Author: Denis Avetisyan
A new approach to long-term memory is emerging in artificial intelligence, prioritizing the storage of raw data and on-demand analysis for more adaptable and insightful agents.
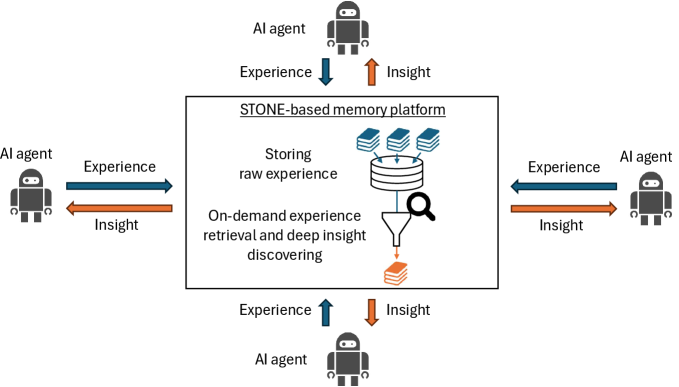
This review proposes shifting AI memory design from ‘extract-then-store’ to ‘store-then-on-demand-extract’ paradigms, leveraging non-parametric memory and experience sharing for enhanced performance and knowledge discovery.
Current artificial intelligence systems struggle with robust long-term memory, often sacrificing valuable information during knowledge consolidation. This is addressed in ‘Revolutionizing Long-Term Memory in AI: New Horizons with High-Capacity and High-Speed Storage’, which proposes a shift from extracting and storing only deemed-relevant data to retaining raw experiences for flexible, on-demand analysis. The authors demonstrate the potential of this ‘store then extract’ approach, alongside methods for deeper insight discovery from experience and efficient knowledge sharing, to overcome limitations of existing architectures. Could these strategies unlock truly adaptable and intelligent AI agents capable of sustained learning and complex problem-solving?
The Illusion of Continuous Learning
Recent advancements in Large Language Models (LLMs) have undeniably revolutionized the field of artificial intelligence, demonstrating an unprecedented capacity for generating human-quality text and performing complex language-based tasks. However, this progress belies a fundamental constraint: the inability to learn continuously in the same way a human does. While LLMs excel at processing vast datasets during their initial training, integrating new information without overwriting existing knowledge-a process crucial for genuine intelligence-remains a significant challenge. This limitation stems from their reliance on a fixed set of parameters; each new piece of information requires adjusting billions of weights, potentially disrupting previously learned patterns and leading to “catastrophic forgetting.” Consequently, LLMs struggle to adapt to dynamic environments or accumulate knowledge over time, hindering their trajectory towards achieving Artificial General Intelligence and raising questions about the very nature of intelligence they simulate.
Current Large Language Models fundamentally store information within the very fabric of their neural network – a process known as parametric memory. This approach, while enabling impressive feats of text generation and understanding, presents significant limitations. Unlike humans who can readily acquire and integrate new knowledge without losing previously learned information, LLMs struggle with what’s known as catastrophic forgetting. Each new piece of data necessitates adjustments to the model’s billions of weights, potentially overwriting or distorting existing knowledge. This inefficiency stems from the fact that knowledge isn’t stored as discrete, easily modifiable facts, but rather distributed across the entire network. Consequently, continuous learning – the ability to adapt and accumulate knowledge over time – remains a major hurdle in the pursuit of true Artificial General Intelligence, as LLMs require retraining or complex mitigation strategies to avoid losing previously learned capabilities.
The rigidity of parametric memory within Large Language Models presents a fundamental obstacle to achieving Artificial General Intelligence. Unlike humans, who continuously integrate new information with existing knowledge, LLMs struggle with dynamic environments because updating their internal weights to accommodate fresh data often overwrites previously learned information – a phenomenon known as catastrophic forgetting. This limitation creates a bottleneck; the model’s capacity for adaptation is constrained by the finite and inflexible nature of its knowledge storage. Consequently, LLMs exhibit diminished performance when confronted with situations that deviate from their original training data, hindering their ability to generalize and reason effectively in the complex, ever-changing real world – a crucial hallmark of true intelligence.
Beyond Parameters: External Memory as a Scalable Solution
Traditional Large Language Models (LLMs) store all acquired knowledge within their parameter weights, creating a fixed knowledge base and limiting adaptability. External memory systems address this limitation by separating knowledge storage from the model itself. This decoupling enables continuous learning; new information can be added to the external memory without requiring retraining of the LLM’s parameters. Consequently, the model can adapt to evolving data and tasks by retrieving and utilizing information from the external source, effectively scaling its knowledge capacity beyond the constraints of its internal parameters and facilitating ongoing refinement without catastrophic forgetting.
Retrieval-Augmented Generation (RAG) and In-Context Learning (ICL) are two prominent techniques that improve Large Language Model (LLM) performance by incorporating external knowledge sources. RAG functions by first retrieving relevant documents from a knowledge base based on a user’s query, then using those retrieved documents to inform the LLM’s response generation. ICL, conversely, provides the LLM with a limited number of example question-answer pairs directly within the prompt, allowing it to learn the desired task or apply specific knowledge without updating its internal parameters. Both methods enable LLMs to access and utilize information beyond their pre-training data, addressing limitations in knowledge cutoffs and factual accuracy, and facilitating adaptation to new or specialized domains.
Effective utilization of external knowledge sources requires careful consideration of both storage and retrieval methods to optimize performance. Raw access to data is insufficient; the organization of information within the external memory impacts the speed and accuracy with which relevant content can be identified and integrated. Factors such as data indexing, vector embedding strategies, and the selection of appropriate similarity metrics directly affect retrieval efficiency. Furthermore, the method by which retrieved information is presented to the Large Language Model (LLM)-including formatting, context window limitations, and relevance ranking-significantly influences the LLM’s ability to effectively utilize the external knowledge for tasks like question answering or content generation.
From Extraction to Retention: A Paradigm Shift
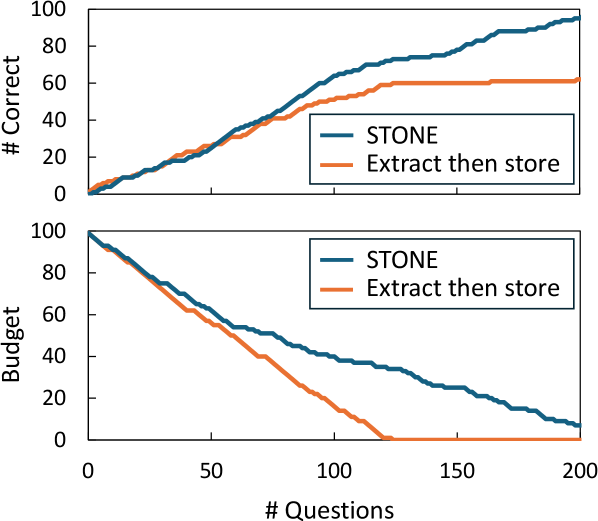
Traditional methods of experience storage typically involve an initial extraction phase where raw data is processed and condensed into a summarized representation before being stored. This ‘Extract Then Store’ approach, while computationally efficient for storage, inherently results in data loss as nuanced details and potentially relevant information are discarded during summarization. The specific features deemed unimportant during extraction are permanently unavailable for future analysis, limiting the potential for discovering novel insights from the original experience. Consequently, the stored representation may not accurately reflect the complete original data, impacting the fidelity of any subsequent retrieval or analysis performed on it.
The Store Then ON-demand Extract (STONE) paradigm represents a shift in data handling by prioritizing the complete retention of original experiential data rather than immediate summarization. This approach stores raw inputs without pre-processing, enabling subsequent, flexible re-analysis as analytical techniques evolve or new questions arise. Unlike traditional methods that discard potentially valuable nuance during compression, STONE facilitates the discovery of deeper insights through repeated examination of the unaltered data. The ability to revisit original experiences allows for the identification of subtle patterns and correlations that might be lost in pre-processed or summarized forms, offering a more comprehensive and adaptable knowledge base.
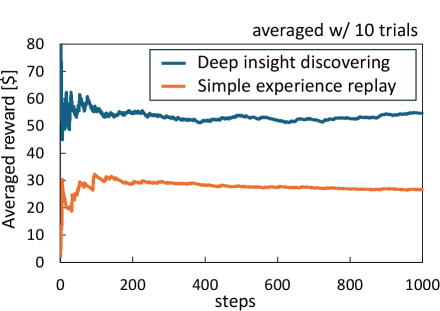
The efficacy of retaining raw experiential data is significantly enhanced when coupled with Deeper Insight Discovery techniques. These methods utilize external memory – separate from the immediate processing unit – to analyze stored experiences for recurring patterns and correlations that might be missed through traditional, summarized data analysis. By accessing and comparing complete, unedited records across multiple instances, Deeper Insight Discovery can identify subtle relationships and previously unseen insights. This contrasts with systems limited to pre-processed information, where potentially valuable data is discarded during the initial summarization process, hindering comprehensive pattern recognition and limiting the potential for novel discoveries.
A Key-Value cache (KV-Cache) optimizes the retrieval of stored experiences within a ‘Store Then ON-demand Extract’ (STONE) paradigm by providing rapid access to frequently requested data. This caching mechanism stores experience data indexed by a unique key, allowing the system to bypass the potentially time-consuming process of re-analyzing raw experience data for each request. KV-Cache implementations typically utilize in-memory storage for minimal latency and can be configured with eviction policies – such as Least Recently Used (LRU) – to manage cache size and ensure the most relevant experiences are readily available. Effective KV-Cache utilization significantly reduces computational cost and improves response times when accessing and re-interpreting stored experiences, particularly in applications requiring real-time or near real-time access to past data.
Scaling Intelligence Through Shared Experience: The Collective Advantage
Experience memory sharing represents a paradigm shift in artificial intelligence, allowing multiple agents to collectively enhance their learning capabilities. Rather than each agent independently acquiring knowledge through trial and error, this framework enables the distribution of learned experiences across a network. This collaborative approach significantly reduces the computational cost and time required for individual agents to achieve proficiency. By leveraging the accumulated knowledge of others, agents can bypass redundant learning cycles and rapidly adapt to new challenges. The resulting acceleration of collective intelligence opens possibilities for tackling complex problems that would be intractable for isolated AI systems, fostering a more efficient and robust learning environment for all participating agents.
The efficient dissemination of learned experiences hinges on the architecture of Knowledge Delivery Networks, which function as specialized communication pathways between artificial intelligence agents. These networks don’t simply transmit raw data; rather, they prioritize and deliver knowledge in a targeted manner, ensuring that relevant information reaches agents capable of utilizing it most effectively. This structured approach bypasses the inefficiencies of broadcasting information to all agents indiscriminately, dramatically reducing communication overhead and accelerating the learning process. By intelligently routing experiences – successes, failures, and nuanced observations – across the network, agents collectively build a more comprehensive understanding of their environment, leading to significantly improved performance and adaptability without requiring each individual agent to independently acquire all necessary knowledge.
To efficiently refine learning, agents within this framework don’t simply absorb all shared experiences equally. Instead, they employ Multi-Armed Bandit algorithms – a strategy borrowed from the realm of reinforcement learning – to dynamically prioritize which experiences are most valuable for adaptation. This approach treats each experience as a “bandit” – a slot machine with an unknown payout – and agents learn to allocate more “plays” – or learning attempts – to those experiences yielding the greatest informational reward. Consequently, agents swiftly converge on the most impactful data, accelerating knowledge acquisition and minimizing exposure to redundant or unhelpful information. This selective absorption ensures that learning resources are concentrated on experiences that drive the most significant improvements in performance and generalization capabilities.
The architecture leverages the complementary strengths of episodic and semantic memory to facilitate robust learning and adaptation. Episodic memory functions as a detailed record of specific experiences – a ‘what, where, and when’ of events – enabling agents to recall precise situations and replay them for analysis or refinement. Simultaneously, semantic memory distills these experiences into generalized knowledge and concepts, extracting overarching principles and relationships. This integration isn’t merely additive; the system actively transfers information between these memory types, allowing agents to not only remember that a particular action succeeded in a specific context, but also to understand why, and to apply that understanding to novel situations. Consequently, the agents build a more comprehensive and flexible knowledge base, accelerating the learning process and improving performance across a wider range of challenges.
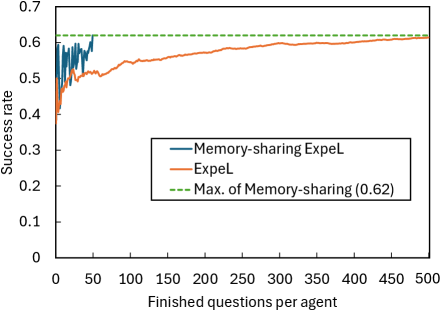
The research demonstrates a substantial leap in efficiency through shared learning experiences among artificial intelligence agents. Agents leveraging a system of experience memory sharing achieved a success rate of 0.62 after processing just 50 questions each – a tenfold improvement over the performance of a single agent. This solitary agent required processing a complete dataset of 500 questions to reach the equivalent success level, highlighting the power of collective intelligence and dramatically reduced computational costs. This suggests a pathway toward scalable AI systems where knowledge is not individually acquired, but rather distributed and refined through interconnected networks, accelerating learning and problem-solving capabilities.
The pursuit of ever-more-sophisticated AI memory architectures feels… familiar. This paper’s focus on ‘Store Then ON-demand Extract’ merely renames a problem engineers have battled for decades – the cost of keeping everything versus the pain of rebuilding it. It’s a predictable cycle; today’s elegant solution becomes tomorrow’s performance bottleneck. As Linus Torvalds once said, “Most programmers think that if their code works, they’re finished. The truth is, they’ve just begun.” The ambition to enable ‘knowledge sharing’ between agents is laudable, but one suspects the resulting data swamps will require even more elaborate – and eventually brittle – extraction methods. They don’t build systems; they leave notes for digital archaeologists.
What’s Next?
The advocacy for ‘Store Then ON-demand Extract’ offers a compelling architectural shift, yet history suggests that even elegantly designed memory systems will ultimately succumb to the chaos of sustained production load. The promise of deeper insight discovery hinges on effective indexing and retrieval from these raw experience stores-a problem conveniently downplayed in the rush toward capacity. One anticipates a resurgence of interest in approximate nearest neighbor search, and a painful realization that ‘ON-demand’ is frequently synonymous with ‘eventually, after a concerning delay’.
The notion of experience sharing across agents introduces a delightful new category of failure modes. Synchronization issues, schema drift, and the inevitable propagation of bad data will quickly test the robustness of any proposed sharing protocol. It’s easy to envision a future where agents are less concerned with collective intelligence and more with quarantining compromised peers. Every abstraction dies in production, and shared memory is, by definition, a shared point of failure.
Ultimately, the true challenge isn’t just storing more experience, but discerning which experiences matter. The field will likely circle back to the fundamental question of intrinsic motivation and reward signals. Until AI agents can reliably distinguish signal from noise, even the most capacious memory will simply be a beautifully organized archive of irrelevance. Everything deployable will eventually crash; the art lies in building a system that crashes gracefully-and with sufficiently informative error messages.
Original article: https://arxiv.org/pdf/2602.16192.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Wuchang Fallen Feathers Save File Location on PC
- Gold Rate Forecast
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- 17 Black Actresses Who Forced Studios to Rewrite “Sassy Best Friend” Lines
- Crypto Chaos: Is Your Portfolio Doomed? 😱
- HSR 3.7 breaks Hidden Passages, so here’s a workaround
- Elden Ring’s Fire Giant Has Been Beaten At Level 1 With Only Bare Fists
- Here Are the Best TV Shows to Stream this Weekend on Hulu, Including ‘Fire Force’
- Anime Series Hiding Clues in Background Graffiti
2026-02-19 08:58