Author: Denis Avetisyan
This review explores the growing synergy between the art of narrative and the power of artificial intelligence, examining how longstanding theories of storytelling are being applied to advance language model capabilities.
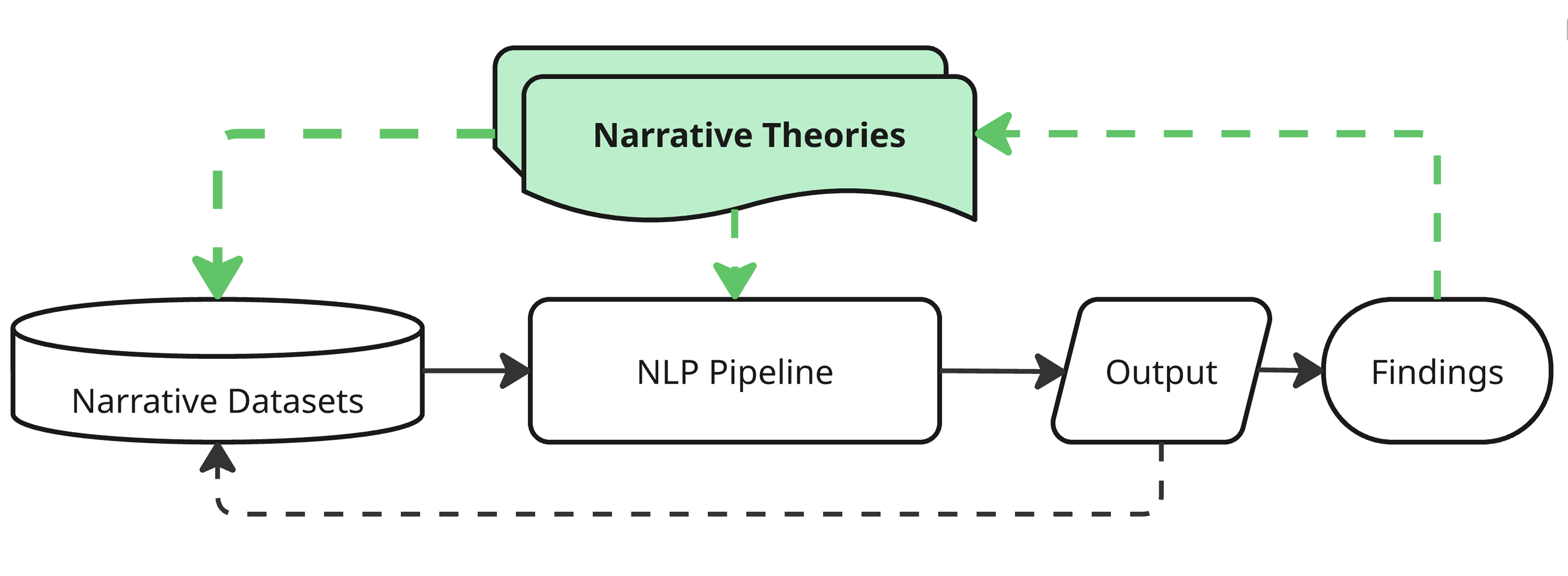
A comprehensive survey of narrative theory-driven methods for automatic story generation and understanding using large language models.
Despite decades of computational narrative research, a unified framework for evaluating ‘story quality’ remains elusive. This paper, ‘Narrative Theory-Driven LLM Methods for Automatic Story Generation and Understanding: A Survey’, systematically examines the burgeoning intersection of large language models (LLMs) and narrative studies, charting how established narratological concepts are being operationalized in tasks like story generation and comprehension. Our analysis reveals emerging patterns in datasets, methodologies-particularly prompting and fine-tuning-and opportunities for interdisciplinary collaboration, while also highlighting the need for theory-based metrics beyond generalized benchmarks. Can a more nuanced, attribute-focused approach to evaluation unlock the full potential of LLMs for both understanding and creating compelling narratives?
The Architecture of Story: Narratology and Computational Beginnings
The human capacity to understand and engage with narratives isn’t merely a pleasurable pastime; it’s deeply interwoven with the very fabric of cognition. Stories provide a foundational structure for how individuals perceive the world, make sense of experiences, and even predict future events. This inherent narrative processing ability shapes memory, facilitates learning, and underpins social understanding, allowing for the transmission of knowledge and the development of empathy. Consequently, as artificial intelligence strives for more sophisticated problem-solving and interaction capabilities, a robust understanding of narrative becomes increasingly vital. The ability to both deconstruct and generate compelling stories is no longer confined to the realm of artistic expression, but represents a crucial step towards creating AI systems capable of genuine communication, nuanced reasoning, and adaptive behavior in complex, real-world scenarios.
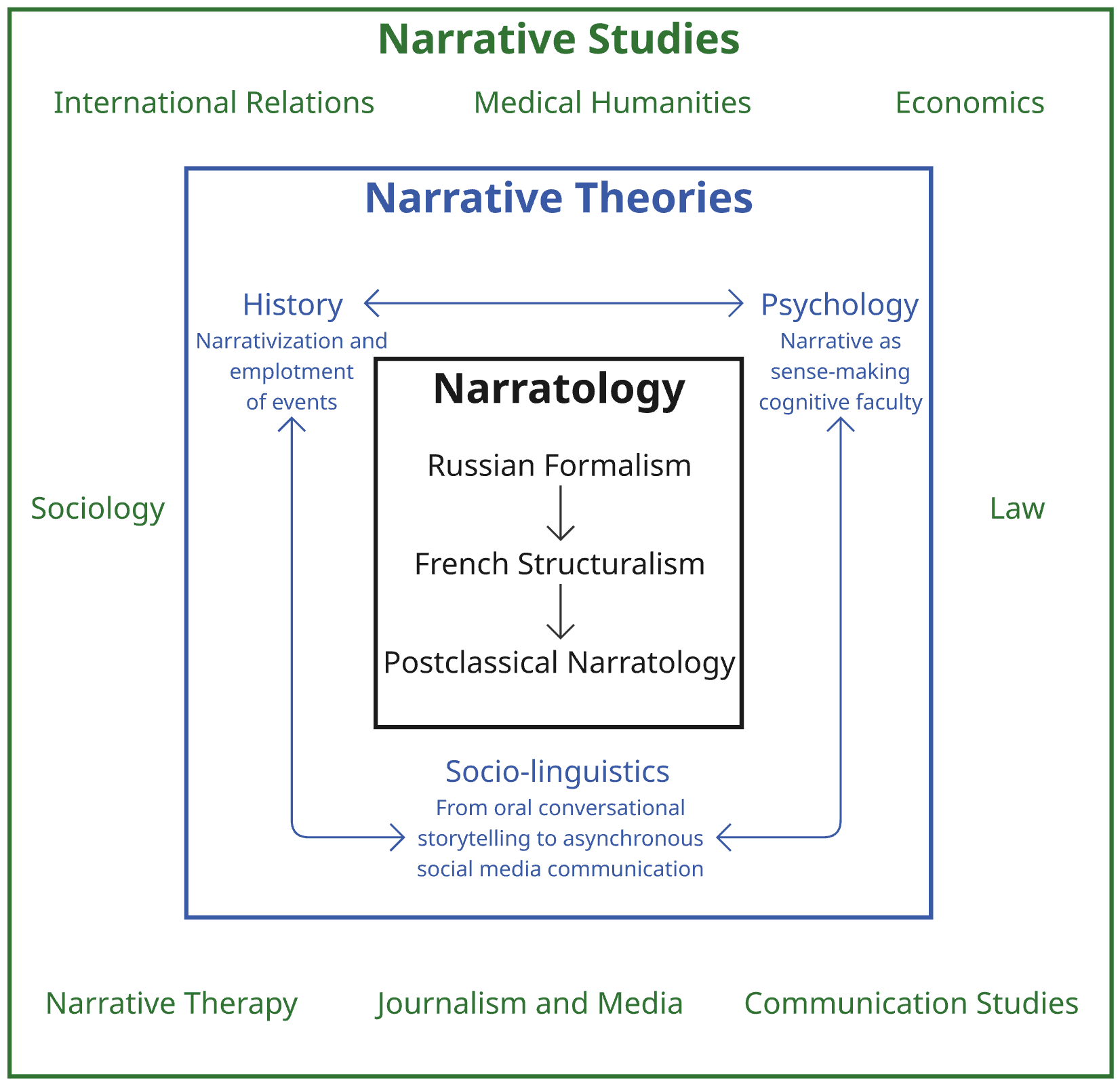
The study of narrative structure, traditionally known as narratology, offers a robust toolkit for deconstructing how stories function, evolving from early formalist approaches – which meticulously mapped plot points and character arcs – to more recent, nuanced post-classical perspectives. These later frameworks move beyond simply what happens in a story to explore how meaning is constructed through unreliable narration, fragmented timelines, and the active role of the audience in interpretation. This shift acknowledges that stories aren’t static entities but dynamic systems where meaning emerges from the interplay between text, reader, and context. Consequently, understanding these diverse analytical lenses is crucial not only for literary scholars, but also for those seeking to model and replicate storytelling processes computationally, providing a foundation for artificial intelligence to engage with narrative in a meaningful way.
Computational storytelling represents a burgeoning interdisciplinary field dedicated to the algorithmic generation and detailed analysis of narratives, effectively merging the traditionally separate domains of humanities and computer science. Current research isn’t solely focused on creating stories from scratch; it also encompasses the development of tools to deconstruct existing narratives, identifying key plot points, character relationships, and thematic elements. This survey highlights prominent trends – including the use of artificial intelligence to personalize storytelling experiences, the development of procedural content generation techniques for dynamic narratives, and the application of natural language processing to enhance story comprehension – alongside anticipated future directions such as emotionally responsive storytelling and the creation of truly interactive, player-driven narratives. The ultimate goal is to not only replicate the art of storytelling through computation, but also to gain a deeper understanding of the underlying principles that make stories so compelling to the human mind.
The Engine of Narrative: Large Language Models
Large Language Models (LLMs) represent a significant advancement in computational linguistics, demonstrating capacity in both narrative comprehension and production. These models, typically based on the transformer architecture and trained on massive datasets of text and code, can process and generate human-quality text, enabling applications such as story summarization, question answering regarding narrative content, and the creation of novel fictional works. Their power stems from the ability to statistically model language, predicting the probability of word sequences and thereby constructing coherent, if not always logically consistent, narratives. Recent LLMs, with parameter counts exceeding hundreds of billions, exhibit emergent capabilities in complex narrative tasks, though performance is highly dependent on model size, training data quality, and task-specific prompting.
Large Language Models (LLMs) demonstrate proficiency in identifying and replicating statistical regularities within text corpora, enabling them to generate syntactically correct and contextually plausible sequences. However, this capability is largely dependent on pattern matching and does not necessarily reflect genuine understanding. Consequently, LLMs frequently exhibit difficulties with tasks requiring complex inference, common-sense reasoning, or maintaining long-range coherence within narratives. These limitations often manifest as logical inconsistencies, factual errors, or abrupt shifts in topic, despite the generated text appearing superficially fluent. While LLMs can effectively mimic stylistic elements and surface-level features of different writing styles, they struggle with the underlying semantic and pragmatic complexities essential for robust narrative comprehension and generation.
Effective utilization of Large Language Models (LLMs) for narrative processing requires specific methodological approaches beyond basic model application. Prompt engineering, involving the careful design of input queries, guides the LLM towards desired outputs and mitigates issues with ambiguity or irrelevant responses. Furthermore, fine-tuning – the process of training a pre-existing LLM on a specific dataset of narrative examples – allows for adaptation to particular styles, tones, or subject matter. This survey details a comprehensive analysis of these techniques, examining the benefits and limitations of various prompt strategies and fine-tuning methodologies as they apply to tasks such as story generation, character development, and plot summarization, with empirical results demonstrating their impact on performance metrics like coherence, relevance, and creativity.
Guiding the Algorithm: Strategies in Prompting
Prompt engineering represents the process of designing effective inputs, or “prompts,” to elicit specific and desired outputs from Large Language Models (LLMs). This is achieved through techniques such as zero-shot prompting, where the LLM generates content without prior examples, and few-shot prompting, which provides a small number of illustrative examples within the prompt itself. These techniques do not alter the LLM’s underlying parameters; instead, they manipulate the input to steer the model toward generating narratives with specific characteristics, including style, tone, and structural elements. The effectiveness of prompt engineering is directly correlated to the precision and relevance of the provided instructions and examples, allowing for a degree of control over the LLM’s creative output.
Zero-shot prompting assesses an LLM’s capacity for narrative generation by requesting a story or continuation without providing any prior examples. This technique relies on the model’s pre-training data and its ability to extrapolate storytelling conventions – such as plot development, character interaction, and thematic consistency – from that data. Evaluation of zero-shot performance indicates the extent to which the LLM has implicitly learned narrative structures and can apply them to novel prompts, serving as a baseline for comparison with techniques like few-shot prompting which provide illustrative examples to guide the output.
Few-shot prompting improves Large Language Model (LLM) performance by conditioning the model on a small set of provided input-output examples. This technique bypasses the need for extensive fine-tuning; instead of adjusting model weights, the prompt itself guides the LLM’s response generation. The examples demonstrate the desired style, tone, or structural elements of the narrative, enabling the LLM to extrapolate and apply these characteristics to new, unseen prompts. Performance gains are particularly notable when the target narrative style deviates from the model’s pre-training data, or when a specific format, such as dialogue structure or character voice, is required. The number of examples used in few-shot prompting typically ranges from one to ten, balancing performance improvement with prompt length considerations.
The Architecture of Meaning: Causal Relationships in Story
Causal Narrative Theory posits that stories aren’t simply sequences of events, but rather intricate networks where each occurrence is meaningfully linked to what precedes and follows. This framework centers on the idea that audiences don’t just experience a plot; they actively construct an understanding of why things happen, constantly seeking connections between actions and their consequences. A compelling narrative, therefore, isn’t merely about what occurs, but about the perceived causality driving the plot forward – the established relationships between events that create a sense of purpose, logic, and ultimately, believability. Understanding these causal links is fundamental to how humans process and remember stories, shaping emotional responses and interpretations of character motivations.
Effective storytelling hinges on more than just a sequence of events; it requires a compelling demonstration of how one event logically leads to another. This principle, central to causal storytelling, fosters a sense of purpose within the narrative, suggesting that outcomes aren’t arbitrary but rather the inevitable consequence of preceding actions. By meticulously establishing these causal links, a story cultivates a powerful sense of immersion, drawing the audience into a world where events feel both meaningful and predetermined. This isn’t merely about explaining what happens, but revealing why it happens, and crucially, why it had to happen that way, thereby deepening engagement and creating a lasting impact.
Current research increasingly focuses on imbuing artificial intelligence with the capacity for causal reasoning to enhance narrative generation. A comprehensive survey of the field reveals a growing trend toward systems that don’t simply string events together, but construct stories based on understood cause-and-effect relationships. This approach aims to move beyond superficial coherence, fostering narratives with greater depth, believability, and emotional resonance. By modeling how actions lead to consequences, and motivations drive characters, AI can create stories that feel less arbitrary and more purposefully unfolding, ultimately boosting audience engagement and creating truly impactful digital storytelling experiences. The survey details both established techniques and emerging methodologies promising significant advancements in computational story understanding and generation.
The survey of narrative theory’s application to large language models reveals a fascinating, yet predictable, cycle. These models, built upon complex architectures, inevitably face the constraints of their design-a concept mirroring the decay inherent in all systems. As the paper details regarding prompt engineering and textual analysis, improvements rapidly outpace comprehension, creating a constant need for refinement. This echoes Blaise Pascal’s observation: “All of humanity’s problems stem from man’s inability to sit quietly in a room alone.” The relentless pursuit of better story generation, a desire to fill the ‘room’ with narrative, highlights the human tendency to avoid stillness and, ultimately, to grapple with the limitations of even the most advanced systems. The study underscores that each architectural iteration lives a life, and researchers are merely witnesses to its evolution and eventual decline.
What Lies Ahead?
The application of narrative theory to large language models, as this survey demonstrates, is not a convergence, but a revealing of fault lines. The systems attempt to mimic structure, yet remain fundamentally divorced from the experience of temporality – they generate sequences, not durations. The inevitable failures in coherence, character motivation, or thematic resonance aren’t bugs, but symptoms of a deeper mismatch. These models, adept at pattern recognition, struggle with the messy, illogical core of what makes a story lived, rather than merely told.
Future progress will likely not stem from more elaborate prompting, or even larger models. Instead, the field needs to confront the limitations inherent in treating narrative as a purely formal system. A focus on the errors – the places where the model’s output deviates from a plausible human narrative – may prove more fruitful than striving for seamless imitation. These deviations are not failures to be corrected, but opportunities to understand where the current paradigm breaks down.
The ultimate challenge isn’t building systems that can tell stories, but acknowledging that every generated narrative is a temporary, imperfect step toward maturity – a fleeting glimpse of order emerging from the inevitable decay of information. The system won’t achieve “understanding”; it will accumulate evidence of its own limitations, and in that accumulation, perhaps, something resembling wisdom.
Original article: https://arxiv.org/pdf/2602.15851.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Wuchang Fallen Feathers Save File Location on PC
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- Gold Rate Forecast
- QuantumScape: A Speculative Venture
- Gemini’s Execs Vanish Like Ghosts-Crypto’s Latest Drama!
- Banks & Shadows: A 2026 Outlook
- HSR 3.7 breaks Hidden Passages, so here’s a workaround
- Nvidia vs AMD: The AI Dividend Duel of 2026
- Here Are the Best TV Shows to Stream this Weekend on Hulu, Including ‘Fire Force’
2026-02-19 22:26