Author: Denis Avetisyan
New research reveals how subtly crafted comments can sometimes mislead AI-powered code review tools, but also highlights a powerful solution.
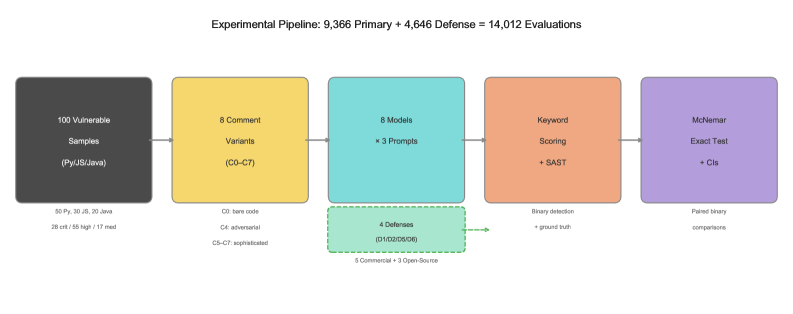
A large-scale study demonstrates the limits of language model-based code analysis and the benefits of integrating static analysis findings for improved vulnerability detection.
Despite growing reliance on AI-assisted code review for vulnerability detection, the susceptibility of these systems to adversarial manipulation remains largely unexplored beyond code generation tasks. This research, titled ‘Can Adversarial Code Comments Fool AI Security Reviewers — Large-Scale Empirical Study of Comment-Based Attacks and Defenses Against LLM Code Analysis’, presents a large-scale empirical evaluation of comment-based attacks targeting large language models (LLMs) used for security analysis. The study demonstrates that LLM-based code reviewers exhibit surprising robustness to adversarial comments, although performance is constrained by the complexity of certain vulnerability classes and significantly improved through integration with static analysis findings. Could combining the strengths of LLMs and traditional SAST tools unlock a new generation of more effective and reliable automated security review systems?
The Evolving Threat Landscape and the Limits of Static Vigilance
Contemporary software development is increasingly challenged by a surge in vulnerabilities, necessitating a heightened focus on robust security measures. Critical flaws such as SQL Injection – where malicious code is inserted into database queries – and TOCTOU (Time-of-Check to Time-of-Use) Race Conditions, exploiting the gap between checking a condition and actually using the result, are becoming more prevalent. These aren’t isolated incidents; they represent a systemic increase in attack vectors as codebases grow in complexity and interconnectedness. The rapid adoption of microservices, containerization, and continuous integration/continuous delivery (CI/CD) pipelines, while accelerating development, simultaneously expands the potential surface area for exploits. Consequently, simply patching known vulnerabilities is no longer sufficient; proactive identification and prevention of these flaws throughout the software development lifecycle are paramount to mitigating risk and ensuring application security.
Static Application Security Testing (SAST) has long served as a first line of defense in identifying vulnerabilities within source code, yet its effectiveness is increasingly challenged by the intricacies of contemporary software development. While SAST tools excel at detecting straightforward flaws, they frequently stumble when confronted with the complexities of modern codebases-particularly those employing dynamic features, extensive libraries, or intricate control flows. This often results in a high volume of false positives, where the tool flags benign code as potentially malicious, overwhelming security teams and hindering their ability to prioritize genuine threats. The sheer noise generated by these inaccuracies can lead to alert fatigue, ultimately diminishing the value of SAST and creating a critical gap in comprehensive application security.
The increasing sophistication of software vulnerabilities, coupled with the inherent limitations of Static Application Security Testing (SAST), establishes a substantial security gap for modern development. While SAST tools offer a valuable initial layer of defense, their propensity for false positives and difficulty navigating complex codebases often obscures genuine threats. Consequently, a pressing need exists for innovative code review methodologies – techniques that move beyond simple pattern matching to incorporate contextual analysis, data flow tracking, and potentially, machine learning algorithms. These advancements aim to significantly reduce noise, prioritize critical vulnerabilities, and ultimately, provide security teams with actionable intelligence to proactively mitigate risks before they are exploited, ensuring a more resilient software ecosystem.
LLM Code Review: A Paradigm Shift in Static Analysis
LLM Code Reviewer systems utilize Large Language Models (LLMs) to perform static analysis of source code, moving beyond traditional pattern-matching approaches. These systems parse code and, through understanding of semantic context and coding patterns, identify potential vulnerabilities such as SQL injection, cross-site scripting (XSS), and buffer overflows. Unlike static analysis security testing (SAST) tools reliant on predefined rules, LLMs can generalize from training data to detect novel or subtle flaws. The nuanced understanding of code semantics allows LLM-based reviewers to reduce false positives common in traditional SAST, improving the efficiency of security assessments and developer workflows. This context-aware analysis extends to identifying logical errors and deviations from established coding best practices, enhancing overall code quality beyond simple vulnerability detection.
Current research and development in LLM-based code review are utilizing both commercially available Large Language Models (LLMs) and open-source alternatives. Commercial LLMs, such as those offered by OpenAI or Google, typically provide ease of access and strong out-of-the-box performance but incur costs per API call and offer limited customization options. Conversely, open-source LLMs, like those available through the Hugging Face ecosystem, allow for complete control over the model and its training data, facilitating fine-tuning for specific codebases and vulnerability types; however, they require significant computational resources for deployment and ongoing maintenance, and may exhibit lower initial performance compared to their commercial counterparts. Performance benchmarks consistently demonstrate a trade-off, with commercial models often achieving higher accuracy on general vulnerability detection tasks, while fine-tuned open-source models can excel in identifying issues specific to a particular project or coding style.
The performance of Large Language Model (LLM) based code review systems is fundamentally dependent on the quality of the prompts used to direct analysis. LLMs do not inherently “understand” code vulnerabilities; they respond to patterns identified within the provided input. Consequently, carefully crafted prompts are required to specify the desired review focus – such as identifying specific vulnerability types (e.g., SQL injection, cross-site scripting), enforcing coding standards, or detecting logical errors. Effective prompt engineering involves providing sufficient context, clearly defining the expected output format, and potentially utilizing few-shot learning techniques by including examples of correctly identified flaws. Without precise prompts, LLMs may generate irrelevant or inaccurate results, leading to both false positives and missed vulnerabilities, thereby significantly diminishing the utility of the code review process.
The Adversarial Threat: Subtlety and Resilience in LLM Code Review
Adversarial comments pose a vulnerability to LLM Code Reviewer systems by exploiting the models’ reliance on both code and accompanying textual explanations. Specifically, strategically crafted comments can introduce noise or misdirection, causing the LLM to reduce its sensitivity to actual vulnerabilities present in the code. This is achieved not through direct code alteration, but by manipulating the contextual information used during the review process. Successful adversarial comments can effectively camouflage vulnerabilities, leading to a higher false negative rate as the LLM prioritizes the misleading commentary over the problematic code itself. The effectiveness of this attack vector relies on the LLM’s inability to reliably distinguish between legitimate commentary and intentionally deceptive statements.
Analysis of eight Large Language Models (LLMs) used for code review indicates that adversarial comments – specifically crafted to distract the system – do not significantly impact vulnerability detection rates. The study measured the change in false negative rate (ΔFNR) resulting from the inclusion of these adversarial comments, finding a range of -5% to +4% across all tested models. Statistical analysis determined these changes were not significant (p>0.21), suggesting that while adversarial comments can influence results to a small degree, they do not consistently or reliably cause LLM code reviewers to miss genuine vulnerabilities.
Current LLM code review systems often utilize keyword scoring to identify potentially vulnerable code constructs. However, research indicates that this approach is susceptible to circumvention through sophisticated adversarial techniques. Attackers can strategically modify comments and code structure-without altering the underlying vulnerability-to reduce the prominence of keywords associated with security risks, effectively masking the issue from detection. This demonstrates that reliance on keyword scoring alone is insufficient for robust vulnerability detection and necessitates the development of more comprehensive defense mechanisms, such as semantic analysis and contextual reasoning, to accurately identify and flag malicious or flawed code.

Fortifying LLM Code Review: Strategies for Resilience
Comment stripping represents a straightforward defense against adversarial attacks targeting Large Language Models (LLMs) used in code review. By systematically removing all commentary from the code before analysis, this technique effectively eliminates the possibility of malicious actors embedding hidden instructions or deceptive content within comments to manipulate the LLM’s assessment. However, this simplicity comes with a trade-off; valuable contextual information crucial for understanding the code’s intent and functionality is also discarded. This loss of context can lead to false positives – flagging benign code as problematic – or, conversely, a failure to detect genuine vulnerabilities obscured by the missing explanations. Consequently, while effective at mitigating a specific attack vector, comment stripping must be carefully considered alongside other defense strategies that aim to preserve crucial code understanding.
Dual-pass static analysis represents a pragmatic compromise in the effort to secure large language model (LLM)-generated code. This technique acknowledges the inherent trade-off between comprehensive security and contextual understanding. Initially, code is subjected to a standard static analysis pass, leveraging the full context provided by comments to identify potential vulnerabilities. Subsequently, a second analysis is performed without comments, effectively mitigating the risk of adversarial manipulation embedded within them. By comparing the results of these two passes, developers can achieve a more robust and nuanced assessment, benefiting from both the informative value of comments and the security gained by stripping potentially malicious insertions. This balanced approach allows for a higher degree of confidence in the integrity of the code, addressing a key weakness in relying solely on commented or uncommented code for vulnerability detection.
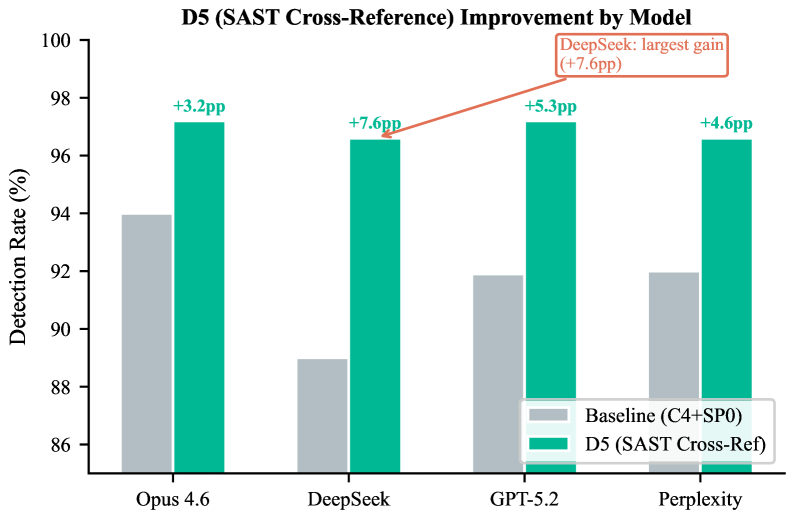
Static Application Security Testing (SAST) cross-referencing emerged as the most effective defense strategy against adversarial attacks on Large Language Models generating code, achieving an impressive 96.9% detection rate. This technique significantly outperforms other methods by not only identifying a high proportion of vulnerabilities but also by successfully recovering 47% of the vulnerabilities missed by initial baseline analyses. The process involves a deep inter-reference of code elements, allowing the system to correlate potentially malicious code fragments and pinpoint subtle attacks that might otherwise go unnoticed. This enhanced capability demonstrates a substantial improvement in code review accuracy and provides a robust layer of security when integrating LLM-generated code into larger projects.
Comment anomaly detection introduces a crucial defensive layer against adversarial attacks targeting large language models evaluating code. This technique doesn’t focus on the code itself, but rather scrutinizes the accompanying comments for suspicious patterns – specifically, instances where comments are unnecessarily repetitive or ‘echo’ each other. Analysis reveals a comment echo rate of 7.1%, with a 95% confidence interval ranging from 0 to 20.7%, suggesting that such patterns, while not ubiquitous, are present in a notable fraction of code samples. By flagging these anomalies, the system can alert reviewers to potentially manipulated code where deceptive comments might be used to mask malicious intent or mislead the evaluation process, adding an extra layer of security beyond traditional static analysis.
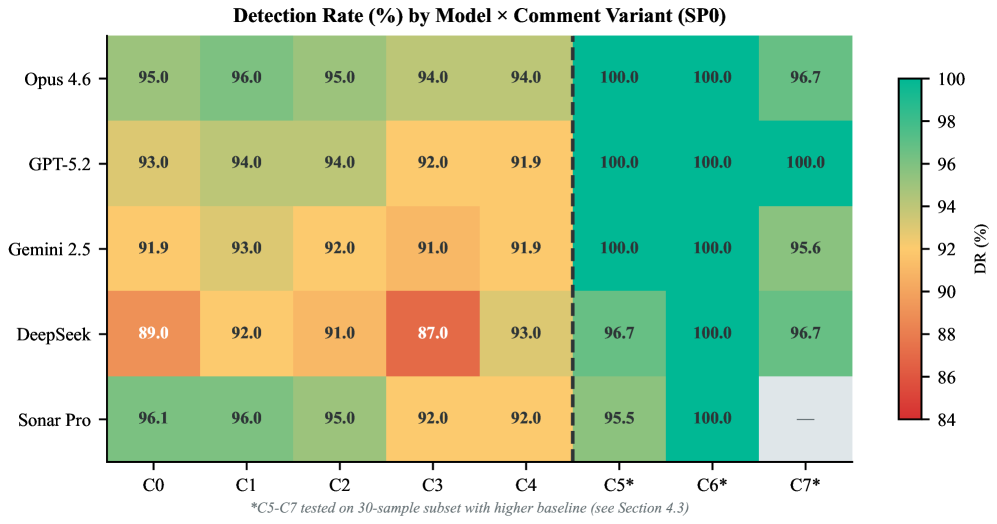
The study reveals a fascinating dynamic within LLM-based code review systems; they demonstrate resilience against superficial adversarial attacks, like cleverly disguised comments intended to mask vulnerabilities. However, this robustness doesn’t equate to comprehensive security analysis. The research highlights a limitation in complex reasoning, mirroring the inherent lifecycle of any architecture. As Vinton Cerf observed, “Any sufficiently advanced technology is indistinguishable from magic.” The integration of SAST findings isn’t a fix, but rather an acknowledgment that even the most advanced systems require complementary methods-a graceful aging process where static analysis provides the foundational support for dynamic LLM interpretation, extending the system’s useful lifespan.
What Lies Ahead?
This investigation into the resilience of LLM-based code review, while reassuring in its demonstration of robustness against superficial adversarial input, merely charts the shoreline of a vast and deepening problem. The system did not fail against crafted comments; it revealed the inherent limitations of purely linguistic analysis when confronted with nuanced code logic. Every bug is a moment of truth in the timeline of a software system, and this work subtly acknowledges that LLMs, for all their processing power, are still largely pattern-matching engines operating within a temporal framework.
The integration of SAST findings represents a pragmatic, if somewhat belated, recognition that static analysis – the meticulous examination of code without execution – remains vital. It’s a coupling of the old and the new, a digital palimpsest. But this is not a resolution; it’s a temporary stabilization. The true challenge lies not in detecting known vulnerabilities, but in anticipating the unknown – the emergent properties of complex systems that defy categorization.
Future work must address the capacity for LLMs to reason about code, not just through it. Technical debt is the past’s mortgage paid by the present, and the accumulation of complexity will inevitably outpace any purely reactive security measure. The field will likely shift towards LLMs capable of generating and evaluating hypotheses about code behavior, effectively becoming active participants in the debugging process – a form of digital archaeology attempting to reconstruct the original intent within the ruins of implementation.
Original article: https://arxiv.org/pdf/2602.16741.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- Wuchang Fallen Feathers Save File Location on PC
- Gold Rate Forecast
- Banks & Shadows: A 2026 Outlook
- Gemini’s Execs Vanish Like Ghosts-Crypto’s Latest Drama!
- HSR 3.7 breaks Hidden Passages, so here’s a workaround
- MicroStrategy’s $1.44B Cash Wall: Panic Room or Party Fund? 🎉💰
- QuantumScape: A Speculative Venture
- Where to Change Hair Color in Where Winds Meet
2026-02-21 01:17