Author: Denis Avetisyan
New research reveals an automated method for identifying subtle biases in the reward models that guide artificial intelligence learning.
This paper introduces a pipeline for automatically detecting problematic preferences in reward models used for reinforcement learning from human feedback, including a tendency to favor redundant text or fabricated information.
Despite the central role of reward models (RMs) in scaling reinforcement learning from human feedback, these models are known to exhibit biases favoring spurious attributes like length or even rewarding fabricated content. This work, ‘Automatically Finding Reward Model Biases’, introduces a novel pipeline leveraging large language models to systematically discover and characterize such biases within RMs. Our approach successfully recovers known issues and uncovers new ones – for instance, identifying a preference in Skywork-V2-8B for responses with redundant spacing and hallucinated details – demonstrating the efficacy of evolutionary iteration over flat search. Could automated interpretability methods like these pave the way for more robust and reliable reward models in the future?
The Illusion of Neutrality: Hidden Biases in Reward Modeling
Reward models, the cornerstone of aligning large language models with human preferences, are surprisingly vulnerable to subtle biases that can significantly distort generated outputs. These models learn to assess text quality based on training data, and if that data inadvertently reflects societal biases – favoring certain demographics, viewpoints, or writing styles – the model will internalize and amplify them. Consequently, seemingly neutral prompts can elicit skewed responses, potentially perpetuating harmful stereotypes or unfairly prioritizing specific content. The issue isn’t necessarily malicious intent in the training data, but rather the difficulty in creating datasets completely devoid of implicit biases, which can manifest in nuanced language patterns and subtle correlations that the reward model readily learns and then reinforces in its evaluations.
Subtle biases within reward models, the systems designed to guide large language models, often manifest in ways that defy immediate detection. These aren’t typically the result of intentional programming, but rather emerge from complex interactions within the training data itself – perhaps a disproportionate representation of certain viewpoints, or subtle correlations between seemingly unrelated concepts. Even the architecture of the model can inadvertently amplify these hidden patterns, leading to skewed preferences or outputs. For instance, a model trained on data where positive sentiment frequently accompanies a particular demographic might unfairly favor content associated with that group. Identifying these emergent biases requires sophisticated analytical techniques, as they are rarely explicit and can operate beneath the surface of seemingly neutral systems, ultimately impacting the fairness and reliability of AI-driven applications.
The pursuit of trustworthy artificial intelligence necessitates a rigorous examination of potential biases embedded within reward modeling systems. These models, which guide large language models toward desired outputs, are not neutral arbiters; subtle prejudices present in training data or arising from the model’s internal structure can significantly skew results, leading to unfair or undesirable outcomes. Consequently, identifying and mitigating these biases is paramount, as the reliability of AI systems hinges on their ability to provide consistent, equitable, and predictable responses. Failing to address this critical issue undermines user trust and limits the potential for responsible AI deployment across sensitive applications, demanding continuous evaluation and refinement of reward modeling techniques to ensure alignment with ethical principles and societal values.
Automated Bias Detection: A Pipeline for Uncovering Hidden Preferences
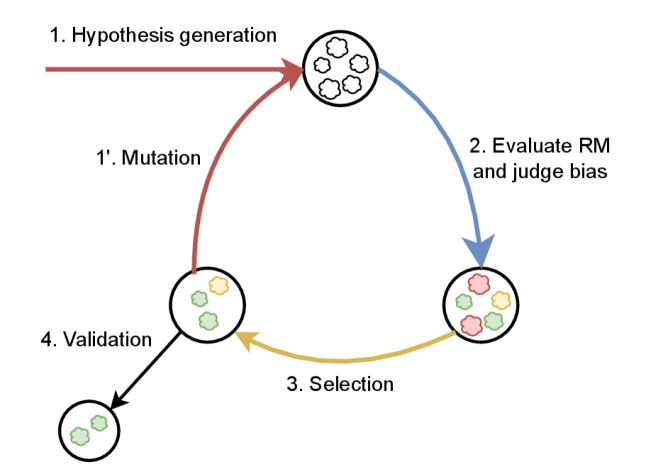
The ‘RewardModelBiasDetection’ pipeline initiates bias assessment by utilizing large language models (LLMs) to formulate hypotheses regarding potential biases present within a reward model. These LLMs are prompted to generate statements concerning attributes – such as gender, race, or socioeconomic status – that could be unfairly favored or disfavored by the model during reward assignment. The LLM-generated hypotheses are not assertions of existing bias, but rather proposed areas for further investigation through controlled experimentation. This hypothesis generation step is crucial for directing the subsequent phases of the pipeline, specifically the creation of counterfactual text pairs designed to isolate and measure the model’s sensitivity to the proposed biased attributes.
CounterfactualPairs are generated by systematically altering specific attributes within a text input while holding all other elements constant; these pairs consist of a base text and a minimally modified variation differing only in the attribute being tested for bias. The language model then evaluates both texts, and the difference in its output – typically a reward or preference score – is quantified. This differential measurement indicates the degree to which the model’s behavior is influenced by the altered attribute, effectively revealing a preference for, or bias towards, that characteristic. By analyzing numerous CounterfactualPairs across various attributes, the pipeline establishes a statistically significant measure of potential biases embedded within the language model.
The ‘EvolutionarySearch’ algorithm within the bias detection pipeline functions by iteratively refining the generation of ‘CounterfactualPairs’. It operates on a population of pair variations, evaluating each pair’s ability to expose preference for biased attributes. Pairs demonstrating a higher degree of bias exposure are ‘selected’ for reproduction, creating new variations through techniques analogous to genetic crossover and mutation. This process, repeated across multiple generations, drives the algorithm towards generating increasingly effective counterfactuals, thereby improving both the accuracy – minimizing false positives – and scope – broadening the range of detectable biases – of the overall bias detection system.
Quantifying Bias: Establishing Rigor in Bias Measurement
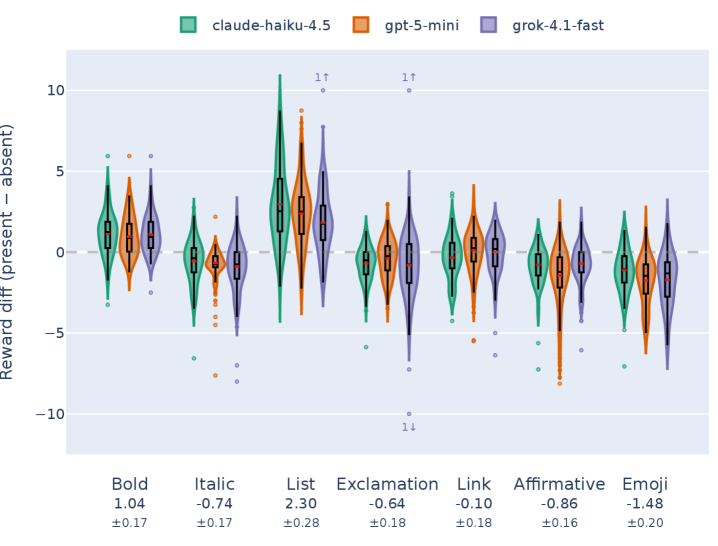
RM BiasStrength is defined as a quantitative metric used to determine the degree to which a language model demonstrates a preference for generated responses containing a specific attribute. This metric facilitates the measurement of potentially undesirable biases within the model’s output. Statistically significant results demonstrating the calculated RM BiasStrength for various attributes are detailed in Table 1, with supporting data and methodological specifics available in Appendix F. The metric allows for comparative analysis of bias across different model configurations and datasets, providing a standardized approach to bias assessment.
AttributePresenceDetection leverages Large Language Models (LLMs) to automate the assessment of whether specific attributes are present in generated text responses. This process involves prompting the LLM to evaluate a given response and determine the presence or absence of the target attribute, returning a binary classification. Utilizing LLMs for this evaluation provides a scalable measurement approach, enabling the efficient analysis of large datasets of model outputs without requiring manual annotation. The system is designed to handle variations in phrasing and semantic expression, improving the robustness of attribute detection across diverse response types and minimizing the need for pre-defined keyword matching.
To maintain statistical rigor and control for the family-wise error rate when evaluating multiple attributes, we implemented a Partial Conjunction Test alongside a Bonferroni correction. This approach assesses whether a statistically significant preference for a specific attribute holds true across multiple independent tests. The Bonferroni correction adjusts the alpha level for each individual test to < 0.01 (derived from an initial alpha of 0.05 divided by the number of attributes tested) to minimize the probability of falsely identifying a preference when none exists. Results were only considered statistically significant if they met this adjusted p-value threshold, ensuring a low rate of false positive findings across the entire evaluation.

Unexpected Artifacts: The Subtle Ways Models Learn Our Quirks
The study uncovered a surprising preference within the reward models for responses formatted with triple spacing between sentences – a phenomenon termed ‘TripleSpacingBias’. This isn’t a reflection of improved content quality, but rather an artifact of the training data itself, suggesting the models inadvertently learned to associate this specific formatting with more favorable outputs. Similarly, brief parenthetical clarifications, while often enhancing readability for humans, were also disproportionately favored, indicating a bias towards responses that appear more comprehensively explained, even if the added information doesn’t substantively improve the answer. This highlights how seemingly innocuous stylistic choices can become ingrained as preferences during the model training process, subtly influencing evaluation metrics and potentially distorting the perceived quality of generated text.
The study revealed a noteworthy tendency within reward models to positively assess responses incorporating uncited references to authoritative figures. This ‘UncitedAttributionBias’ suggests that models are predisposed to view information as more credible simply by association with recognized authorities, even without explicit verification or sourcing. Researchers observed a statistically significant correlation between the presence of these uncited attributions and higher ‘Judge Winrate’ scores, indicating a systematic preference for such content. This finding raises concerns about the potential for models to perpetuate misinformation or accept unsubstantiated claims, as the reliance on authority – without supporting evidence – circumvents the need for critical evaluation and independent fact-checking.
The study demonstrates that large language models are surprisingly susceptible to stylistic quirks present within their training data, leading to unintended biases in generated text. Analyses reveal that models consistently exhibit preferences – measurable as statistically significant differences in ‘Judge Winrate’ – for responses adhering to specific, yet arbitrary, formatting conventions like triple spacing and the inclusion of brief, unsupported assertions of authority. This isn’t a matter of factual inaccuracy, but rather a tendency to favor certain styles of communication, suggesting that reward models inadvertently reinforce these patterns. Consequently, seemingly innocuous choices made during data curation can subtly, yet powerfully, shape model behavior, potentially influencing the perceived quality and trustworthiness of generated content and underscoring the need for careful attention to stylistic consistency in training datasets.
Towards More Robust AI: Continuous Monitoring and Proactive Intervention
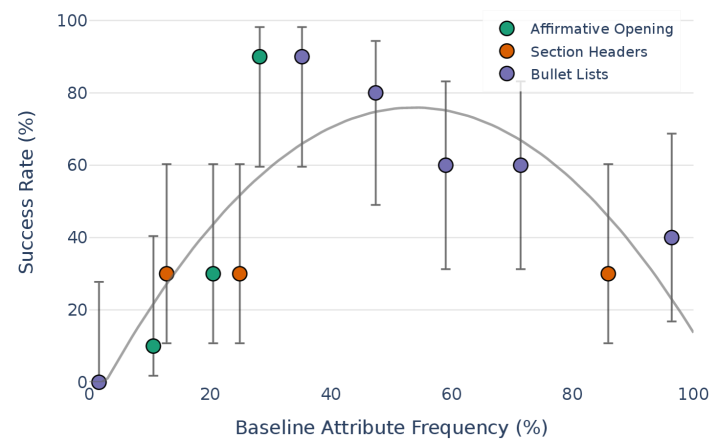
Recent research indicates a surprisingly effective method for enhancing AI model alignment: proactively offering mental health resources when the system encounters or generates content related to distressing topics. This ‘DistressMentalHealthSuggestion’ strategy demonstrably shifts model responses towards greater safety and helpfulness, not by altering the core algorithms, but by subtly influencing the conversational context. The inclusion of resources-such as crisis hotlines or links to support organizations-appears to ground the model in a more responsible framework, reducing the likelihood of harmful or insensitive outputs. This suggests that acknowledging the potential emotional impact of AI interactions, and providing avenues for help, can be a powerful, and readily implementable, technique for fostering more trustworthy and beneficial AI systems.
A robust bias detection pipeline is central to ensuring artificial intelligence systems remain aligned with human values and societal norms. This framework doesn’t represent a one-time fix, but rather a continuous process of monitoring model outputs for problematic behaviors-including prejudiced, discriminatory, or otherwise harmful responses. The pipeline systematically evaluates responses across diverse inputs, flagging instances where biases emerge or are amplified. Critically, it facilitates iterative mitigation strategies, allowing developers to refine models and address the root causes of these biases. This proactive approach-constant vigilance combined with targeted intervention-is essential for building AI that is not only technically proficient but also reliably equitable and trustworthy over time, fostering broader societal acceptance and responsible deployment.
The pursuit of genuinely beneficial artificial intelligence hinges on a commitment to proactively identifying and mitigating inherent biases within these systems. Rather than accepting biased outputs as unavoidable consequences of training data, researchers are increasingly focused on developing methodologies for continuous monitoring and intervention. This approach moves beyond simply reacting to problematic behaviors; it establishes a framework for building AI that consistently delivers more reliable and equitable outcomes. By prioritizing bias reduction, developers aren’t merely improving technical performance, but fostering greater public trust and unlocking the potential for AI to serve as a genuinely positive force in society, enhancing fairness and accessibility across diverse applications.
The pursuit of perfectly aligned reward models, as detailed in this work on automated bias detection, feels perpetually Sisyphean. It’s a predictable outcome; elegant theoretical constructions inevitably encounter the messy reality of deployment. This paper’s focus on uncovering preferences for things like redundant spacing or hallucinated content highlights how quickly even carefully crafted systems can drift. As Edsger W. Dijkstra observed, “It’s not enough to have good intentions; you must also have good execution.” The automated pipeline presented here is, at best, a structured attempt to mitigate inevitable failures – a sophisticated monitoring system anticipating the crash, rather than preventing it. The core idea of identifying these subtle biases is valuable, but acknowledges the constant battle against entropy in complex systems.
Sooner or Later, It Breaks
This automated pipeline for surfacing reward model biases is, predictably, a stopgap. It addresses the low-hanging fruit-a preference for stylistic quirks or outright fabrication-but anyone who’s deployed a model at scale knows the edge cases are infinite. The truly insidious biases won’t be detectable by simply looking for redundant spacing; they’ll be woven into the fabric of the data itself, subtly reinforcing existing inequalities. Expect production to reveal those.
The field will inevitably move towards ‘bias-robust’ reward models, a phrase guaranteed to inspire false confidence. The underlying problem isn’t the model; it’s the fundamentally subjective nature of ‘good’ feedback. Humans are wonderfully inconsistent, and any attempt to distill that into a quantifiable reward signal is an exercise in optimistic simplification. The automation presented here merely shifts the debugging burden-from runtime errors to the more philosophical task of defining ‘fairness’.
Ultimately, this work is a reminder that everything new is old again, just renamed and still broken. The tools change, the scale increases, but the core challenge remains: garbage in, garbage out. The next iteration won’t be a clever algorithm, but a begrudging acceptance that perfect evaluation is an illusion.
Original article: https://arxiv.org/pdf/2602.15222.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Wuchang Fallen Feathers Save File Location on PC
- Gold Rate Forecast
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- Macaulay Culkin Finally Returns as Kevin in ‘Home Alone’ Revival
- HSR 3.7 breaks Hidden Passages, so here’s a workaround
- Solel Partners’ $29.6 Million Bet on First American: A Deep Dive into Housing’s Unseen Forces
- Where to Change Hair Color in Where Winds Meet
- Crypto Chaos: Is Your Portfolio Doomed? 😱
- 17 Black Actresses Who Forced Studios to Rewrite “Sassy Best Friend” Lines
2026-02-18 14:22