Author: Denis Avetisyan
Researchers are leveraging the power of large language models to automatically create novel learning algorithms, moving beyond parameter tuning to genuine code evolution.
This work demonstrates that Large Language Models can discover effective multi-agent learning algorithms for imperfect-information games by evolving code, utilizing techniques like counterfactual regret minimization and policy space response oracles.
The iterative refinement of multi-agent reinforcement learning (MARL) algorithms in imperfect-information games has historically relied heavily on human intuition. In ‘Discovering Multiagent Learning Algorithms with Large Language Models’, we demonstrate a novel approach using an evolutionary coding agent powered by large language models to automate the discovery of new algorithms. This framework successfully evolved both a novel regret minimization algorithm, Volatility-Adaptive Discounted (VAD-)CFR, and a population-based training variant, Smoothed Hybrid Optimistic Regret (SHOR-)PSRO, outperforming state-of-the-art baselines. Could this paradigm shift towards automated algorithm discovery unlock a new era of performance and efficiency in game-theoretic learning and beyond?
The Illusion of Hand-Tuned Perfection
Despite their theoretical foundations, achieving practical success with game-theoretic algorithms like Discounted Counterfactual Regret Minimization (DCFR) and its successor, Payoff Counterfactual Regret Minimization Plus (PCFR+), necessitates substantial manual tuning by expert practitioners. These algorithms aren’t simply ‘plug-and-play’ solutions; instead, parameters governing exploration rates, abstraction levels, and even the order in which game states are traversed require careful, iterative adjustment. This process often involves extensive experimentation and relies heavily on the intuition of skilled game theorists to identify configurations that yield strong performance in specific scenarios. The sensitivity to these hand-crafted parameters means that even minor adjustments can drastically alter the algorithm’s convergence speed and ultimately, its ability to approximate an optimal strategy, highlighting a critical limitation in their widespread application.
The dependence on specialized expertise in developing game-theoretic algorithms presents a considerable obstacle to advancement, particularly within increasingly intricate domains. These algorithms, while theoretically powerful, often demand extensive manual adjustments – a process reliant on the intuition and skill of experienced practitioners. This creates a bottleneck, as progress becomes limited by the availability of these experts and the time-intensive nature of their work. Consequently, adapting these algorithms to new or evolving scenarios proves challenging; the need for repeated, manual refinement significantly hinders their scalability and responsiveness, ultimately slowing innovation in fields like artificial intelligence, economics, and security where robust strategic reasoning is crucial.
The development of game-theoretic algorithms has historically relied on a painstaking, iterative process of manual refinement. Each adjustment to a strategy, abstraction, or parameter requires expert evaluation and re-implementation, creating a significant bottleneck as game complexity increases. This hand-crafted approach proves increasingly unsustainable when confronted with modern, high-dimensional scenarios – such as large-scale multi-player games or realistic economic models – where the search space for optimal algorithms expands exponentially. The time and expertise needed to tune these algorithms manually quickly outpaces the rate of potential improvement, effectively limiting the ability to address truly complex strategic challenges and hindering the pursuit of generally applicable, autonomous game-solving systems.
Let the Machines Evolve
AlphaEvolve is a distributed system leveraging a population of algorithms that evolve over time to optimize performance in game-theoretic scenarios. This distributed architecture allows for parallel evaluation of algorithm variants, significantly accelerating the evolutionary process. Each algorithm within the population is represented as executable code and is subject to modification and selection based on its performance against other algorithms in a competitive environment. The system manages the lifecycle of these algorithms – including variation, evaluation, and selection – across a network of computational resources, enabling the automation of algorithm design without manual intervention. This approach contrasts with traditional algorithm design, which typically relies on human expertise and iterative refinement.
AlphaEvolve employs Large Language Models, specifically Gemini, to implement a process called semantic evolution for algorithm design. Unlike traditional evolutionary algorithms that rely on random code mutations, AlphaEvolve leverages the LLM’s understanding of code semantics to intelligently modify algorithms. This approach allows the system to alter code based on its intended meaning and functionality, rather than through trial-and-error changes. The LLM analyzes the existing code, identifies areas for improvement based on the desired game-theoretic properties, and then generates modified code that reflects these improvements, resulting in a more directed and efficient evolutionary process.
AlphaEvolve aims to significantly reduce the time and resources required to develop high-performing algorithms for complex games. Traditional algorithmic development relies heavily on human expertise and iterative testing, a process that can be both slow and computationally expensive. By automating this process through semantic evolution driven by Large Language Models, AlphaEvolve enables the rapid generation and evaluation of numerous algorithmic variations. Initial results demonstrate that algorithms designed with AlphaEvolve achieve state-of-the-art performance in game-theoretic domains, surpassing manually designed algorithms in specific benchmarks and indicating the potential for continued performance gains as the system evolves and is applied to a wider range of games.
Beyond Hand-Crafted: VAD-CFR and SHOR-PSRO
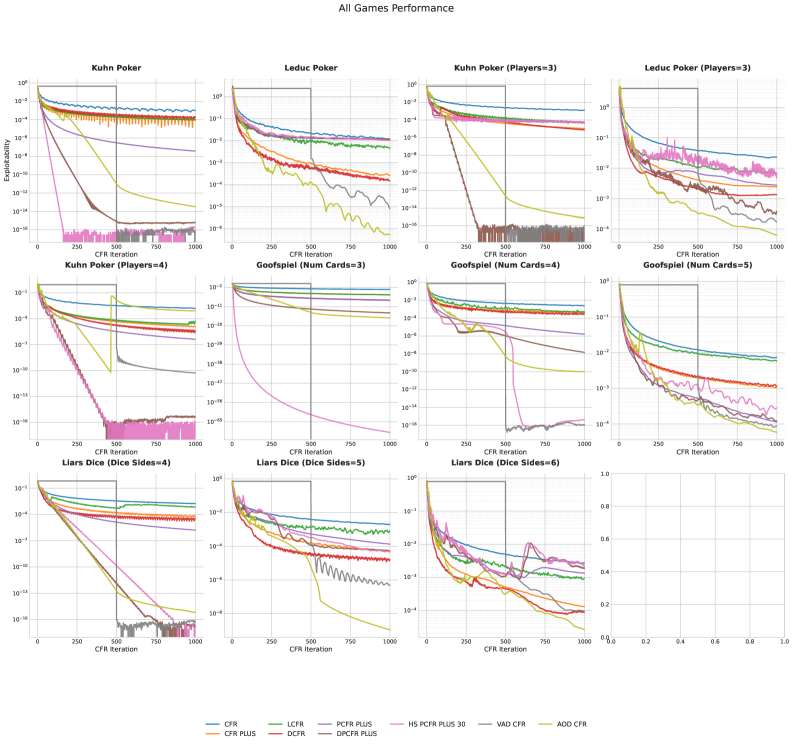
Volatility-Adaptive Discounting (VAD) is a key component of the VAD-CFR algorithm, an evolved variant of Counterfactual Regret Minimization (CFR). Traditional CFR implementations utilize a fixed discount factor to weigh the importance of future rewards; however, VAD-CFR dynamically adjusts this discounting parameter during the learning process. This adjustment is based on the observed volatility of the game state, increasing the discount factor in stable situations to promote long-term strategic thinking and decreasing it in volatile situations to prioritize immediate exploitation of advantageous positions. This dynamic adjustment allows VAD-CFR to adapt to varying game dynamics and potentially improve convergence and exploitability compared to standard CFR implementations.
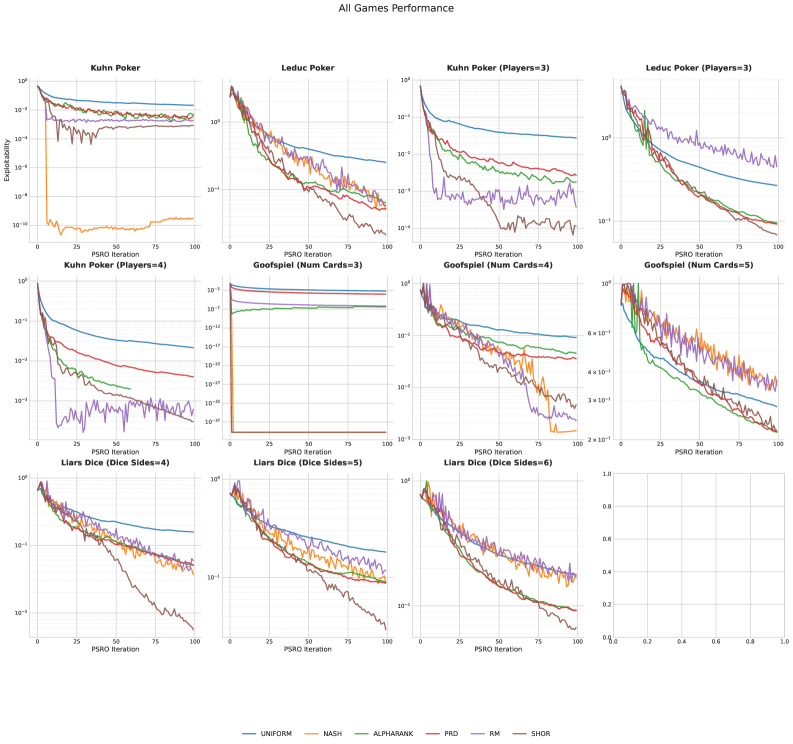
SHOR-PSRO builds upon the Policy-Space Response Oracles (PSRO) algorithm by incorporating a Hybrid Update Rule and an Annealing Schedule to enhance convergence speed and stability. The Hybrid Update Rule combines elements of both best-response and regret-matching updates, allowing the algorithm to more efficiently explore and exploit the policy space. Concurrently, the Annealing Schedule systematically reduces the step size of policy updates over time, facilitating finer adjustments and preventing oscillations as the algorithm approaches a Nash equilibrium. This combination aims to address limitations in standard PSRO implementations, particularly in complex game scenarios where maintaining stable convergence can be challenging.
Evaluations demonstrate that the AlphaEvolve framework yields algorithms capable of exceeding the performance of manually designed methods in complex game environments. Specifically, testing across multiple games indicates exploitability levels below 10-3 were consistently achieved. Comparative analysis against state-of-the-art (SOTA) baselines revealed AlphaEvolve outperformed these methods in 8 out of 11 tested games. Furthermore, the evolved algorithms, particularly those leveraging Policy-Space Response Oracles (PSRO), exhibited faster convergence rates during training compared to existing techniques.
The Inevitable Shift: From Craft to Evolution
The advent of automated algorithm design holds significant promise for advancing Multi-Agent Reinforcement Learning (MARL) systems. Traditional MARL often relies on hand-crafted algorithms, limiting adaptability in scenarios with shifting dynamics or unforeseen complexities. By automating the algorithmic creation process, researchers can generate agents capable of learning and evolving strategies tailored to specific, and even unpredictable, environmental conditions. This approach allows for the discovery of novel algorithmic solutions that might not be apparent to human designers, potentially leading to more robust, efficient, and cooperative multi-agent systems. Consequently, applications ranging from robotics and autonomous driving to resource management and economic modeling stand to benefit from agents capable of dynamically optimizing their behavior through automatically designed algorithms.
The innovative methodology underpinning AlphaEvolve transcends the traditional boundaries of game theory, establishing a versatile framework applicable to diverse problem-solving scenarios. While initially demonstrated through competitive games, the system’s core principles – automated algorithm generation and evaluation via evolutionary strategies – readily adapt to optimization challenges across fields like robotics, resource management, and financial modeling. This adaptability stems from its ability to define performance metrics specific to any given domain, allowing the evolutionary process to converge on algorithms tailored for that environment. Consequently, AlphaEvolve represents a significant step towards automating the often-laborious process of algorithm design, potentially accelerating innovation and enabling solutions to complex problems previously intractable due to the sheer difficulty of manual algorithm crafting.
The advent of AlphaEvolve signifies a fundamental shift in how algorithms are created, moving beyond the traditional paradigm of human-led design. Historically, algorithmic innovation has relied heavily on expert intuition and painstaking manual crafting, a process that is both time-consuming and potentially limited by human bias. AlphaEvolve, however, demonstrates the power of automating this process, allowing algorithms to be discovered through evolutionary search rather than deliberate construction. This automated discovery not only accelerates the pace of innovation but also opens up the possibility of uncovering algorithms that might never have been conceived by humans, potentially leading to breakthroughs in fields ranging from robotics and control systems to economic modeling and scientific discovery. The implications extend beyond mere efficiency; it suggests a future where algorithms are not simply tools designed by humans, but rather emergent entities optimized by the forces of evolution, marking a new era of algorithmic creation and adaptation.
The pursuit of automated algorithm discovery, as detailed in this work, feels less like innovation and more like accelerating the inevitable. This paper showcases Large Language Models evolving multi-agent learning algorithms – a clever trick, certainly, but one that merely shifts the complexity. It’s reminiscent of trading one form of technical debt for another. The system discovers novel strategies by evolving code, rather than parameter tuning, but someone, somewhere, will eventually have to debug that evolved code when production inevitably throws a curveball. As Marvin Minsky once observed, “The more we learn about intelligence, the more we realize how much of it is just clever hacking.” This feels apt; the system isn’t solving the fundamental challenges of imperfect-information games, it’s finding increasingly sophisticated ways to work around them, a process destined to become tomorrow’s maintenance burden.
What’s Next?
The automation of algorithm design, as demonstrated, merely shifts the complexity. The problem isn’t a lack of algorithmic options, but an excess of them, each with diminishing returns when faced with the inevitable chaos of deployment. This work successfully generates code, but code, as any seasoned engineer knows, is simply a delayed error message. The real challenge isn’t creating novelty, but creating maintainability-a quality conspicuously absent from most ‘revolutionary’ architectures.
Future efforts will likely focus on scaling this code-generating capability, aiming for ever-more-complex agent interactions. However, increasing complexity doesn’t address the fundamental issue: imperfect information. The core limitation remains the difficulty of modeling real-world opponents, whose rationality is often… questionable. One suspects that any algorithm, no matter how elegantly derived, will eventually encounter an adversary that exploits its assumptions. The field needs fewer elaborate strategies and more robust methods for handling irrationality.
Ultimately, this research is a reminder that innovation often involves reinventing existing crutches. The question isn’t whether Large Language Models can discover algorithms, but whether they can discover algorithms worth the operational cost. The tendency to chase algorithmic elegance will likely continue, despite the historical evidence suggesting that simpler, more pragmatic solutions often prevail. The pursuit of intelligence continues, but the problem isn’t a lack of intelligence – it’s a surplus of illusions.
Original article: https://arxiv.org/pdf/2602.16928.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- Wuchang Fallen Feathers Save File Location on PC
- Gold Rate Forecast
- Gemini’s Execs Vanish Like Ghosts-Crypto’s Latest Drama!
- Banks & Shadows: A 2026 Outlook
- HSR 3.7 breaks Hidden Passages, so here’s a workaround
- QuantumScape: A Speculative Venture
- Elden Ring’s Fire Giant Has Been Beaten At Level 1 With Only Bare Fists
- Here Are the Best TV Shows to Stream this Weekend on Hulu, Including ‘Fire Force’
2026-02-20 06:40