Author: Denis Avetisyan
Researchers have created a challenging benchmark to assess how well artificial intelligence can reason with numbers in real-world banking tasks.
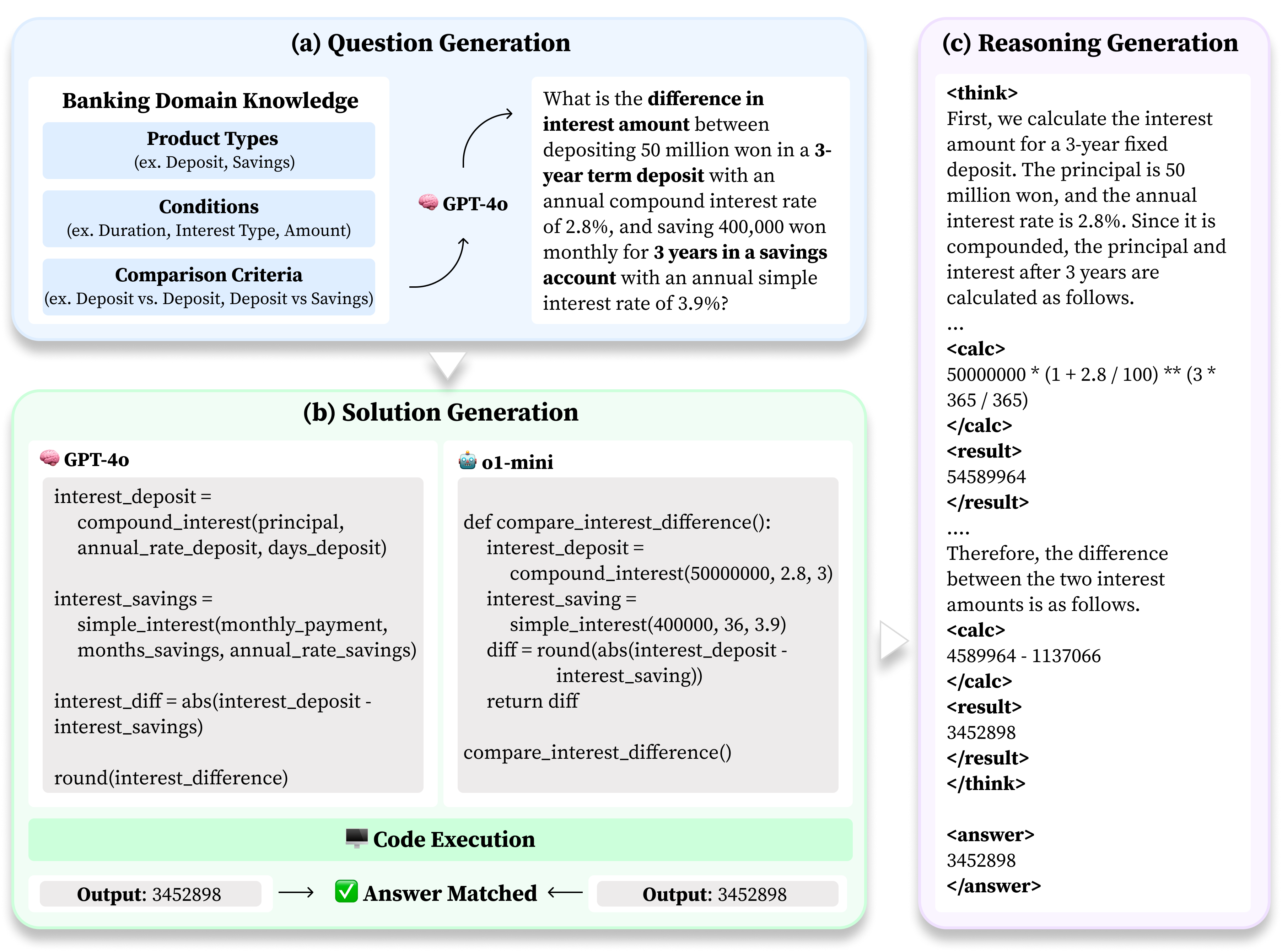
BankMathBench, a new dataset focused on numerical reasoning in banking scenarios, demonstrates the potential for significant performance improvements in large language models through fine-tuning and tool augmentation.
Despite the increasing adoption of large language models in financial applications, core banking computations-including interest calculations and product comparisons-remain a significant challenge. To address this limitation, we introduce BankMathBench: A Benchmark for Numerical Reasoning in Banking Scenarios, a domain-specific dataset designed to rigorously evaluate and enhance LLMs’ ability to perform multi-step numerical reasoning within realistic banking contexts. Our results demonstrate substantial performance gains-up to 75.1% improvement in accuracy-through fine-tuning and tool augmentation, highlighting the dataset’s effectiveness in bolstering domain-specific reasoning capabilities. Will this benchmark pave the way for more reliable and accurate LLM-powered financial services in the future?
The Rigorous Demands of Numerical Finance
While Large Language Models (LLMs) have rapidly advanced natural language processing, exhibiting proficiency in tasks like text generation and translation, their application to finance reveals significant limitations in numerical reasoning. These models, trained primarily on textual data, often struggle with the precision demanded by financial calculations, such as present value assessments or complex derivative pricing. The core issue isn’t a lack of general intelligence, but rather a deficit in consistently and accurately manipulating numbers and understanding quantitative relationships – a skill crucial for tasks like risk analysis, portfolio optimization, and fraud detection. Consequently, even seemingly simple financial problems can yield inaccurate results, highlighting the need for specialized architectures or training methodologies that bolster LLMs’ quantitative capabilities and ensure reliability in high-stakes financial contexts.
Conventional Large Language Model architectures, while proficient in natural language processing, frequently exhibit limitations when applied to the rigorous demands of financial calculations and decision-making. These models, typically optimized for pattern recognition in text, struggle with the precise arithmetic and logical consistency essential for banking applications. The inherent probabilistic nature of LLM predictions, coupled with a reliance on statistical correlations rather than deterministic rules, can introduce inaccuracies in even seemingly simple financial operations – for instance, calculating interest rates, assessing loan risks, or forecasting market trends. This imprecision stems from the models’ core design, which prioritizes fluency and coherence over numerical exactness, posing a significant challenge to their reliable deployment in high-stakes financial contexts where even minor errors can have substantial consequences.
The reliable deployment of Large Language Models in finance is hampered by a critical need for robust evaluation benchmarks. Existing assessments often rely on simplified datasets that fail to capture the multi-layered intricacies of real-world financial scenarios – things like time-series analysis, risk modeling, and the interplay of macroeconomic factors. This discrepancy creates a significant gap between reported performance and actual reliability when these models are applied to tasks demanding precision, such as portfolio optimization or fraud detection. Consequently, a new generation of benchmarks is required, incorporating diverse financial instruments, realistic market conditions, and complex reasoning challenges to accurately gauge a model’s ability to navigate the nuances of the financial world and provide trustworthy outputs.

BankMathBench: A Dataset for Quantitative Precision
BankMathBench is a benchmark dataset specifically constructed to assess the numerical reasoning abilities of Large Language Models (LLMs) within the context of common banking operations. The dataset focuses on practical financial calculations encountered with products such as deposits, savings accounts, and loans. Problems are formulated to require LLMs to perform arithmetic operations, percentage calculations, and understand financial terms to arrive at correct solutions. This domain-specific approach allows for a focused evaluation of LLM performance in scenarios demanding accuracy and comprehension of financial principles, distinct from general mathematical reasoning benchmarks.
The BankMathBench dataset is generated using an automated pipeline leveraging the GPT-4o language model. This pipeline constructs financial problems covering banking products, and for each problem, generates not only the question and the final answer, but also a detailed, step-by-step reasoning process explaining how the solution is derived. The pipeline is designed to produce a high volume of diverse problems, ensuring dataset scalability and enabling continuous evaluation of large language model performance on numerical reasoning tasks within a financial context. The generated data includes variations in problem structure, numerical values, and complexity to comprehensively assess LLM capabilities.
The automated data generation pipeline utilizes GPT-4o to produce financial reasoning problems at scale, mitigating the limitations of manual dataset construction. This programmatic approach ensures consistency in problem format, solution methodology, and reasoning complexity across the BankMathBench dataset. The ability to rapidly generate new problems and solutions facilitates continuous evaluation of Large Language Models (LLMs) as they evolve, and allows for targeted dataset expansion to address specific performance weaknesses or to test LLMs against novel financial scenarios. This scalability is crucial for tracking LLM progress and identifying areas requiring further development in financial reasoning capabilities.
Enhancing LLM Performance: Fine-tuning and Tool Augmentation
Applying fine-tuning techniques, such as QLoRA, to pre-trained Large Language Models (LLMs) demonstrably improves performance on the BankMathBench dataset, specifically in understanding and solving financial reasoning problems. Accuracy improvements of up to 72.7% have been observed on intermediate and advanced subsets of the benchmark following fine-tuning. This suggests that while pre-trained LLMs possess a foundational knowledge base, adapting them to the specific nuances of financial calculations and problem-solving through targeted training data yields substantial gains in practical application and reliability.
Tool Augmentation improves the numerical reasoning capabilities of Large Language Models (LLMs) by enabling them to utilize external computational resources. Rather than relying solely on the LLM’s internal parameters to perform calculations, this technique allows the model to interface with specialized tools, such as calculators or mathematical solvers. This delegation of numerical tasks reduces the potential for errors inherent in LLM-based calculations and increases the reliability of results. By offloading computation, Tool Augmentation minimizes the need for the LLM to store and recall complex mathematical facts, freeing up parameters for improved language understanding and reasoning in other areas.
Exact-Match Accuracy serves as a quantifiable metric for evaluating the efficacy of Large Language Model (LLM) optimization techniques. Application of this metric to the Qwen3-8B model demonstrated a performance increase following fine-tuning; the model achieved 54.4% accuracy on the advanced Korean dataset post-optimization. Importantly, fine-tuning also improved the consistency of results, reducing the standard deviation from σ = 15.8 prior to fine-tuning to σ = 9.5 afterward, indicating a more reliable and predictable performance level.

Expanding Linguistic Horizons and Ensuring Robustness
The BankMathBench dataset’s inclusion of Korean language examples represents a significant step towards broadening the practical application of Large Language Models (LLMs) within global finance. Historically, LLM development and evaluation have been heavily biased towards English, limiting their utility in non-English speaking markets and creating barriers to financial inclusivity. By incorporating Korean, a language with distinct grammatical structures and financial terminology, the dataset challenges LLMs to demonstrate true cross-lingual reasoning capabilities. This expansion moves beyond simple translation, requiring models to understand and accurately process financial information expressed in a different linguistic context, ultimately paving the way for more universally accessible and robust financial tools.
The expansion of BankMathBench to include Korean, alongside English, represents a significant step toward democratizing access to advanced financial tools. Historically, the evaluation of large language models (LLMs) has been heavily biased toward English, inadvertently excluding a substantial portion of the global population and limiting the practical applicability of these technologies in non-English speaking regions. By incorporating a diverse linguistic dataset, the benchmark ensures a more equitable assessment of LLM capabilities, moving beyond the constraints of a single language. This inclusive approach not only broadens the potential user base but also drives innovation by exposing limitations and fostering the development of models that genuinely function across different cultural and linguistic contexts, ultimately making sophisticated financial analysis more accessible to a wider audience.
The incorporation of multilingual data significantly bolsters the reliability and adaptability of large language models when applied to practical financial tasks. Evaluations utilizing the BankMathBench dataset demonstrate that fine-tuning on both Korean and English language examples yields remarkably low error rates – a median relative error ratio of just 1.28% for Korean and 1.89% for English. Notably, these errors are virtually eliminated when coupled with tool augmentation strategies. The Qwen3-8B model, after fine-tuning, experienced a substantial performance boost, achieving a 42.0% increase in accuracy for Korean and a 44.6% increase for English on the basic-level dataset, highlighting the power of diverse linguistic training to enhance real-world applicability and broaden the reach of these powerful AI tools.
The creation of BankMathBench underscores a fundamental principle: the necessity of rigorous validation. The dataset doesn’t simply assess whether a large language model appears to function within banking contexts; it demands demonstrable, reproducible accuracy in numerical reasoning. This echoes G.H. Hardy’s sentiment: “Mathematics may be considered with precision, but should not be considered in isolation.” BankMathBench provides that precision, offering a focused evaluation that moves beyond superficial performance and towards genuinely reliable results. The benchmark’s emphasis on tool augmentation, specifically, highlights a pragmatic approach to achieving this reliability, acknowledging that complex calculations require more than just statistical inference.
The Road Ahead
The introduction of BankMathBench, while a necessary step, merely highlights the profound chasm between statistical language modeling and genuine numerical competence. Demonstrating improved performance on a curated benchmark, even one rooted in practical banking scenarios, does not equate to a model understanding the underlying mathematical principles. The gains achieved through fine-tuning and tool augmentation are, at best, pragmatic approximations – clever scaffolding built atop a fundamentally probabilistic core. A truly robust system demands a proof of correctness, not simply a high score on a test suite.
Future efforts should prioritize formal verification techniques. The current paradigm – training models to mimic reasoning – is inherently fragile. Consider the implications of edge cases, adversarial examples, or even slight variations in problem formulation. A system based on provable algorithms, even if initially less flexible, offers a far superior long-term solution. The focus must shift from achieving superficial accuracy to establishing mathematical guarantees.
Furthermore, the limitations of current tool augmentation strategies are readily apparent. Simply providing a language model with access to a calculator does not imbue it with the capacity for logical deduction. The integration of symbolic reasoning systems – those capable of manipulating mathematical expressions with precision – remains a critical, and largely unexplored, avenue for progress. Until such integration occurs, these models will remain sophisticated pattern-matching engines, not true numerical reasoners.
Original article: https://arxiv.org/pdf/2602.17072.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- Wuchang Fallen Feathers Save File Location on PC
- Gold Rate Forecast
- Banks & Shadows: A 2026 Outlook
- Gemini’s Execs Vanish Like Ghosts-Crypto’s Latest Drama!
- HSR 3.7 breaks Hidden Passages, so here’s a workaround
- QuantumScape: A Speculative Venture
- The 10 Most Beautiful Women in the World for 2026, According to the Golden Ratio
- Is Taylor Swift Getting Married to Travis Kelce in Rhode Island on June 13, 2026? Here’s What We Know
2026-02-20 15:10