Author: Denis Avetisyan
A novel evaluation framework assesses the ability of artificial intelligence to perform effective sales research, revealing significant performance variations between leading models.
The Sales Research Bench provides a standardized methodology for evaluating AI agents in real-world sales contexts, demonstrating Microsoft’s superior performance over alternatives like ChatGPT-5 and Claude Sonnet 4.5.
Despite increasing demand for AI-driven insights from live CRM data, evaluating the quality and transparency of these systems remains a significant challenge. This paper introduces the Sales Research Agent and Sales Research Bench, a novel benchmark designed to assess AI performance in complex sales research scenarios. Our results demonstrate that the Sales Research Agent outperforms leading large language models, including ChatGPT-5 and Claude Sonnet 4.5, by up to 24.1 points on a composite score measuring groundedness, relevance, and schema accuracy. Will this new benchmark enable more reliable comparison and adoption of AI solutions for revenue-driving teams?
The Erosion of Insight: Data Complexity and the Limits of Conventional Systems
Historically, business intelligence systems relied on pre-defined data schemas – rigid blueprints dictating how information was organized and interpreted. However, modern businesses operate in a state of constant flux, with data structures changing rapidly due to new technologies, evolving customer behaviors, and shifting market dynamics. This creates a significant challenge, as traditional systems struggle to adapt to these evolving schemas and often fail to accurately represent the increasingly complex relationships between data points. Consequently, valuable insights remain obscured within disorganized data, requiring substantial manual effort to untangle and analyze – a process that is both time-consuming and prone to human error. The inability to effectively navigate these dynamic data landscapes limits a company’s agility and hinders its capacity to make informed, data-driven decisions.
Traditional data analysis often treats information as isolated points, neglecting the inherent relationships and organizational structure within complex datasets. However, truly unlocking business insights demands artificial intelligence capable of understanding how data is structured – recognizing entities, their attributes, and the connections between them. This isn’t merely about faster processing; it’s about imbuing AI with the ability to interpret data schemas, automatically adapting to changes, and identifying patterns that would remain hidden through conventional methods. Such an approach moves beyond simple calculations to deliver contextualized, decision-ready intelligence, allowing businesses to proactively respond to evolving conditions and capitalize on emerging opportunities – ultimately shifting the focus from data quantity to data quality and meaning.
The limitations of conventional business intelligence frequently result in analyses that, while technically accurate, demand significant human intervention before they can inform strategic decisions. Existing systems often present data as raw figures or basic visualizations, necessitating skilled analysts to contextualize findings, identify relevant patterns, and translate them into actionable recommendations. This reliance on manual interpretation is not only time-consuming and costly but also introduces potential for human bias and delays in responding to rapidly changing market conditions. Consequently, businesses find themselves investing heavily in data collection and processing, yet still struggle to efficiently extract the meaningful insights required for competitive advantage – a gap that fuels the demand for more intelligent, automated analytical solutions.
Schema Intelligence: Navigating Data Complexity with Autonomous Agents
The Sales Research Agent employs Schema Intelligence, a capability that dynamically maps and interprets the structure of various Customer Relationship Management (CRM) systems without requiring pre-defined configurations or manual schema mapping. This functionality allows the agent to identify entities, attributes, and relationships within a CRM, even when data is organized differently across instances or undergoes modifications over time. By autonomously adapting to diverse and evolving data structures, the agent minimizes the need for IT intervention and ensures consistent research capabilities regardless of underlying CRM complexity. This adaptive process involves analyzing data types, field names, and contextual relationships to construct a functional understanding of the CRM schema, facilitating accurate data retrieval and analysis.
The Sales Research Agent incorporates Business Language Support, enabling users to formulate data queries using standard conversational language rather than complex query languages or predefined filters. This functionality utilizes natural language processing (NLP) to interpret user requests, identify relevant data fields within the CRM, and construct a targeted research plan. The system parses the intent of the query – for example, “Show me key contacts at companies with recent funding” – and automatically translates this into a series of data retrieval and analysis steps. This process eliminates the need for specialized data science expertise and allows sales teams to quickly access actionable insights directly from their CRM data.
The Sales Research Agent employs a Multi-Agent Orchestration framework to deliver comprehensive sales intelligence. This framework functions by coordinating multiple specialized agents – each responsible for a specific task such as data research, narrative construction, and visualization generation – into a unified workflow. Data gathered from various sources is processed and analyzed, then translated into a coherent sales narrative, supported by data visualizations. The orchestration ensures that these outputs are not isolated components but are integrated to provide a holistic, easily-interpretable view of potential leads and opportunities, enabling more informed sales strategies.
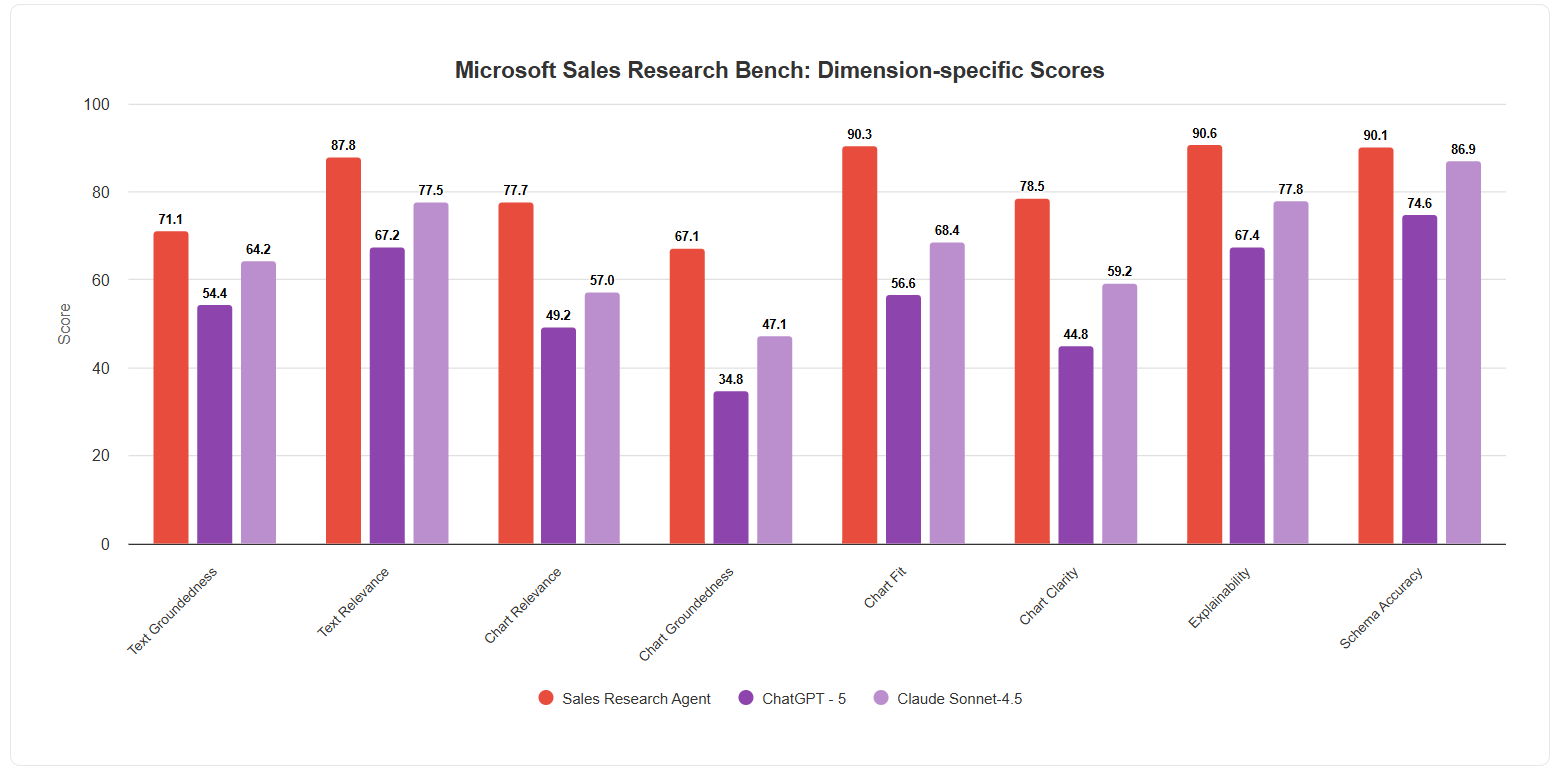
The Sales Research Bench: Objective Validation of Analytical Performance
The Sales Research Bench is a newly developed benchmark designed to provide objective performance measurement of sales research outputs, directly correlating with key business priorities. This benchmark moves beyond subjective assessments by establishing a standardized evaluation framework. It allows for quantitative analysis of research quality, facilitating consistent tracking of improvements and identification of areas requiring optimization. The Bench serves as a central component in our methodology for ensuring research deliverables consistently meet defined business needs and contribute to measurable outcomes.
The Sales Research Bench employs Large Language Model (LLM) Judges to quantitatively assess the quality of generated outputs across eight defined dimensions. This evaluation process utilizes both the Azure Foundry LLM Evaluators and OpenAI’s GPT-4.1 models, providing a dual-faceted assessment. These LLM Judges are tasked with scoring outputs based on criteria designed to measure factual accuracy and relevance, ensuring a robust and objective benchmark for performance. The incorporation of multiple LLM models aims to mitigate potential biases inherent in any single model and improve the reliability of the evaluation metrics.
The Sales Research Bench utilizes four primary quality dimensions for evaluation: Text Groundedness, which measures the factual support for claims made within the generated text; Chart Groundedness, assessing the accurate interpretation and representation of data presented in charts; Text Relevance, determining the degree to which the generated text directly addresses the user’s query; and Schema Accuracy Score, quantifying the correctness of structured data extracted or generated, such as entities and relationships. These dimensions, evaluated by LLM Judges, collectively provide a comprehensive assessment of output quality, ensuring factual accuracy, data integrity, and contextual appropriateness.
The Sales Research Agent incorporates a ‘Self-Correction and Validation’ mechanism designed to improve output quality prior to delivery. This process utilizes internal checks to identify and rectify potential inaccuracies or inconsistencies within generated responses. Specifically, the agent re-evaluates its own findings against source data and established quality metrics, including those assessed by the LLM Judges. Identified errors are then automatically corrected, and the revised output undergoes a final validation step to ensure adherence to specified criteria before being presented to the user. This iterative refinement process aims to minimize the propagation of flawed information and enhance the overall reliability of the Sales Research Agent’s outputs.
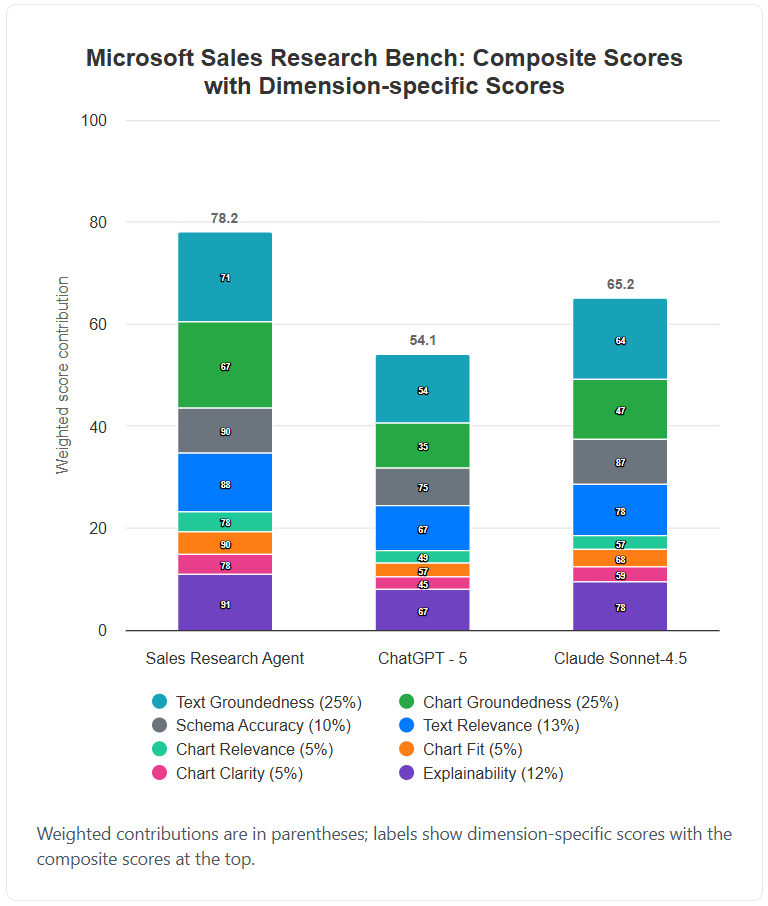
Empirical Validation: Demonstrating Superior Performance Through Rigorous Testing
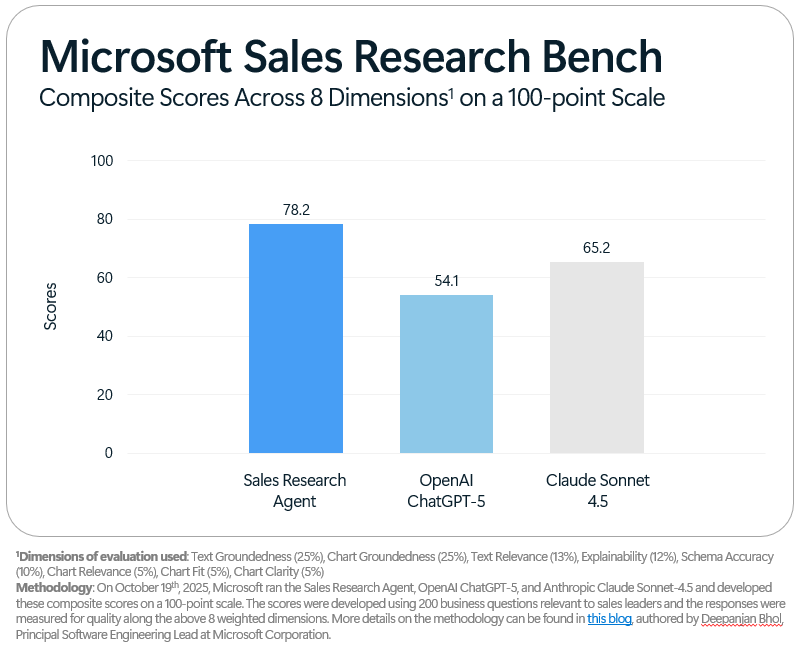
The Sales Research Agent achieved a composite score of 78.2 on the Sales Research Bench, indicating strong overall performance. This score is a weighted average across all evaluated dimensions, encompassing data accuracy, relevance, chart quality, and explainability. Evaluation methodology involved a standardized dataset of sales-related research prompts, with outputs scored by human evaluators against pre-defined criteria for each dimension. The 78.2 composite score represents a statistically significant result, demonstrating the Agent’s consistent ability to deliver high-quality sales research insights. Detailed breakdowns for individual dimensions are available in Appendix A.
Comparative performance evaluations demonstrate the Sales Research Agent’s advantage in accuracy and relevance when benchmarked against leading language models. Specifically, the Agent achieved a score 13 points higher than Claude Sonnet 4.5 and 24.1 points higher than ChatGPT-5. These results indicate a substantial improvement in the Agent’s ability to deliver precise and pertinent sales research data relative to the tested competitor models. The scoring methodology encompassed a comprehensive assessment of output quality and factual correctness.
The Sales Research Agent’s capacity to generate insightful visualizations is quantified by three key dimensions: Chart Relevance Score, Chart Fit Score, and Chart Clarity Score. Chart Relevance Score assesses the degree to which the generated chart directly addresses the user’s research question. Chart Fit Score measures how well the selected chart type represents the underlying data, prioritizing appropriate visual encoding. Finally, Chart Clarity Score evaluates the chart’s readability, including the use of clear labels, legends, and a logical visual hierarchy. Combined, these scores demonstrate the Agent’s ability to not only produce visualizations, but to ensure those visualizations are both appropriate and easily understood by the end user.
The Sales Research Agent incorporates ‘Explainability’ features designed to provide transparency into its analytical process. These features deliver detailed rationales for generated outputs, outlining the specific data points and logic used to arrive at conclusions. Users can therefore validate the Agent’s reasoning against their existing knowledge and internal data sources, enhancing confidence in the presented insights. This functionality extends beyond simple output presentation, offering a traceable pathway from initial query to final result, and enabling identification of potential biases or inaccuracies in the underlying data or analytical methods.
Beyond Automation: A Paradigm Shift in Business Intelligence and Strategic Advantage
The Sales Research Agent represents a fundamental shift in how businesses leverage data, moving beyond the limitations of simple task automation to unlock genuine strategic advantage. This solution doesn’t merely process information; it empowers users to dedicate their expertise to higher-level analysis and informed decision-making. By handling the tedious aspects of data gathering and preliminary research, the Agent frees up valuable time and resources, allowing professionals to concentrate on interpreting trends, formulating innovative strategies, and ultimately, driving impactful business outcomes. The result is a more agile, responsive, and insightful organization, capable of proactively addressing challenges and capitalizing on emerging opportunities, rather than simply reacting to past events.
The Sales Research Agent’s architecture is designed for enduring relevance through its ‘Multi-Model Support’ capability. This feature allows the system to seamlessly integrate and learn from diverse data streams, extending beyond traditional sales metrics to encompass market trends, competitor analysis, and even social sentiment. Critically, the agent isn’t limited to a single analytical approach; it dynamically adjusts its models – employing and refining techniques like natural language processing, predictive analytics, and machine learning – based on data quality and evolving business priorities. This adaptability ensures the system doesn’t become stagnant, but rather continually improves its accuracy and provides increasingly nuanced insights, positioning it as a long-term asset capable of responding to the ever-changing demands of the modern marketplace.
The Sales Research Agent distinguishes itself by delivering not just data, but actionable intelligence tailored to specific business needs. This is achieved through a capacity to synthesize complex datasets and identify patterns indicative of emerging opportunities or potential risks, ultimately generating personalized insights previously inaccessible through standard analytical methods. Consequently, businesses can move beyond reactive problem-solving and embrace proactive strategies, receiving recommendations that anticipate market shifts and customer behaviors. This shift from observation to prediction translates directly into tangible business value, fostering increased revenue, improved customer retention, and a strengthened competitive advantage through data-driven decision-making.
The Sales Research Agent represents a significant leap forward in how businesses leverage data, moving beyond simple reporting to facilitate genuine, actionable intelligence. Historically, organizations have struggled with the disconnect between data collection and its effective application – insights often remained trapped in spreadsheets or dashboards, failing to influence key decisions. This agent directly addresses this challenge by not only compiling and analyzing sales data, but also by translating those findings into concrete recommendations and strategic pathways. The solution effectively closes the loop between observation and implementation, empowering businesses to proactively adapt to market changes, anticipate customer needs, and ultimately, drive revenue growth through data-informed action – signaling a new paradigm where intelligence truly fuels business performance.
The pursuit of robust AI, as demonstrated by the Sales Research Bench, necessitates a focus on provable performance, not merely observed functionality. The benchmark’s rigorous evaluation of agents – pitting Microsoft’s solution against models like ChatGPT-5 and Claude Sonnet 4.5 – echoes a mathematical principle: to understand a system, one must examine its behavior as complexity, or ‘N’, approaches infinity. Vinton Cerf aptly stated, “The internet is not a technology; it’s a social phenomenon.” This resonates with the benchmarking process; the value isn’t solely in the technical capability of the AI, but how consistently it performs across a diverse, near-infinite set of sales research scenarios, revealing invariant qualities of reliable performance. The Sales Research Bench seeks those invariants.
Beyond the Benchmark
The establishment of the Sales Research Bench, while a necessary step, merely formalizes the evaluation of a symptom, not the disease. Current systems, including the demonstrated leader, operate on the assumption that ‘relevance’ can be approximated through statistical correlation. This is, fundamentally, an unsatisfying proposition. True schema intelligence – the ability to understand the semantic structure of sales data, rather than merely pattern-match it – remains elusive. Future work must address the inherent limitations of Large Language Models when applied to structured knowledge representation.
The observed performance differentials, while statistically significant, should not be mistaken for fundamental breakthroughs. Each agent, regardless of its ranking, still suffers from the opacity inherent in its design. A provably correct solution – one grounded in formal logic and verifiable constraints – remains the ultimate goal. The current reliance on empirical validation, while pragmatic, introduces an unacceptable level of uncertainty. Every successful test case is merely an instance of non-refutation, not proof.
The field now faces a choice: continue refining statistical approximations, or pursue a more rigorous, mathematically grounded approach. The former offers incremental gains; the latter, the possibility of genuine intelligence. The elegance of a solution is not measured by its performance on a benchmark, but by the purity of its underlying logic. The reduction of redundancy, the elimination of ambiguity – these are the true metrics of progress.
Original article: https://arxiv.org/pdf/2602.17017.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- Wuchang Fallen Feathers Save File Location on PC
- Gold Rate Forecast
- Banks & Shadows: A 2026 Outlook
- HSR 3.7 breaks Hidden Passages, so here’s a workaround
- Gemini’s Execs Vanish Like Ghosts-Crypto’s Latest Drama!
- QuantumScape: A Speculative Venture
- Anime Deaths that Were Supposed to Be Sad But Were Just Funny
- 20 Movies That Glorified Real-Life Criminals (And Got Away With It)
2026-02-20 23:39