Author: Denis Avetisyan
As data privacy regulations tighten, ensuring AI systems truly ‘forget’ specific data is paramount, and this research proposes a new economic framework to verify compliance with machine unlearning requests.
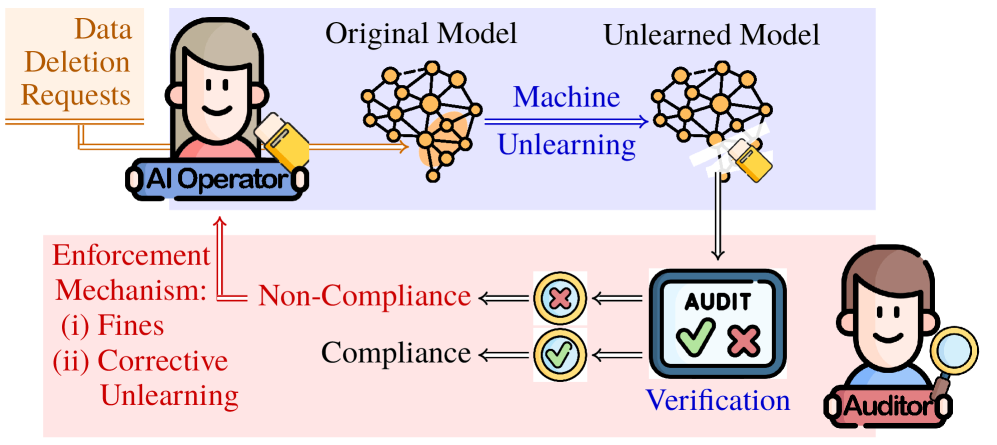
This paper details an auditing mechanism leveraging game theory to assess and improve the cost-effectiveness of certified machine unlearning under rising data deletion demands.
Despite growing legal mandates for data deletion, ensuring AI systems truly ‘forget’ personal information remains a significant challenge. This is addressed in ‘Governing AI Forgetting: Auditing for Machine Unlearning Compliance’, which introduces a novel economic framework for auditing machine unlearning (MU) – the technical process of removing data’s influence from trained models. Our analysis reveals that optimal auditing strategies may counterintuitively decrease inspection intensity as deletion requests increase, and that transparent auditing practices can enhance regulatory cost-effectiveness. How can these findings inform the development of robust and efficient AI governance mechanisms that balance data privacy with innovation?
Rewriting the Rules: The Rise of Data Rights and Machine Unlearning
Contemporary data privacy regulations, most notably the General Data Protection Regulation (GDPR), fundamentally alter the landscape of machine learning by enshrining an individual’s ‘right to be forgotten’. This legal tenet compels organizations to not merely delete personal data upon request, but to ensure its complete removal from all systems, including those powering complex machine learning models. This presents a significant challenge; traditional approaches to data removal often involve costly and time-consuming full model retraining – an impractical solution for datasets of immense scale. Consequently, systems trained on vast amounts of personal data face increasing scrutiny, demanding new methodologies that can swiftly and effectively erase the influence of specific data points without disrupting the overall model performance or incurring prohibitive computational burdens. The implications extend beyond legal compliance; failing to adequately address these ‘right to be forgotten’ requests can expose organizations to substantial penalties and erode public trust.
As machine learning models grow in complexity and are trained on ever-larger datasets, the process of updating or correcting them presents significant hurdles. Traditional model retraining-the complete rebuilding of a model from scratch with modified data-quickly becomes computationally prohibitive and time-consuming, especially when dealing with datasets measured in terabytes or petabytes. This impracticality is further exacerbated by the increasing frequency of data modification requests, stemming from corrections, updates, or, crucially, legal obligations like the ‘right to be forgotten’. The sheer scale of these datasets means that even incremental improvements to retraining algorithms offer insufficient relief, creating a pressing need for alternative methods that can efficiently address data modifications without incurring the massive costs associated with complete model reconstruction. Consequently, research has focused on developing techniques that selectively update models, minimizing computational burden while preserving accuracy and adhering to evolving data privacy regulations.
Machine unlearning presents a paradigm shift in how algorithms handle data privacy requests, moving beyond the costly and time-consuming process of complete model retraining. Instead of rebuilding a system from scratch, machine unlearning techniques aim to selectively diminish the impact of specific data points – effectively ‘forgetting’ them – without disrupting the knowledge gained from the remaining dataset. This is achieved through various methods, including approximate gradient methods and influence functions, which estimate how much a particular data point contributed to the model’s parameters and then adjust those parameters accordingly. The potential benefits are substantial, offering a scalable and efficient solution for complying with evolving data privacy regulations like GDPR and enabling more responsible and trustworthy artificial intelligence systems. Ultimately, machine unlearning strives to reconcile the demands of data privacy with the continued advancement of machine learning capabilities.
The practical necessity of effective machine unlearning extends beyond mere compliance with data privacy regulations; incomplete or inaccurate data removal presents substantial legal and reputational hazards. Should a model fail to fully excise information pertaining to a user exercising their ‘right to be forgotten’, organizations risk hefty fines and legal repercussions under frameworks like GDPR. Furthermore, even the appearance of retaining sensitive data-even if technically incorrect-can severely damage public trust and brand image. Consequently, robust verification methods are crucial to confirm that unlearning algorithms have genuinely neutralized the influence of targeted data points, preventing the re-emergence of previously removed information in model outputs and safeguarding both legal standing and consumer confidence.
Beyond Erasure: Certified Unlearning Theory and the Proof of Forgetting
Certified Unlearning Theory establishes a formal mathematical basis for verifying data removal from machine learning models. Unlike traditional methods focusing on minimizing the impact of deleted data-often assessed through loss functions-this theory aims to prove that the resulting model is statistically indistinguishable from one trained solely on the remaining data. This is achieved through techniques that bound the divergence between the original and “unlearned” models, typically expressed as a quantifiable difference in their predictive distributions. Specifically, the theory relies on establishing bounds on the influence of the deleted data, ensuring that its removal does not measurably alter the model’s behavior on unseen data. This rigorous approach moves beyond empirical observation and provides a verifiable guarantee of data erasure, crucial for regulatory compliance and privacy preservation.
Traditional machine learning model retraining and loss minimization techniques do not inherently guarantee the removal of sensitive data; a model can achieve low loss on a new dataset while still retaining information from the deleted data. Certified unlearning, conversely, establishes a formal, mathematical guarantee of data removal by demonstrating that the post-unlearning model’s output distribution is statistically indistinguishable from a model trained solely on the remaining data. This is achieved through rigorous proofs, often leveraging differential privacy principles, which quantify the maximum possible influence of the deleted data on the model’s behavior. The certification process focuses on bounding the impact of the deleted data, rather than simply minimizing loss, providing a stronger assurance of data privacy and compliance with regulations like GDPR.
Model Unlearning (MU) methods, such as Hessian-Free MU, utilize the mathematical principles of Certified Unlearning Theory to provide demonstrably verifiable data removal. These techniques don’t simply minimize the impact of deleted data on model performance-they aim to prove that the resulting model is statistically indistinguishable from a model trained without the sensitive data. This is achieved by bounding the influence of the deleted data through techniques like calculating the S singular value decomposition and applying bounds on the model’s weight updates, allowing for a quantifiable certification of unlearning rather than relying on empirical observation or heuristic approaches.
The Unlearning Certification Level (UCL) provides a standardized, quantifiable assessment of data removal effectiveness following an unlearning procedure. Represented as a numerical value – typically a probability or a statistical bound – the UCL indicates the degree to which a model is statistically indistinguishable from its state prior to training on the deleted data. This metric is determined through rigorous statistical testing, often utilizing differential privacy or related techniques, and is crucial for demonstrating compliance with data privacy regulations like GDPR and CCPA. A higher UCL signifies a more thorough unlearning process and a stronger guarantee that the removed data no longer influences the model’s behavior, offering verifiable evidence for audits and legal requirements.

Incentivizing Compliance: An Economic Auditing Framework for Data Unlearning
The Economic Auditing Framework establishes a system for ensuring adherence to data deletion requests through a combination of incentivized compliance and regulatory enforcement. This framework operates by assigning economic costs – in the form of fines – to instances of non-compliance, thereby creating a financial disincentive for failing to fulfill data subject rights. Simultaneously, the framework incorporates auditing mechanisms – varying in inspection intensity – to verify the successful execution of machine unlearning procedures and detect any instances of retained data. The resulting structure aims to align the economic interests of AI operators with the requirements of data privacy regulations, fostering proactive compliance and accountability.
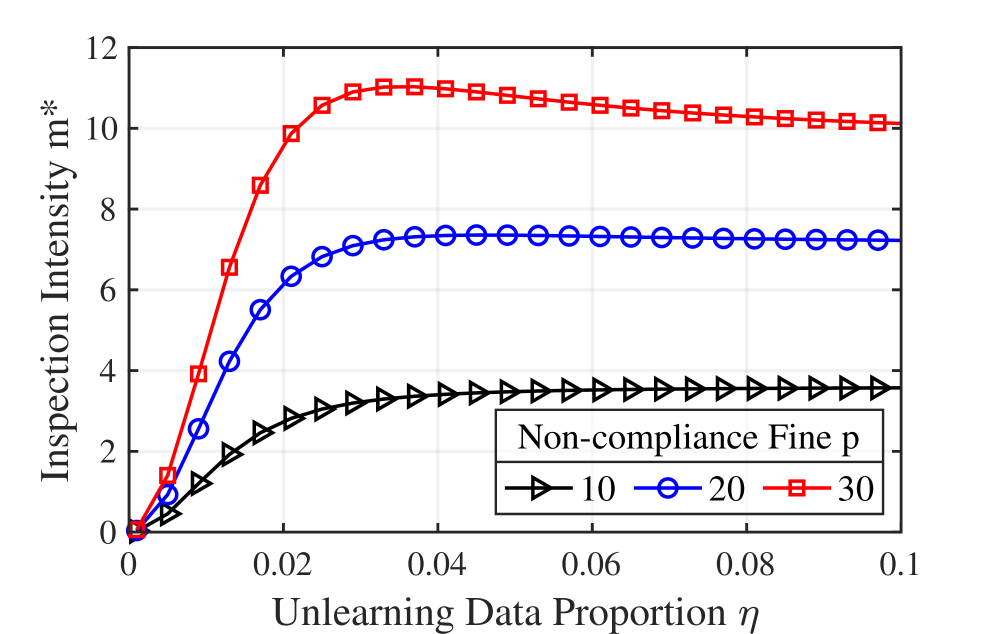
Inspection intensity, within the Economic Auditing Framework, defines the extent of effort dedicated to verifying that machine unlearning implementations have successfully and completely removed requested data. This is operationalized through a quantifiable metric representing the proportion of unlearning requests subjected to full audit – examining model parameters to confirm data erasure. Higher inspection intensity provides greater assurance of compliance but incurs increased auditing costs. Conversely, lower intensity reduces costs but elevates the risk of undetected non-compliance, potentially triggering economic penalties. The framework models the optimal inspection intensity based on factors including the cost of auditing, the magnitude of non-compliance fines, and the volume of data deletion requests, allowing for a cost-benefit analysis of verification efforts.
The Economic Auditing Framework leverages non-compliance fines as a primary deterrent against failure to fulfill data deletion requests. These fines introduce a quantifiable economic cost associated with non-compliance, thereby incentivizing AI operators to prioritize the implementation and maintenance of effective machine unlearning capabilities. The magnitude of these fines is calibrated to reflect the severity of the violation – specifically, the volume of data subject to unfulfilled deletion requests – creating direct economic pressure to adhere to data rights regulations and avoid financial penalties. This approach shifts the burden of proof regarding compliance from regulators to AI operators, fostering a proactive stance towards data subject requests and responsible AI practices.
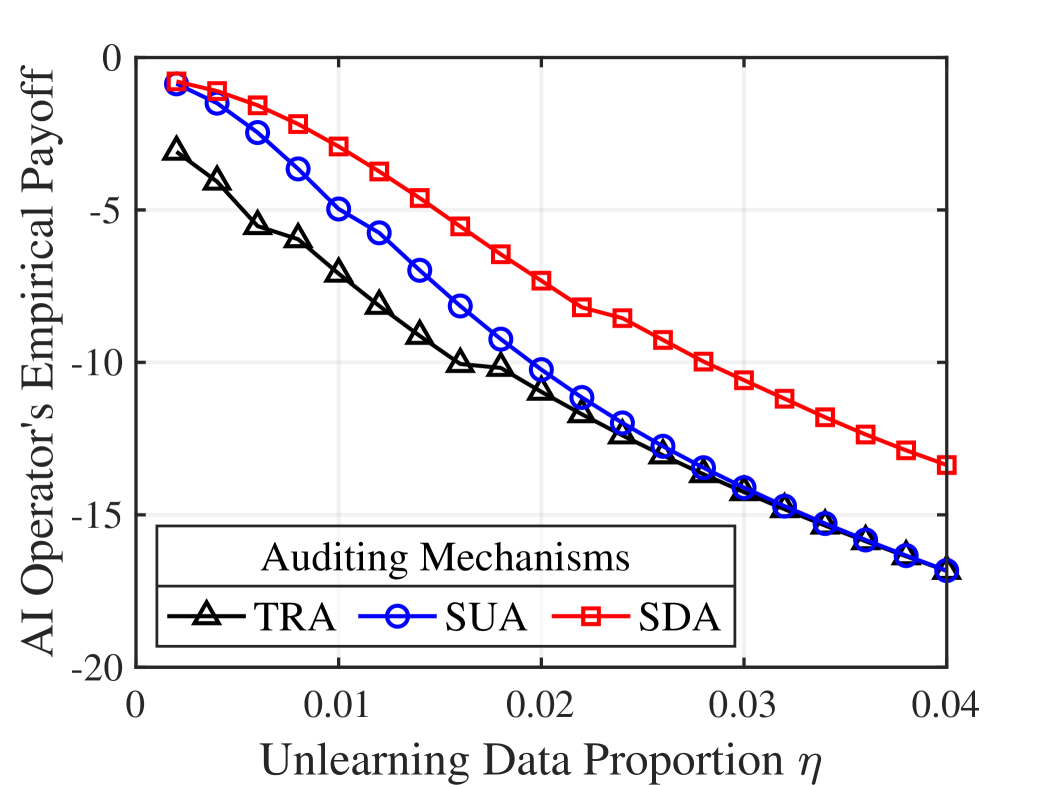
The proposed Economic Auditing Framework yields significant economic benefits through disclosed auditing practices. Evaluations demonstrate an increase in auditor payoff of up to 2549.30% and an AI operator payoff increase of up to 74.60% when compared to existing regulatory enforcement benchmarks. This improvement is directly attributable to the transparency inherent in disclosed auditing, which facilitates more efficient verification of machine unlearning and reduces the costs associated with compliance verification. These results indicate that incentivizing transparency within auditing processes can substantially enhance the effectiveness and economic viability of data rights enforcement.
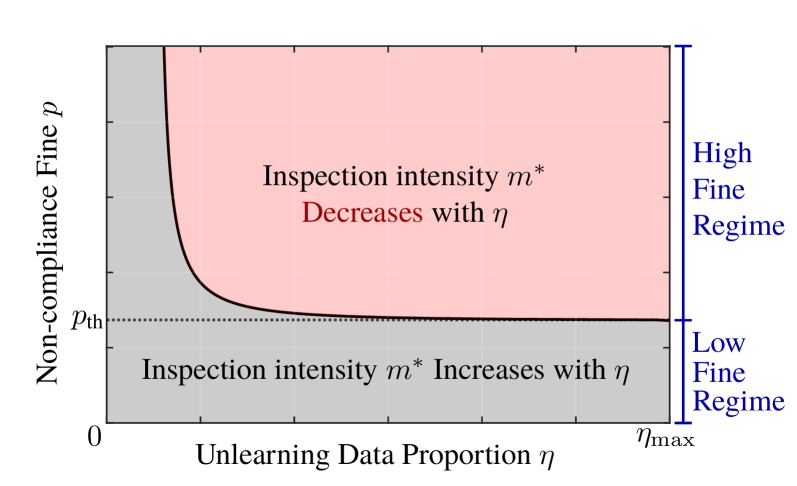
The Economic Auditing Framework demonstrates an inherent efficiency; specifically, when faced with high volumes of data deletion requests, the optimal auditing strategy involves a reduction in inspection intensity. This outcome arises from the economic model’s calculation of the cost of inspection versus the probability of undetected non-compliance. As deletion volume increases, the expected value of additional auditing diminishes, making it economically rational for the auditor to decrease the level of effort dedicated to verifying machine unlearning implementations. This adaptive strategy minimizes auditing costs without significantly increasing the risk of non-compliance, thereby optimizing the overall enforcement process.
The Economic Auditing Framework incorporates multiple auditing strategies to optimize compliance verification. Strategic Disclosed Auditing involves transparently informing AI operators of audit schedules and parameters, while Strategic Undisclosed Auditing maintains secrecy regarding audit timing and scope. The selection between these strategies, and variations within them, depends on factors such as the cost of inspection, the potential fines for non-compliance, and the AI operator’s risk aversion. Analyses within the framework demonstrate that the optimal strategy can significantly impact both auditor and operator payoffs, necessitating a tailored approach to maximize the effectiveness of regulatory enforcement and incentivize accurate machine unlearning.
The Regulatory Horizon: Navigating the EU AI Act and Responsible AI Practices
The European Union’s AI Act marks a pivotal moment in the governance of artificial intelligence, establishing a comprehensive legal framework designed to foster innovation while mitigating potential risks. This legislation doesn’t simply address the technology itself, but crucially defines the responsibilities of those who develop, deploy, and operate AI systems – introducing the concept of the ‘AI operator’ as a key accountable entity. By categorizing AI applications based on risk levels – from minimal to unacceptable – the Act imposes proportionate obligations, demanding greater transparency and human oversight for high-risk systems impacting areas like critical infrastructure, employment, and fundamental rights. This proactive approach aims to ensure that AI technologies are developed and used ethically, safely, and in a manner that respects European values, ultimately building public trust and facilitating the responsible adoption of AI across society.
As data privacy regulations intensify, particularly with the advent of legislation like the EU AI Act, the ability for artificial intelligence systems to ‘forget’ specific data points is no longer a theoretical consideration but a practical necessity. Machine unlearning, the process of selectively removing the influence of particular data from a trained model, is emerging as a critical compliance mechanism. This isn’t simply deletion; it requires sophisticated techniques to ensure the model’s performance on other data isn’t compromised and that the ‘forgotten’ information truly ceases to affect future outputs. The demand for verifiable unlearning capabilities stems directly from individuals’ rights to erasure and data portability, necessitating AI systems that can demonstrably respect these rights without requiring complete retraining – a costly and time-consuming process. Consequently, the development and standardization of robust machine unlearning techniques are vital for building trustworthy AI and navigating the evolving legal landscape.
While established risk-based auditing provides a foundational layer of oversight for artificial intelligence systems, its limitations become apparent when evaluating the complexities of Machine Unlearning (MU). Traditional methods often focus on overall system performance and data accuracy, failing to adequately probe the granular level required to verify that specific data points have been genuinely and completely removed from a model’s memory. The nuances of MU-including potential ‘residual effects’ where traces of data remain influencing model outputs, or the uneven effectiveness of unlearning across different data subsets-demand more sophisticated auditing techniques. These include developing novel metrics beyond simple accuracy scores, employing differential privacy assessments to quantify unlearning guarantees, and utilizing techniques like influence functions to trace the impact of individual data points on model behavior – ultimately necessitating a shift toward verifiable, data-centric auditing frameworks that can rigorously validate the completeness and integrity of the unlearning process.
The burgeoning field of Machine Unlearning (MU) is rapidly transitioning from a theoretical concept to a practical necessity, particularly as artificial intelligence systems become increasingly integrated into daily life and subject to stringent regulations like the EU AI Act. True adoption of MU, however, demands sustained investigation to navigate an evolving landscape of artificial intelligence challenges. Current MU techniques, while promising, face limitations regarding scalability, efficiency, and guarantees of complete unlearning. Future research must prioritize developing methods that are robust against adversarial attacks, applicable to diverse model architectures – including large language models – and aligned with principles of data privacy and responsible AI. Addressing these concerns isn’t merely a technical exercise; it’s a crucial step towards fostering public trust and ensuring that AI systems remain beneficial and accountable throughout their lifecycle.

Engineering Forgetting: Building Robust and Unlearnable Systems for the Future
Multinomial Logistic Regression offers a surprisingly effective starting point for investigations into Model Unlearning (MU) techniques, largely due to its simplicity and interpretability. Researchers frequently employ it as a baseline against which more complex MU methods can be rigorously compared; its well-understood behavior allows for clear identification of improvements or regressions introduced by novel unlearning strategies. This approach enables precise measurement of an unlearning method’s ability to effectively remove traces of specific data points without significantly degrading overall model performance on retained data. Furthermore, the relative computational efficiency of training and evaluating Multinomial Logistic Regression facilitates rapid prototyping and experimentation, accelerating the development cycle for new MU algorithms and fostering a more comprehensive understanding of their underlying mechanisms.
Regularization techniques, prominently including L2 Regularization, contribute significantly to building machine learning models that are both resilient and capable of ‘forgetting’ specific data points. L2 Regularization achieves this by adding a penalty term to the model’s loss function, proportional to the square of the magnitude of the model’s weights \lambda \sum_{i=1}^{n} w_i^2 . This discourages excessively large weights, preventing the model from overfitting to the training data and thereby improving its generalization performance on unseen examples. Crucially, this weight decay also makes the model less sensitive to individual data points; altering or removing specific training instances has a diminished impact on the overall model parameters, facilitating the ‘unlearning’ process and enhancing robustness against adversarial attacks or data poisoning. Consequently, incorporating regularization isn’t merely about improving accuracy, but about engineering systems designed for adaptability and responsible data handling.
The selection of a loss function significantly impacts a model’s ability to not only learn effectively during initial training but also to completely and efficiently ‘unlearn’ specific data points or tasks. Cross-Entropy Loss, commonly employed in classification problems, proves particularly valuable in this context because it directly optimizes the model to minimize the difference between predicted and actual probability distributions. This characteristic is vital for ensuring that when tasked with unlearning, the model doesn’t simply suppress the learned information-it actively adjusts its parameters to reflect a state as if the data were never encountered. Consequently, models trained with appropriate loss functions like Cross-Entropy Loss demonstrate a superior capacity for both achieving high performance and exhibiting true unlearnability, minimizing residual traces of sensitive or unwanted data and bolstering the development of more responsible and adaptable artificial intelligence systems.
The field of Machine Unlearning (MU) demands sustained investigation to navigate an evolving landscape of artificial intelligence challenges. As models become increasingly integrated into critical infrastructure – from healthcare and finance to criminal justice – the need to selectively erase specific data points without compromising overall performance grows exponentially. Current MU techniques, while promising, face limitations regarding scalability, efficiency, and guarantees of complete unlearning. Future research must prioritize developing methods that are robust against adversarial attacks, applicable to diverse model architectures – including large language models – and aligned with principles of data privacy and responsible AI. Addressing these concerns isn’t merely a technical exercise; it’s a crucial step towards fostering public trust and ensuring that AI systems remain beneficial and accountable throughout their lifecycle.
The pursuit of verifiable machine unlearning, as detailed in the paper, mirrors a fundamental challenge in any complex system: ensuring adherence to stated parameters. It’s not enough to claim data has been removed; one must prove it. This echoes G.H. Hardy’s sentiment: “A mathematician, like a painter or a poet, is a maker of patterns.” The paper essentially attempts to construct a pattern – an economic audit – to verify the ‘pattern’ of data deletion. The study demonstrates that increased transparency, by disclosing auditing processes, can surprisingly reduce overall costs, suggesting that a system designed for rigorous testing-akin to Hardy’s mathematical proofs-can become more efficient through scrutiny. The core concept of auditing intensity scaling with data deletion requests highlights the constant need to re-evaluate and refine the ‘pattern’ to maintain its integrity.
What’s Next?
The proposition that increased regulatory transparency actually reduces auditing costs seems, at first glance, counterintuitive. One is compelled to ask: if demonstrating unlearning becomes cheaper through disclosure, does that not incentivize precisely the behavior regulators seek to prevent-a race to the bottom in verifiable data deletion? The framework highlights a curious dependency: effective unlearning auditing isn’t simply about verifying deletion, but about strategically managing the cost of that verification. It begs the question of whether “certified unlearning” is, in fact, a stable equilibrium, or merely a locally optimal solution prone to adversarial exploitation.
Current approaches largely treat unlearning requests as isolated events. Yet, a surge in deletion requests-driven by increasingly stringent privacy regulations or heightened public awareness-could fundamentally alter the cost calculus for both data holders and auditors. The model suggests diminishing returns on inspection intensity, but does not address the potential for correlated requests – coordinated attempts to destabilize a model by systematically removing key training data. Is the optimal audit strategy one of constant vigilance, or periodic, deep dives designed to detect patterns of malicious deletion?
Ultimately, this work frames unlearning not as a purely technical problem, but as a game – one where the rules are still being written. Future research should investigate the impact of imperfect information – both on the part of the auditor and the data holder – and explore the potential for decentralized auditing mechanisms. Perhaps the true signal isn’t achieving perfect unlearning, but building a system resilient enough to function even when – or especially when – data is demonstrably, and deliberately, incomplete.
Original article: https://arxiv.org/pdf/2602.14553.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Wuchang Fallen Feathers Save File Location on PC
- Gold Rate Forecast
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- All weapons in Wuchang Fallen Feathers
- Where to Change Hair Color in Where Winds Meet
- Top 15 Celebrities in Music Videos
- Here Are the Best TV Shows to Stream this Weekend on Paramount+, Including ‘48 Hours’
- Top 15 Movie Black-Haired Beauties, Ranked
- Best Video Games Based On Tabletop Games
2026-02-17 18:13