Author: Denis Avetisyan
New research shows how to leverage existing conversation data to create AI assistants that handle routine tasks and seamlessly escalate complex issues.
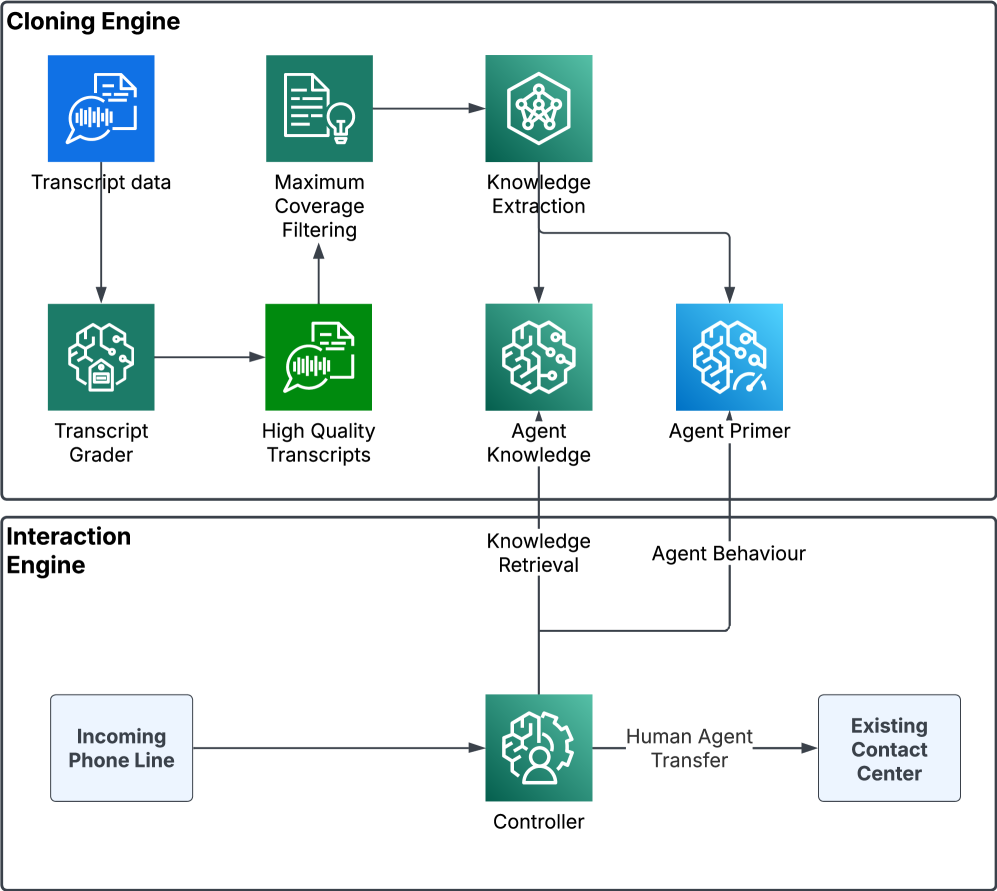
This review details a system for knowledge extraction from call transcripts, RAG integration, and robust evaluation of agentic conversational AI.
Despite advancements in large language models, building reliable conversational AI for complex, real-time domains remains a significant challenge. This paper, ‘From Transcripts to AI Agents: Knowledge Extraction, RAG Integration, and Robust Evaluation of Conversational AI Assistants’, presents an end-to-end framework for constructing and evaluating such an assistant directly from historical call transcripts, achieving autonomous handling of approximately 30% of inquiries. By leveraging structured knowledge extracted via large language models and deploying a modular, governed prompt structure within a Retrieval-Augmented Generation pipeline, the system demonstrates near-perfect factual accuracy and robust safety measures. Could this transcript-driven approach unlock scalable automation in similarly data-rich, yet traditionally challenging, customer-facing industries?
The Unfolding Conversation: LLMs and the Architecture of Understanding
Large Language Models (LLMs) represent a significant leap forward in natural language processing, achieving an unprecedented capacity to understand and generate human-like text. These models, trained on massive datasets, don’t simply regurgitate information; they learn the statistical relationships between words, allowing for nuanced responses and creative text formats. This capability extends beyond simple question-answering to include tasks like translation, summarization, and even content creation, all with a fluidity previously unattainable by machines. The result is an interaction experience increasingly indistinguishable from communicating with another person, opening doors to more intuitive and efficient human-computer interfaces and fundamentally changing how people access and process information.
Successfully integrating Large Language Models into practical applications extends beyond simply generating text; it demands robust solutions to persistent challenges in both knowledge retrieval and response accuracy. While LLMs demonstrate impressive linguistic capabilities, their performance hinges on accessing relevant and verified information – a process complicated by the vastness and constant evolution of real-world data. Furthermore, ensuring responses are not only grammatically correct but also factually sound, logically consistent, and appropriately nuanced for the specific context remains a significant hurdle. Current research focuses on techniques like retrieval-augmented generation, which dynamically incorporates external knowledge sources, and reinforcement learning from human feedback, aiming to refine LLM outputs and mitigate issues of hallucination and bias, ultimately paving the way for truly reliable and helpful conversational AI systems.
Retrieval as Reconstruction: Grounding LLMs in External Knowledge
Retrieval-Augmented Generation (RAG) addresses limitations in Large Language Model (LLM) performance stemming from their reliance on pre-training data and inherent knowledge cutoffs. RAG operates by first retrieving relevant documents or passages from an external knowledge source – a vector database, document store, or web index – based on the user’s query. These retrieved passages are then prepended to the prompt provided to the LLM, effectively providing the model with contextual information at inference time. This grounding in external, up-to-date information mitigates the generation of factually incorrect or outdated responses and allows LLMs to address queries requiring knowledge beyond their original training data, improving accuracy and reducing hallucinations.
Dense Passage Retrieval (DPR) functions by embedding both the user query and passages from a knowledge base into a high-dimensional vector space. This embedding process utilizes deep neural networks, typically transformer-based models, to generate representations that capture semantic meaning. Relevance is then determined by calculating the similarity between the query vector and each passage vector – commonly using dot product or cosine similarity. The passages with the highest similarity scores are retrieved as the most relevant context. DPR improves upon traditional keyword-based search by identifying passages conceptually related to the query, even if they don’t share exact keywords, and by scaling efficiently to large knowledge bases through optimized indexing and approximate nearest neighbor search algorithms.
Several conversational AI platforms currently integrate Retrieval-Augmented Generation (RAG) to improve response quality. Kore.ai utilizes RAG within its enterprise chatbot framework, enabling more informed and accurate interactions by drawing on external knowledge sources. PolyAI similarly employs RAG to enhance the factual grounding of its conversational agents, particularly in customer service applications. Google Duplex, known for its realistic phone conversations, benefits from RAG by accessing and incorporating real-time information, leading to more contextually relevant and helpful dialogues. These implementations demonstrate a practical trend towards grounding LLMs in external data to overcome limitations in pre-trained knowledge and reduce the occurrence of hallucinations.

Beyond Accuracy: Evaluating the Qualitative Dimensions of Response
Evaluating Large Language Model (LLM) responses necessitates criteria extending beyond simple factual accuracy due to the complex nature of conversational AI. Comprehensive assessment requires evaluating not only whether the response is correct, but also its appropriateness within the conversational context and its alignment with observed user needs and intentions. This holistic approach acknowledges that a factually accurate response can still be unhelpful or inappropriate if it fails to address the underlying query or deviates from the established dialogue flow. Therefore, evaluation frameworks must incorporate metrics that measure these qualitative aspects alongside traditional accuracy scores to ensure a reliable and useful conversational experience.
Transcript Grading is a systematic evaluation method used to determine the quality of assistant responses in conversational AI. This process assesses responses along two key dimensions: Appropriateness, which measures whether the response is generally sensible and relevant in the given context, and Observation Alignment, which verifies that the response is specifically grounded in and consistent with the information provided in the preceding conversation or observed context. By scoring responses against these defined criteria, Transcript Grading provides a quantifiable and reproducible means of identifying strengths and weaknesses in the assistant’s performance and driving iterative improvements to the conversational model.
The evaluation of Large Language Model (LLM) responses benefits from analyzing a representative sample of conversational data, but exhaustive review of all transcripts is impractical. To address this, the Maximum Coverage Problem is employed – a technique from computational linguistics designed to select a minimal subset of transcripts that collectively cover the broadest range of conversational topics and linguistic variations. This approach prioritizes transcripts that introduce new information or represent previously unseen conversational patterns, ensuring that the evaluation process captures a diverse spectrum of real-world interactions. By maximizing the coverage with a limited sample size, the evaluation becomes more efficient and provides more comprehensive insights into the LLM’s performance across a wide variety of use cases.
The evaluation framework currently achieves coverage of up to 35% of real-world call transcripts. Within the Real Estate domain, this framework demonstrates 97% factual accuracy in assessing responses, indicating a low rate of misinformation or incorrect statements. Critically, it also maintains 100% rejection accuracy, meaning the system consistently and correctly identifies and flags inappropriate or policy-violating responses. This performance is based on a statistically significant sample of real-world interactions and represents a key metric for ensuring the reliability and safety of the conversational AI system.
Evaluation within the Specialist Recruitment domain demonstrates a 25% coverage rate of real-world conversational data using our automated assessment framework. This coverage is achieved while maintaining 94% factual accuracy in assistant responses, indicating a high degree of correctness in the information provided. Critically, the system also exhibits 100% rejection accuracy, meaning it reliably identifies and flags inappropriate or unsafe responses, ensuring adherence to defined safety guidelines within this specific application.
Evaluation of conversational AI systems, such as Google Duplex, relies heavily on the integration of three core technologies: Automated Speech Recognition (ASR), Natural Language Understanding (NLU), and Text-to-Speech (TTS). ASR transcribes spoken audio into text, providing a machine-readable representation of the conversation. NLU then processes this text to determine the intent and meaning behind the user’s utterances and the system’s responses. Finally, TTS converts the system’s textual responses back into audible speech for playback and further assessment, allowing for a complete, automated evaluation pipeline that assesses the entire conversational flow beyond simple textual analysis.
The Expanding Horizon: Deployment, Adaptation, and the Architecture of Trust
The practical impact of these language model advancements is increasingly visible in sectors demanding precise information retrieval and personalized interactions. Within the real estate domain, these techniques power virtual assistants capable of understanding nuanced property preferences and delivering tailored listings, significantly streamlining the home search process. Similarly, specialist recruitment benefits from automated screening of candidate profiles, matching skills to job requirements with greater accuracy and efficiency than traditional methods. This application not only accelerates the hiring timeline but also enhances candidate and client satisfaction by presenting more relevant opportunities and talent. These successful implementations demonstrate a clear return on investment, paving the way for broader adoption across industries seeking to optimize communication and decision-making processes.
Prompt tuning represents a significant advancement in harnessing the potential of large language models (LLMs), moving beyond generalized capabilities towards highly specialized performance. This technique involves subtly adjusting the input prompts – the initial instructions given to the LLM – rather than altering the model’s core parameters, offering a computationally efficient pathway to optimization. By carefully crafting these prompts, developers can guide the LLM to consistently deliver responses tailored to specific tasks, such as generating precise real estate descriptions or identifying ideal candidates for niche job roles. The result is not merely improved accuracy, but a predictable and reliable output quality, crucial for real-world applications where consistency is paramount; even minor variations in phrasing can dramatically influence the LLM’s behavior, and prompt tuning provides the control needed to consistently elicit desired results.
Maintaining and refining large language models requires a proactive approach to identifying weaknesses and bolstering their reliability. This is increasingly achieved through techniques like Red Teaming, a process mirroring cybersecurity stress tests. Dedicated teams intentionally probe the system with adversarial prompts – carefully crafted inputs designed to elicit unintended or harmful responses – uncovering vulnerabilities before they can manifest in real-world applications. These rigorous evaluations aren’t simply about fixing errors; they’re about building robustness – the capacity to withstand unexpected inputs and maintain consistent, safe performance. The insights gained from Red Teaming directly inform iterative improvements to the model, ensuring continuous adaptation and a higher degree of trustworthiness as these systems become more deeply integrated into critical domains.
The pursuit of robust conversational AI, as detailed in the study, echoes a fundamental truth about all complex systems. The design prioritizes a modular prompt structure and careful escalation protocols, recognizing that even the most advanced agents will encounter limitations. This mirrors the inevitability of decay; the system isn’t built for perfection, but for graceful aging. As Paul Erdős observed, “A mathematician knows a lot of things, but knows nothing deeply.” Similarly, this agent doesn’t strive for omnipotence, but for reliable performance within defined boundaries, acknowledging the inherent limitations of knowledge and the necessity of safe fallback mechanisms. The focus on handling routine inquiries while escalating complex cases isn’t about avoiding difficulty, but about preserving resilience over time-a principle applicable to all enduring systems.
What Lies Ahead?
The construction of conversational AI, as demonstrated, is less about achieving perpetual uptime and more about managing the inevitable accrual of technical debt. Each added knowledge source, each refinement to the retrieval mechanism, introduces new vectors for decay. The system doesn’t become intelligent; it becomes increasingly complex, demanding constant maintenance to avoid a gradual slide toward unreliability. The modularity described in this work offers a palliative, allowing for localized repairs, but does not halt the underlying entropic process.
Future work will likely focus on automating the detection of this decay-building systems that can self-diagnose knowledge inconsistencies or prompt drift. However, this simply shifts the problem one level higher; the meta-system monitoring for decay will itself be subject to the same forces. The pursuit of ‘robustness’ is, therefore, a temporary alignment with favorable conditions-a rare phase of temporal harmony before the next perturbation.
The true challenge lies not in replicating human conversation, but in accepting the inherent limitations of automated systems. This necessitates a shift in evaluation metrics, away from illusory benchmarks of ‘perfect’ assistance and toward quantifying graceful degradation-measuring how a system fails, rather than attempting to prevent failure altogether. Acknowledging this is not defeatism; it is a pragmatic recognition of the universe’s fundamental asymmetry.
Original article: https://arxiv.org/pdf/2602.15859.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Spotting the Loops in Autonomous Systems
- Seeing Through the Lies: A New Approach to Detecting Image Forgeries
- Staying Ahead of the Fakes: A New Approach to Detecting AI-Generated Images
- Julia Roberts, 58, Turns Heads With Sexy Plunging Dress at the Golden Globes
- Palantir and Tesla: A Tale of Two Stocks
- Gold Rate Forecast
- TV Shows That Race-Bent Villains and Confused Everyone
- The Glitch in the Machine: Spotting AI-Generated Images Beyond the Obvious
- How to rank up with Tuvalkane – Soulframe
- The 25 Marvel Projects That Race-Bent Characters and Lost Black Fans
2026-02-20 05:06