resulting embeddings may be limited by the scope of the initial dataset, hindering the ability to generate coherent and meaningful topics, particularly when dealing with specialized domains or ambiguous terminology.
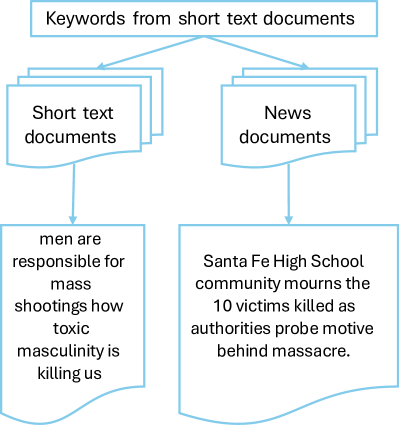
NTLRAG: A Framework for Meaningful Topic Representation
NTLRAG represents an advancement over conventional topic modeling techniques by integrating Retrieval-Augmented Generation (RAG). Traditional topic modeling often identifies keywords or short phrases as representative of a document’s content. NTLRAG, however, leverages RAG to retrieve relevant contextual information during the topic discovery process. This retrieved information is then used to generate more comprehensive and coherent “Narrative Topic Labels” – descriptive summaries rather than simple keywords – which provide a richer understanding of the document’s thematic focus. The incorporation of retrieved context aims to improve both the informativeness and human interpretability of the generated topic labels, addressing limitations inherent in purely statistical topic modeling approaches.
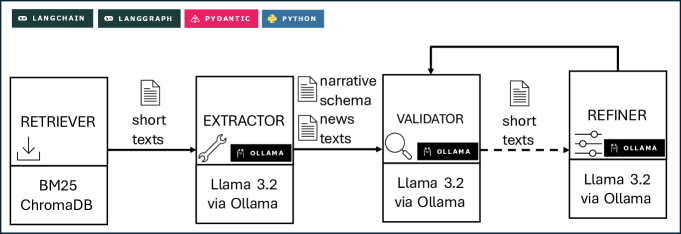
NTLRAG employs the BM25 ranking function for initial document retrieval, prioritizing documents based on keyword relevance to the input query. To facilitate semantic search and capture nuanced relationships between terms, word embeddings are generated and stored within a ChromaDB vector database. This allows the system to move beyond simple keyword matching and identify documents with similar meaning, even if they don’t share the same vocabulary. ChromaDB’s vector storage enables efficient similarity calculations, significantly reducing search time and improving the precision of retrieved information for topic label generation.
NTLRAG differentiates itself from standard topic modeling by leveraging a predefined Narrative Schema to structure topic discovery. This approach moves beyond keyword extraction, generating topic labels formulated as descriptive summaries of the content. Evaluation through human assessment yielded an average interpretability rating of 2.467, indicating a substantial improvement in the clarity and comprehensibility of the generated labels compared to traditional methods. The Narrative Schema provides contextual grounding, ensuring that labels accurately reflect the underlying narrative structure and semantic meaning of the text.
Demonstrating Superior Clarity and Human Alignment
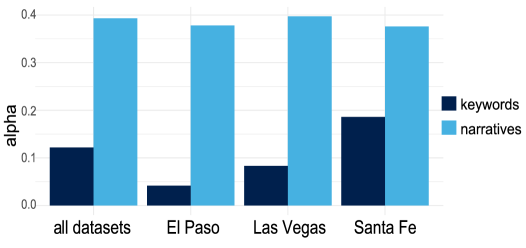
Evaluations reveal that the ‘Narrative Topic Labels’ produced by NTLRAG offer substantially improved clarity for human understanding when compared to conventional keyword-based summaries. Specifically, human evaluators assigned an average interpretability rating of 2.467 to the narratives generated by NTLRAG, a notably higher score than the 1.61 achieved by simple keyword lists. This difference suggests a significant advancement in conveying complex information in a manner more readily grasped by people, moving beyond isolated terms to a more cohesive and meaningful representation of the underlying topic.
The exceptional clarity of narratives generated by NTLRAG is powerfully demonstrated by evaluator assessments; an astounding 49 out of 50 evaluated narratives achieved the highest possible rating from human judges. This near-unanimous positive response underscores the system’s ability to synthesize information into readily understandable and meaningful summaries. Such a high degree of consensus indicates that the generated narratives aren’t simply different from keyword lists, but are fundamentally more coherent and accessible to human understanding, suggesting a significant advancement in the quality of information presentation and a potential bridge towards more effective communication of complex data.
Evaluations reveal a strong preference for narratives generated by NTLRAG over traditional keyword lists when conveying information. A remarkable 94.73% of evaluators indicated they either preferred the narrative format or considered it equivalent to keywords in clarity and usefulness. Notably, narratives were strictly favored by evaluators in 63.25% of instances, suggesting a substantial benefit in how information is presented and understood. This demonstrates that structuring data into coherent narratives, rather than simply listing keywords, significantly enhances user perception and provides a more accessible means of grasping complex topics.
The pursuit of clarity in topic modeling, as demonstrated by NTLRAG, echoes a fundamental tenet of information theory. Claude Shannon observed, “The most important thing in communication is to convey information accurately.” NTLRAG directly addresses this by moving beyond simple keyword extraction-often ambiguous and lacking nuance-towards generating narrative topic labels. This framework insists on a more rigorous approach to representing the underlying themes within short text, establishing a defined and interpretable structure. The emphasis on retrieval-augmented generation isn’t merely about improving performance; it’s about creating a system where the meaning communicated is demonstrably linked to the source material, aligning with Shannon’s core principle of accurate information transfer.
Future Directions
The pursuit of human-interpretable topic labels, as exemplified by NTLRAG, inevitably encounters the fundamental limits of semantic representation. While retrieval-augmented generation offers a pragmatic improvement over purely statistical approaches, it does not resolve the inherent ambiguity present in natural language. The elegance of a solution will not be measured by its performance on benchmark datasets, but by its demonstrable adherence to logical consistency. A truly robust system must be provably capable of discerning genuine thematic coherence, not merely mimicking it.
Current methodologies remain tethered to the vagaries of large language models, introducing a level of stochasticity that is anathema to precise scientific inquiry. The reliance on these models, while expedient, obscures the underlying representational structure. Future work should prioritize the development of more formal, mathematically grounded approaches to narrative schema extraction, minimizing the ‘black box’ effect. One anticipates that any meaningful advancement will require a move beyond superficial correlation and towards a deeper understanding of causal relationships within textual data.
The brevity of the input texts considered presents a particular challenge. While NTLRAG demonstrates a capacity to distill meaning from short-form content, extending this capability to longer, more complex narratives will demand a significant refinement of the retrieval and generation processes. Ultimately, the goal is not simply to label topics, but to construct a formal, axiomatic framework for narrative understanding – a task that, while ambitious, remains the only path towards true semantic elegance.
Original article: https://arxiv.org/pdf/2602.17216.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- Gold Rate Forecast
- Wuchang Fallen Feathers Save File Location on PC
- Banks & Shadows: A 2026 Outlook
- The 10 Most Beautiful Women in the World for 2026, According to the Golden Ratio
- Gemini’s Execs Vanish Like Ghosts-Crypto’s Latest Drama!
- HSR 3.7 breaks Hidden Passages, so here’s a workaround
- QuantumScape: A Speculative Venture
- ETH PREDICTION. ETH cryptocurrency
2026-02-22 10:57