Author: Denis Avetisyan
A new study analyzes a decade of social media data to reveal how discussions about hydrogen energy have evolved regionally and globally.
Translation-based cross-lingual classification, combined with topic modeling, effectively identifies key themes in multilingual Twitter data from 2013-2022.
Analyzing multilingual social media presents a significant challenge due to linguistic diversity and data volume. This study, ‘Evaluating Cross-Lingual Classification Approaches Enabling Topic Discovery for Multilingual Social Media Data’, addresses this by evaluating methods for cross-lingual relevance classification applied to a decade of Twitter data on hydrogen energy-spanning English, Japanese, Hindi, and Korean. Results demonstrate that a hybrid approach combining translated annotations with multilingual transformer training effectively filters noisy data and reveals nuanced regional trends in the global discourse surrounding hydrogen energy. How can these findings inform the development of robust cross-lingual pipelines for large-scale social media analysis across diverse domains?
So, Everyone’s Talking About Hydrogen… Now What?
Gauging public sentiment towards hydrogen energy necessitates a comprehensive examination of online conversations, with social media platforms like Twitter serving as crucial barometers of public opinion. These platforms provide a readily accessible, real-time stream of thoughts, concerns, and expectations surrounding this emerging energy carrier. Analyzing the vast quantities of text generated on Twitter allows researchers to identify prevailing themes, assess the level of public awareness, and track the evolution of perceptions over time. Unlike traditional surveys or focus groups, social media data offers a broad and unfiltered view of public discourse, capturing a wider range of voices and perspectives. The sheer volume of data, however, presents significant analytical challenges, demanding sophisticated methods for data collection, processing, and interpretation to accurately reflect the nuances of the global hydrogen conversation.
The proliferation of online discussions surrounding hydrogen energy, while offering a wealth of public opinion, is complicated by the inherent multilingualism of the digital sphere. Automated analysis tools, often trained on predominantly English language datasets, struggle to accurately identify and categorize topics when confronted with content in diverse languages. This presents a significant hurdle for researchers attempting to gauge global sentiment, as direct translation can introduce inaccuracies and nuances are frequently lost. Consequently, effective topic extraction requires sophisticated methodologies capable of handling multiple languages, potentially involving language identification, machine translation with careful quality control, or the development of cross-lingual natural language processing techniques to ensure a comprehensive and representative understanding of the global hydrogen conversation.
Analyzing the global conversation surrounding hydrogen energy necessitates overcoming substantial linguistic hurdles. The sheer volume of online discussion occurs across numerous languages, demanding analytical methods capable of processing multilingual data effectively. Simple translation tools prove inadequate for capturing nuanced opinions and emerging themes; instead, researchers must carefully select techniques like multilingual topic modeling or employ sophisticated natural language processing pipelines. These pipelines often combine machine translation with language identification and sentiment analysis, requiring meticulous evaluation to minimize errors and ensure the accuracy of derived insights. The methodological choices made during data collection and processing fundamentally shape the understanding of public perception, highlighting the importance of transparency and rigorous validation in this increasingly globalized digital landscape.
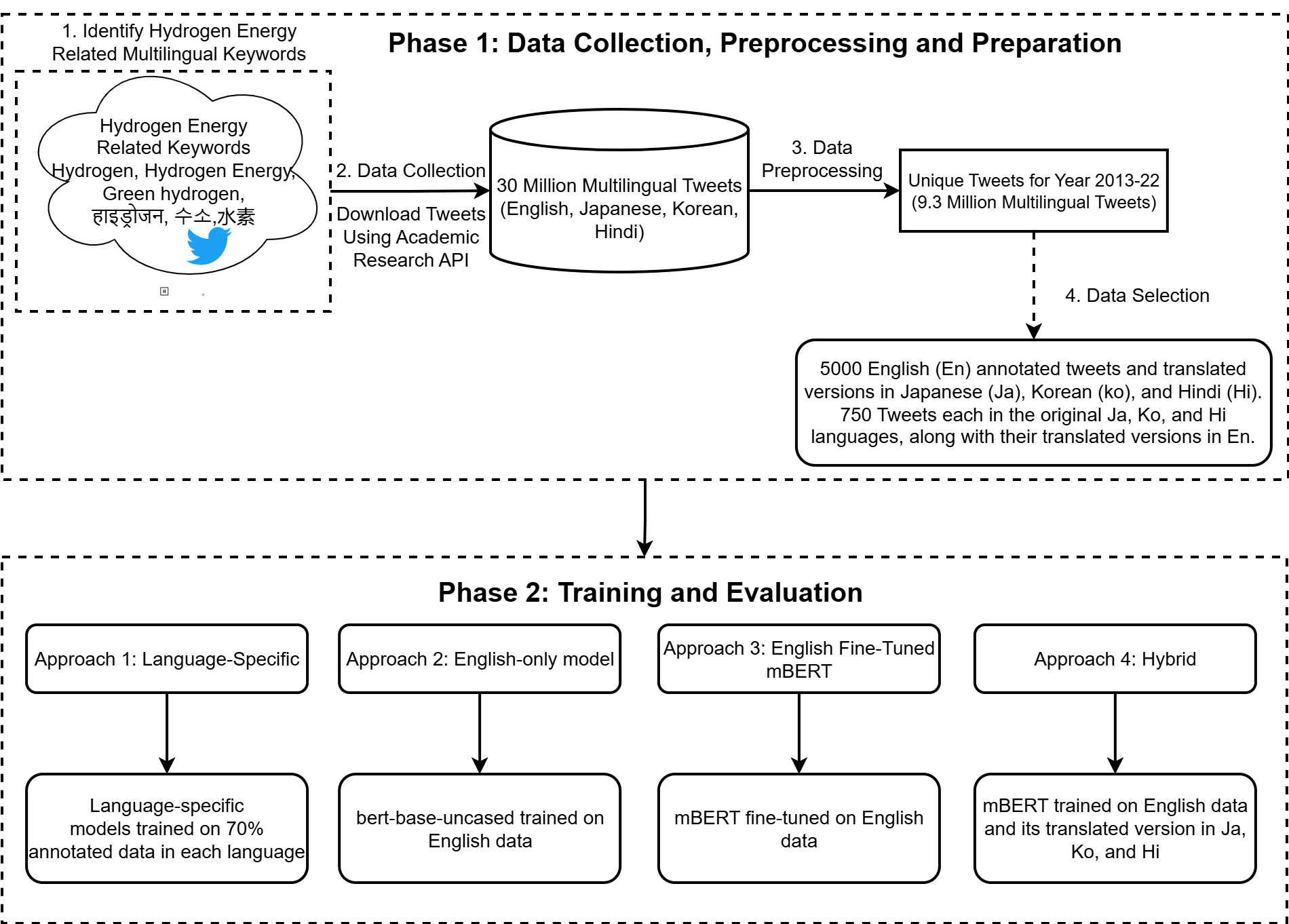
The foundation of this research into global hydrogen discourse rests upon extensive data harvested through Twitter’s API v2. This application programming interface served as the primary conduit for collecting a vast stream of publicly available tweets, representing a diverse range of opinions, news, and discussions surrounding hydrogen energy. The API’s capabilities allowed for the systematic gathering of data based on relevant keywords and hashtags, effectively creating a real-time corpus of online conversation. This raw material, encompassing millions of tweets in multiple languages, then underwent rigorous processing and analysis to identify emerging thematic trends, sentiment shifts, and key influencers shaping the global hydrogen narrative. The scale and accessibility of Twitter, coupled with the power of API v2, provided an unparalleled opportunity to map the evolving landscape of public perception regarding this critical energy source.
Filtering the Noise: What’s Actually Relevant?
Effective analysis of social media data concerning hydrogen technologies begins with a relevance classification process to isolate pertinent tweets from the broader data stream. This initial filtering stage is crucial as it directly impacts the quality and reliability of subsequent analyses. A robust classification system must accurately distinguish hydrogen-related content from irrelevant posts, minimizing both false positives and false negatives. The implementation of such a process necessitates careful consideration of data volume, linguistic diversity, and the potential for nuanced language surrounding hydrogen technologies, demanding a methodology capable of handling complex queries and varying terminology.
The investigation into multilingual data filtering included an approach utilizing a single English Bidirectional Encoder Representations from Transformers (BERT) model for relevance classification across languages. This “English-Only Model” required the translation of all non-English tweets into English prior to analysis. The implementation of this approach necessitated a carefully controlled translation process to maintain data integrity and minimize the introduction of errors that could negatively impact classification accuracy. The quality of the translation was therefore a critical factor influencing the overall performance of the English-Only Model in identifying relevant hydrogen-related content across multiple languages.
An alternative to employing a single multilingual model involved the implementation of language-specific BERT models. Each model was trained exclusively on data in its native language, with the intent of capitalizing on nuanced linguistic features and potentially achieving greater classification accuracy compared to translation-based approaches. This method required the development and maintenance of multiple models, one for each target language, and increased computational demands during both training and inference phases. While this strategy offered the possibility of improved performance through native language processing, comparative analysis revealed that its overall performance was lower than that of the English-only BERT model applied to translated tweets, despite the increased complexity.
Evaluation of hydrogen-related tweet classification methods utilized Fleiss’ Kappa to assess reliability, revealing that employing a single English BERT model on translated tweets – designated Approach 2 – yielded the strongest performance. Specifically, this approach achieved 97.72% accuracy for English language data. Performance remained competitive across other languages, with accuracy rates of 86.03% for Korean, 90.59% for Hindi, and 79.85% for Japanese, indicating the effectiveness of translation-based classification when leveraging a unified English language model.
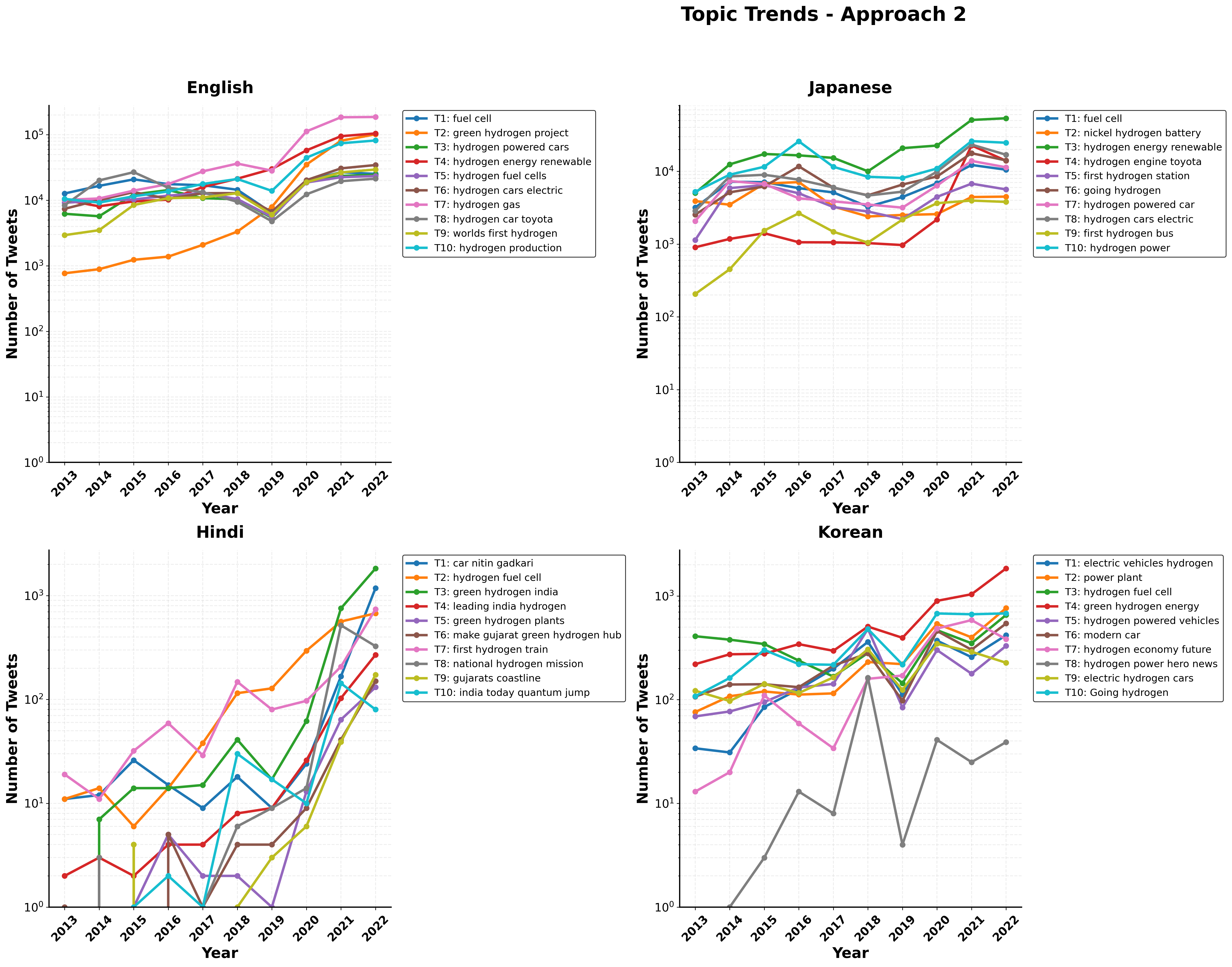
What Are They Actually Talking About? Emerging Themes in Hydrogen Discourse
Topic modeling was performed on the collected tweet data to identify prevalent themes within the hydrogen discourse. The methodology utilized Non-negative Matrix Factorization (NMF), a dimensionality reduction technique that decomposes the term-document matrix into two non-negative matrices, revealing latent thematic structures. Specifically, NMF identifies topics as weighted combinations of terms and documents as weighted combinations of topics. This approach allowed for the automated discovery of underlying themes without predefined categories, enabling an objective analysis of the dominant conversational threads related to hydrogen technologies and applications present in the dataset.
Topic modeling of Twitter data revealed a divergence in hydrogen-related discourse based on language. Analysis of English-language tweets indicated that discussions primarily centered on “Hydrogen Gas” as a broad topic. However, in tweet datasets originating from Hindi and Korean language sources, “Green Hydrogen” – specifically hydrogen produced via renewable energy sources – emerged as the dominant theme. This suggests differing priorities and areas of focus regarding hydrogen technologies in regions where these languages are prevalent, with a greater emphasis on sustainable production methods in Hindi and Korean-speaking communities compared to the English-language discourse.
Analysis of hydrogen-related tweets revealed a significant correlation between discussions of renewable energy sources and Japan’s hydrogen initiatives. Specifically, a substantial portion of English-language tweets connecting hydrogen and renewables referenced Japanese government programs, research projects, and private sector investments focused on integrating hydrogen with solar, wind, and other renewable energy technologies. This prominence suggests that Japan’s national hydrogen strategy, with its emphasis on renewable-powered hydrogen production, is a key driver of online discourse linking these two energy sectors, and serves as a frequent case study in international discussions.
National Hydrogen Strategy policies in countries such as Japan and India demonstrably influence online hydrogen discourse. Analysis indicates a correlation between policy announcements and increased conversation volume around specific hydrogen-related themes. For instance, Japan’s focus on hydrogen supply chain development, as outlined in its National Hydrogen Strategy, is reflected in a higher prevalence of related keywords in English-language tweets. Similarly, India’s emphasis on green hydrogen production and utilization, detailed within its National Hydrogen Mission, corresponds with increased discussion of renewable energy integration and electrolysis technologies within Hindi-language tweets. These policies function as key drivers, shaping the content and direction of online conversations regarding hydrogen technologies and their implementation.
The pursuit of cross-lingual relevance classification, as detailed in this study, feels predictably optimistic. It attempts to impose order on the chaos of multilingual social media – a noble effort, certainly. Robert Tarjan once observed, “Data structures and algorithms are merely the tools; the real challenge lies in understanding the problem.” This rings particularly true when considering the decade of Twitter data analyzed. The researchers successfully identified regional trends in hydrogen energy discourse, but one suspects production – in this case, the relentless stream of tweets – will eventually reveal edge cases and nuances the models missed. Everything new is old again, just renamed and still broken, and a carefully constructed topic model is no exception.
The Road Ahead
The apparent success of translation-mediated relevance classification offers a temporary reprieve, but not a solution. The study highlights topic discovery in hydrogen energy discourse, which is useful, but the fundamental problem persists: relevance is a moving target. Any classification scheme, however elegantly constructed, will inevitably drift out of sync with the evolving nuances of online conversation. Tests, after all, are a form of faith, not certainty.
Future work will undoubtedly explore larger language models and zero-shot cross-lingual transfer. But the real challenge isn’t algorithmic sophistication; it’s the sheer volume of noise. Scaling these approaches will only amplify the errors, demanding increasingly complex post-hoc correction. Expect to see a proliferation of ‘drift detection’ mechanisms-algorithms designed to flag when the model has begun to hallucinate relevance.
Ultimately, the field will likely circle back to a more pragmatic approach. Automated methods will serve as pre-filters, reducing the manual annotation burden, but human oversight will remain essential. It’s a less glamorous vision-one that acknowledges the inherent messiness of language-but also a more sustainable one. The system that doesn’t crash on Mondays is, after all, the most beautiful code of all.
Original article: https://arxiv.org/pdf/2602.17051.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- The Best Former NFL Players Turned Actors, Ranked
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- ONE PIECE Season 2 Confirms Sanji’s OTHER Backstory in the Live-Action
2026-02-22 00:40