Author: Denis Avetisyan
As real-world data becomes increasingly scarce and expensive, researchers are turning to simulation and digital twins to generate the datasets needed to build robust and intelligent agents.
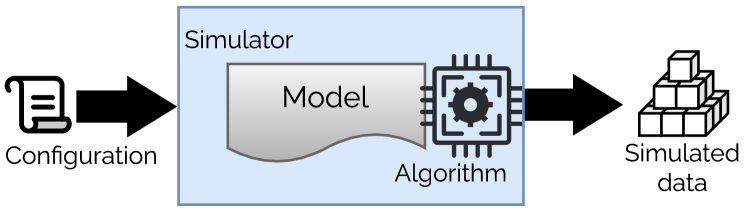
This review explores the use of simulated data, particularly from digital twins, to overcome limitations in AI training and bridge the sim-to-real gap, proposing a framework for effective integration.
Despite advances in artificial intelligence, insufficient and low-quality data remain significant obstacles to deploying modern subsymbolic AI systems. This paper, ‘Developing AI Agents with Simulated Data: Why, what, and how?’, explores simulation-and particularly the use of digital twins-as a promising solution for generating synthetic data to overcome these limitations. By offering a systematic approach to data creation, simulation not only addresses data scarcity but also seeks to bridge the critical ‘sim-to-real’ gap inherent in transferring AI models to real-world applications, proposing a framework (DT4AI) to guide implementation. Could widespread adoption of simulation-based synthetic data unlock the full potential of AI agents in complex and data-constrained environments?
Bridging the Gap: The Promise of Simulated Reality
The development of artificial intelligence frequently encounters a significant hurdle: the disparity between performance in controlled simulation and real-world application, often termed the ‘Sim-to-Real Gap’. Acquiring training data directly from physical environments can be prohibitively expensive, particularly for robotics or autonomous systems requiring extensive operational hours. Furthermore, certain scenarios present inherent dangers – testing self-driving cars in unpredictable traffic or training robots in hazardous waste cleanup, for example – making real-world experimentation ethically questionable or logistically impossible. Even when cost and safety are not primary concerns, the sheer impracticality of generating sufficient data – encompassing the vast diversity of real-world conditions – often limits the effectiveness of AI training, necessitating alternative approaches to bridge this critical performance gap.
Artificial intelligence development increasingly leverages the power of synthetic data generated through AI simulation as a means to overcome limitations inherent in real-world training. This approach allows for the creation of vast datasets, meticulously labeled and customized to specific application needs, without the costs, safety concerns, or logistical hurdles often associated with collecting data from physical environments. By training algorithms on these simulated scenarios, developers can significantly enhance model robustness and generalization capabilities, effectively accelerating the learning process and reducing the reliance on scarce and potentially biased real-world data. The technique proves particularly valuable in fields like robotics and autonomous driving, where acquiring sufficient training data through physical experimentation is both expensive and carries inherent risks, and allows for exploration of edge cases and rare events that would be difficult or impossible to capture otherwise.
The efficacy of AI simulation as a bridge to real-world deployment hinges critically on the fidelity and diversity of the synthetic environments created. A simulation lacking in realism – be it in visual textures, physical interactions, or unpredictable events – can lead to models that perform well within the virtual space but falter when confronted with the complexities of the actual world. Consequently, researchers are focusing on techniques to generate simulations that accurately mirror the statistical distribution of real-world data, incorporating elements of randomness and edge-case scenarios. Advanced methods include domain randomization, where simulation parameters are varied extensively, and generative adversarial networks (GANs), used to create photorealistic and physically plausible virtual settings, all aimed at minimizing the performance gap and ensuring robust AI systems capable of navigating unpredictable, real-world challenges.

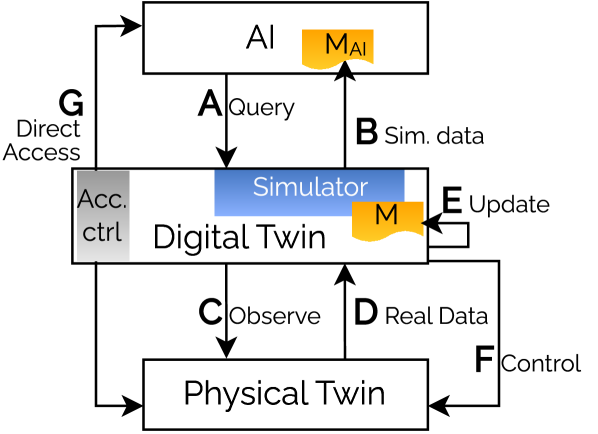
Digital Twins: Virtual Replicas for Enhanced Training
Digital Twins create virtual representations of physical assets – encompassing their characteristics, behavior, and performance – with a level of fidelity sufficient for realistic simulation. These replicas are constructed using data gathered from various sources, including sensors, historical records, and engineering specifications. The resulting high-fidelity models allow for the replication of complex physical phenomena and system interactions within a virtual environment, enabling controlled experimentation and analysis that would be impractical or impossible with the physical asset itself. This capability extends to simulating a wide range of scenarios, from routine operations to extreme conditions, providing a comprehensive dataset for analysis and predictive modeling.
Digital Twins utilize distinct simulation techniques tailored to the characteristics of the modeled system. Discrete Simulation is employed for event-driven systems, where changes in state occur at specific points in time; this approach is suitable for modeling queuing systems or logistical processes. Conversely, Continuous Simulation is used for dynamic processes that evolve continuously over time, requiring the solution of differential equations to represent changes in variables like temperature, pressure, or velocity. The selection of either technique, or a hybrid approach, depends on the nature of the physical asset and the specific AI training requirements; both methods contribute to generating the synthetic data needed for robust AI model development.
The DT4AI Framework is designed to integrate Digital Twins directly into the artificial intelligence training process. This integration streamlines data generation by leveraging the Digital Twin’s ability to produce synthetic datasets reflecting real-world conditions. Model refinement is accelerated through iterative training and validation cycles within the virtual environment, allowing for faster identification and correction of biases or inaccuracies. Consequently, the framework promotes the development of AI models exhibiting increased efficiency and reliability, as they are trained on high-fidelity data and validated against realistic scenarios before deployment in physical systems.
Expanding Simulated Worlds: Techniques for Robustness
Effective AI simulation leverages diverse methodologies tailored to specific requirements; Agent-Based Simulation models the actions and interactions of autonomous entities within a defined environment, proving useful for scenarios involving crowd behavior or logistical operations. Complementing this, Computational Fluid Dynamics (CFD) utilizes numerical analysis and data structures to accurately simulate fluid motion-air, water, etc.-essential for training AI in robotics, aerodynamics, or weather prediction. These methods are often combined; for instance, an Agent-Based Simulation of autonomous vehicles might integrate CFD to model aerodynamic drag and wind effects. The selection of simulation method is dictated by the complexity of the desired environment and the fidelity required for effective AI training and validation.
Monte Carlo Simulation contributes to dataset diversity by introducing randomness into simulation parameters, generating a wide range of scenarios based on probabilistic distributions. This is particularly useful for modeling uncertainty and variability in real-world conditions. Complementing this, Computer Graphics-Based Simulation leverages rendering techniques to create visually realistic synthetic data, including variations in lighting, textures, and viewpoints. The combination of these methods allows for the creation of large, diverse datasets that encompass a broader spectrum of conditions than might be captured through purely deterministic simulation or real-world data collection, improving the robustness and generalization capabilities of trained AI models.
Domain randomization and domain adaptation are key techniques for improving the generalization capability of AI models trained on simulated data. Domain randomization involves varying simulation parameters – such as textures, lighting, and object geometries – during training to force the model to learn features invariant to specific simulation characteristics. This increases robustness to the discrepancies between the simulated and real environments. Domain adaptation, conversely, focuses on reducing the distribution gap after initial simulation training, often employing techniques like adversarial training or transfer learning to align the feature spaces of simulated and real-world data. Both approaches mitigate the effects of the ‘reality gap’ by either broadening the simulated experience or specifically bridging the difference between simulation and real-world observations, ultimately leading to improved performance in real-world deployments.
The Future of Intelligence: Learning Through Experience
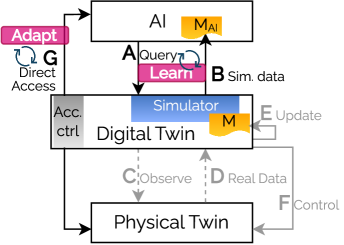
The convergence of Digital Twins and advanced simulation offers a transformative pathway for cultivating intelligent AI agents. By constructing a virtual replica of a physical system – a Digital Twin – researchers can subject these agents to a vast range of scenarios and challenges without the risks or expenses associated with real-world experimentation. This simulated environment enables AI to learn complex behaviors through trial and error, mastering tasks from intricate robotic manipulations to navigating dynamic urban landscapes. Consequently, the methodology dramatically accelerates the development process, fostering robust and adaptable AI solutions while significantly reducing the need for costly physical prototypes or potentially dangerous real-world training exercises. The approach promises to unlock innovations across diverse sectors, creating more efficient, reliable, and safe intelligent systems.
The DT4AI framework significantly streamlines the creation of intelligent systems by providing a robust platform for integrating Deep Learning and Reinforcement Learning within simulated environments. This approach allows AI agents to acquire and refine complex behaviors through repeated interaction and learning from virtual experiences, bypassing the limitations and risks associated with real-world training. By leveraging the power of simulation, developers can rapidly prototype, test, and optimize AI algorithms, dramatically reducing development time and costs. The framework’s architecture is designed to facilitate efficient data generation, model training, and performance evaluation, ultimately accelerating the deployment of sophisticated AI solutions across a broad spectrum of applications, including robotics, autonomous systems, and advanced manufacturing processes.
The development of the DT4AI framework represents a significant step toward streamlining artificial intelligence development through the integration of digital twin technology and advanced simulation. This framework details specific components – including virtual environments, sensor models, and physics engines – and provides concrete instantiations demonstrating its practical application. Critically, the DT4AI architecture is mapped to existing standardized frameworks, fostering interoperability and reducing barriers to adoption. The result is a system poised to accelerate the creation of intelligent systems, with potential impacts spanning robotics, autonomous vehicle navigation, precision healthcare solutions, and the optimization of complex manufacturing processes – ultimately enabling more efficient, reliable, and broadly applicable AI technologies.
The pursuit of robust AI agents necessitates a departure from reliance on exclusively real-world data. This article illuminates the potential of synthetic data, generated through simulation and digital twins, to mitigate data scarcity and bridge the problematic sim-to-real gap. The framework proposed, DT4AI, represents a structured approach to leveraging these technologies. Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” This rings true; simulation, while powerful, remains dependent on the fidelity of the models and the ingenuity of the data generation process. Clarity is the minimum viable kindness; a well-defined simulation is a foundational kindness to the learning agent.
What’s Next?
The pursuit of artificial intelligence via synthetic data, as this work clarifies, isn’t a shortcut – it’s a translation. A translation from the conveniently malleable world of simulation to the stubbornly resistant reality. The elegance of the DT4AI framework lies in its acknowledgement of this inherent friction, yet the true measure of success will not be in minimizing that gap, but in understanding its irreducible core. Much effort remains in defining what aspects of reality truly demand precise mirroring, and what can be gracefully abstracted away.
The field now faces a quiet reckoning. The rush to generate ever-larger datasets risks obscuring a simpler truth: data quality, specifically its relevance to the target task, will invariably outweigh sheer volume. The question isn’t merely how to create realistic simulations, but how to constrain them – to deliberately introduce imperfections and uncertainties that reflect the inherent noisiness of the real world. This demands a shift in perspective, away from striving for verisimilitude and toward embracing purposeful distortion.
Ultimately, the enduring challenge isn’t technical, but conceptual. It’s about recognizing that a perfect simulation is not the goal. The goal is an efficient simulation – one that provides just enough information to enable intelligent action, and no more. The subtraction of unnecessary detail, the ruthless pruning of complexity, that is where true progress lies.
Original article: https://arxiv.org/pdf/2602.15816.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Gold Rate Forecast
- Wuchang Fallen Feathers Save File Location on PC
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- HSR 3.7 breaks Hidden Passages, so here’s a workaround
- Solel Partners’ $29.6 Million Bet on First American: A Deep Dive into Housing’s Unseen Forces
- Crypto Chaos: Is Your Portfolio Doomed? 😱
- Macaulay Culkin Finally Returns as Kevin in ‘Home Alone’ Revival
- Where to Change Hair Color in Where Winds Meet
- Is Taylor Swift Getting Married to Travis Kelce in Rhode Island on June 13, 2026? Here’s What We Know
2026-02-18 07:48