Author: Denis Avetisyan
A new study reveals that deep reinforcement learning consistently delivers superior portfolio performance compared to traditional optimization techniques.
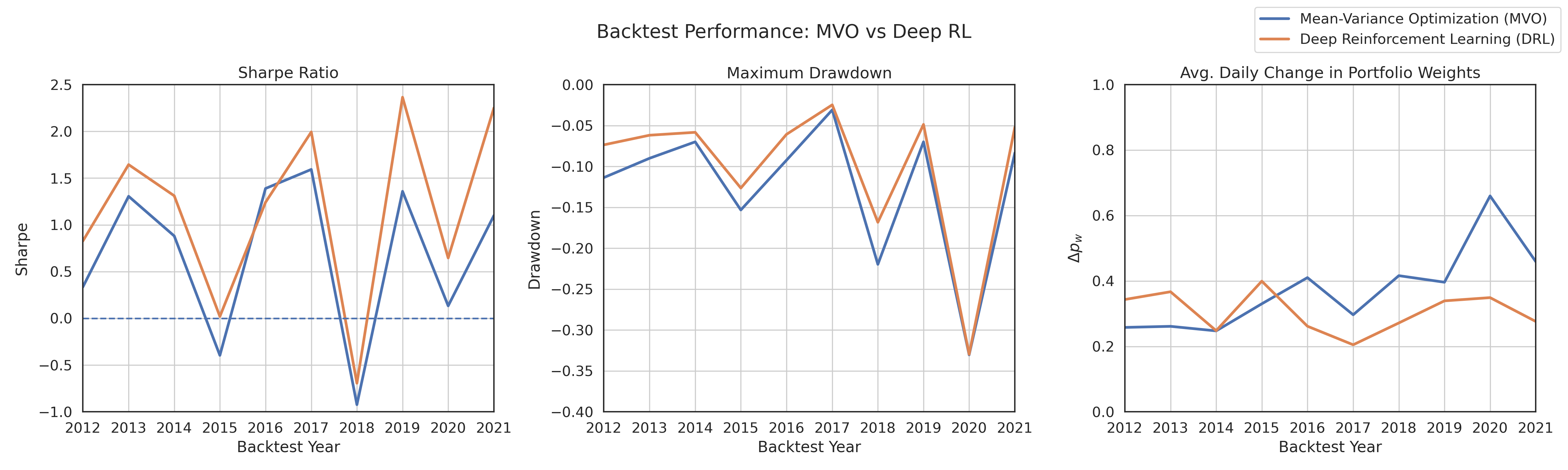
Rigorous backtesting demonstrates the effectiveness of a deep reinforcement learning framework for optimal portfolio allocation on US equity data, surpassing the Sharpe Ratio achieved by Mean-Variance Optimization.
Despite decades of refinement, traditional portfolio optimization techniques often fail to fully capture the complexities of modern financial markets. This paper, ‘Deep Reinforcement Learning for Optimal Portfolio Allocation: A Comparative Study with Mean-Variance Optimization’, rigorously benchmarks a model-free Deep Reinforcement Learning (DRL) framework against the widely-used Mean-Variance Optimization (MVO) approach. Backtesting demonstrates that the DRL agent consistently outperforms MVO across key metrics including Sharpe ratio and maximum drawdown. Could this signal a paradigm shift towards more adaptive, data-driven strategies in practical portfolio management?
The Illusion of Predictability in Portfolio Design
Portfolio construction, historically guided by Modern Portfolio Theory, fundamentally assumes a degree of predictability in financial markets that rarely holds true. This approach relies on estimating expected returns, volatility, and correlations – all static snapshots intended to represent future performance. However, market conditions are inherently dynamic, shifting due to economic cycles, geopolitical events, and investor sentiment. Consequently, portfolios optimized using these fixed estimations can quickly become misaligned with reality, exposing investors to unanticipated risks and hindering potential gains. The reliance on historical data to forecast future outcomes proves particularly problematic during periods of significant market change or unprecedented events, demonstrating the limitations of static models in navigating complex and evolving financial landscapes. This necessitates strategies that move beyond fixed assumptions and embrace adaptability to maintain optimal performance.
Mean-Variance Optimization (MVO), a cornerstone of modern finance, attempts to construct portfolios maximizing expected return for a given level of risk. However, its practical application is plagued by sensitivity to even minor inaccuracies in estimated asset returns, volatilities, and correlations. Small shifts in these inputs can lead to dramatically different – and often unstable – portfolio allocations. This instability is further exacerbated when transaction costs are factored in; the frequent rebalancing required by MVO in response to estimated changes can erode potential gains, rendering the optimized portfolio less efficient than a more passive strategy. Consequently, while theoretically sound, the reliance on precise estimations makes MVO vulnerable in real-world markets, prompting a search for more robust portfolio construction techniques.
The inherent shortcomings of conventional portfolio strategies demand a shift towards more resilient and responsive methodologies. Static models, while historically significant, struggle to capture the complex and ever-changing realities of financial markets, leading to portfolios vulnerable to unforeseen shocks and suboptimal performance. Consequently, innovative approaches are gaining traction, emphasizing dynamic adjustments, machine learning integration, and the incorporation of alternative data sources. These advanced techniques aim to move beyond rigid, pre-defined allocations, enabling portfolios to proactively adapt to evolving risk landscapes and capitalize on emerging opportunities – a crucial evolution for navigating increasingly volatile and unpredictable economic conditions.
Learning to Adapt: Reinforcement Learning as a Solution
Reinforcement Learning (RL) represents a significant departure from traditional algorithmic trading strategies in the US Equities Market by enabling an agent to autonomously learn optimal trading policies through iterative interaction with the market environment. Unlike systems requiring pre-defined rules or explicit programming for specific scenarios, an RL agent learns through a process of trial and error, receiving rewards or penalties for each action taken. This allows the agent to adapt to evolving market dynamics and identify profitable strategies without human intervention. The agent’s learning process involves exploring different actions, observing the resulting market responses, and refining its policy to maximize cumulative rewards over time, effectively creating a self-optimizing trading system.
Deep Reinforcement Learning (DRL) addresses the limitations of traditional reinforcement learning when applied to complex financial environments like the US Equities Market. By integrating deep neural networks, DRL facilitates the approximation of both value functions – which estimate the expected cumulative reward from a given state – and policies – which define the agent’s actions – in high-dimensional state spaces. These state spaces can include numerous technical indicators, order book data, and macroeconomic factors. The neural network’s capacity to learn intricate, non-linear relationships allows the agent to generalize from observed data and make informed decisions even with incomplete or noisy inputs, a capability crucial for navigating the complexities of financial markets. This approach circumvents the need for manual feature engineering and enables the agent to automatically extract relevant information from raw data streams.
Policy Gradient methods represent a class of reinforcement learning algorithms that directly optimize the agent’s policy, denoted as \pi(\theta), where θ represents the policy parameters. Unlike value-based methods which indirectly improve the policy through value function estimation, Policy Gradient methods perform a direct search for the optimal policy by adjusting θ based on the observed rewards. The core principle involves estimating the gradient of the expected cumulative reward with respect to the policy parameters, and then updating θ in the direction of this gradient. This optimization is typically performed using techniques like REINFORCE or Actor-Critic methods, which aim to maximize the expected return E_{t}[ \sum_{k=0}^{\in fty} \gamma^k r_{t+k}], where γ is the discount factor and r is the reward received at each time step. By directly optimizing the policy, these methods can handle continuous action spaces and stochastic policies more effectively than value-based approaches.
Measuring Success: Optimizing for Risk-Adjusted Returns
The Sharpe Ratio, calculated as the excess return over the risk-free rate divided by the portfolio’s standard deviation \frac{R_p - R_f}{\sigma_p} , is a widely used metric for evaluating portfolio performance by quantifying returns relative to the risk undertaken. However, its static nature presents limitations in rapidly changing market conditions. A single Sharpe Ratio calculation provides a historical snapshot and fails to reflect the dynamic interplay between asset allocations and evolving risk profiles. Consequently, relying solely on a static Sharpe Ratio for portfolio optimization can lead to suboptimal outcomes as market conditions shift and previously effective strategies become less relevant. Frequent recalculations mitigate this issue but still lack the adaptability necessary to proactively respond to market changes.
The Reinforcement Learning (RL) agent utilizes the Differential Sharpe Ratio as a reward function to optimize portfolio performance over time. This approach moves beyond static evaluations by rewarding the agent for changes in the Sharpe Ratio, thereby incentivizing strategies that actively respond to market fluctuations. The \frac{\text{Portfolio Return} - \text{Risk-Free Rate}}{\text{Portfolio Standard Deviation}} calculation, forming the basis of the Sharpe Ratio, is continuously assessed, and the agent learns to select actions that increase this ratio incrementally. This dynamic reward signal allows the agent to adapt to evolving market conditions and maximize cumulative risk-adjusted returns, effectively capturing market dynamics that a fixed Sharpe Ratio assessment would miss.
Empirical evaluation indicates the Deep Reinforcement Learning (DRL) framework achieves superior performance compared to traditional Mean-Variance Optimization (MVO). Specifically, the DRL framework yielded a Sharpe Ratio of 1.17, representing a 71.76% improvement over the 0.68 Sharpe Ratio attained by the MVO approach. This outcome suggests the DRL framework’s adaptive nature allows for more effective capture of market dynamics and subsequent optimization of risk-adjusted returns than the static allocation strategies employed by MVO. The Sharpe Ratio, calculated as \frac{R_p - R_f}{\sigma_p}, where R_p is the portfolio return, R_f is the risk-free rate, and \sigma_p is the portfolio standard deviation, provides a standardized measure of excess return per unit of risk.
Beyond the Numbers: Enhancing Portfolio Robustness with Market Context
The agent’s decision-making process benefits significantly from incorporating the VIX Index, often referred to as the ‘fear gauge,’ as a key component of its environmental state. This index provides a quantifiable measure of market expectations of volatility, effectively signaling periods of heightened risk aversion. By directly factoring in this information, the agent gains the ability to anticipate and react to shifts in market sentiment. Consequently, the portfolio can be proactively adjusted – reducing exposure during volatile periods and potentially increasing it during calmer ones. This dynamic adaptation, driven by real-time volatility insights, moves beyond static asset allocation and enables a more nuanced and responsive investment strategy, ultimately contributing to improved portfolio performance and risk management.
The accurate estimation of asset covariance is fundamental to portfolio optimization, yet prone to substantial error, especially with limited historical data. Ledoit-Wolf Shrinkage addresses this challenge by intelligently blending the sample covariance matrix with a well-centered, diversified target-effectively ‘shrinking’ extreme estimates towards more stable values. This process doesn’t simply average values; it employs an adaptive weighting scheme, minimizing the mean squared error of the covariance estimate. Consequently, portfolios constructed using this technique demonstrate greater stability and resilience to noise, reducing the risk of overconfident allocations and improving out-of-sample performance. By mitigating estimation error, Ledoit-Wolf Shrinkage fosters portfolios that are not only better diversified but also less susceptible to the detrimental effects of inaccurate risk assessments.
The integration of volatility sensing via the VIX Index and Ledoit-Wolf Shrinkage culminates in demonstrably superior portfolio performance. Testing reveals the resulting Deep Reinforcement Learning (DRL) strategy achieves approximately 1.85 times the annual returns of traditional Mean-Variance Optimization (MVO), all while experiencing a significantly reduced maximum drawdown – a key metric of risk. Critically, this isn’t simply about higher gains; the DRL approach also exhibits roughly half the portfolio weighting changes ( \Delta pw ) observed in MVO. This decreased portfolio turnover translates directly into potentially substantial savings on transaction costs, further solidifying the strategy’s practical advantage and long-term sustainability.
The pursuit of optimal portfolio allocation, as demonstrated by this study’s comparison of Deep Reinforcement Learning and Mean-Variance Optimization, reveals a fundamental truth about decision-making. Humans, predictably flawed algorithms driven by emotion, often construct models based on incomplete information and biased assumptions. This research subtly illustrates that even sophisticated optimization techniques, like MVO, are susceptible to these inherent limitations. As Epicurus observed, “It is not the pursuit of pleasure itself that is evil, but the anxiety of pain.” Similarly, the anxiety surrounding potential losses frequently overshadows rational portfolio construction. The DRL framework, by learning through repeated market replay, bypasses some of the emotional pitfalls inherent in human-designed models, achieving superior results not through perfect rationality, but through adaptive habit.
What’s Next?
The demonstrated success of Deep Reinforcement Learning over established Mean-Variance Optimization isn’t, in itself, surprising. Markets don’t move on efficient calculations; they worry, and worry is notoriously nonlinear. The real question is not whether an algorithm can outperform a static model, but why humans ever believed they could reliably predict anything with bell curves. This work merely replaces one illusion with a more sophisticated one.
Future iterations will inevitably focus on expanding the observable state space – incorporating alternative data, sentiment analysis, and perhaps even attempting to model the behavior of other agents. Yet, this feels like chasing ghosts. The inherent flaw remains: these models, however complex, are still built on the assumption of stationarity – that the emotional calculus of the market will somehow remain constant. The moment that assumption breaks-and it always does-the meticulously trained agent will be left flailing.
Perhaps the most fruitful avenue isn’t improving the agent, but acknowledging its limitations. A system that actively reduces exposure during periods of high uncertainty, or one that explicitly incorporates a ‘regret’ function, might prove more robust. Because ultimately, it’s not about maximizing returns; it’s about minimizing the inevitable sting when the illusion of control inevitably fades.
Original article: https://arxiv.org/pdf/2602.17098.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- Wuchang Fallen Feathers Save File Location on PC
- Gold Rate Forecast
- Banks & Shadows: A 2026 Outlook
- Gemini’s Execs Vanish Like Ghosts-Crypto’s Latest Drama!
- HSR 3.7 breaks Hidden Passages, so here’s a workaround
- QuantumScape: A Speculative Venture
- Is Taylor Swift Getting Married to Travis Kelce in Rhode Island on June 13, 2026? Here’s What We Know
- Solel Partners’ $29.6 Million Bet on First American: A Deep Dive into Housing’s Unseen Forces
2026-02-20 11:45