Author: Denis Avetisyan
A new framework explicitly models uncertainty in generative recommendation to create more robust, trustworthy, and risk-aware suggestions.
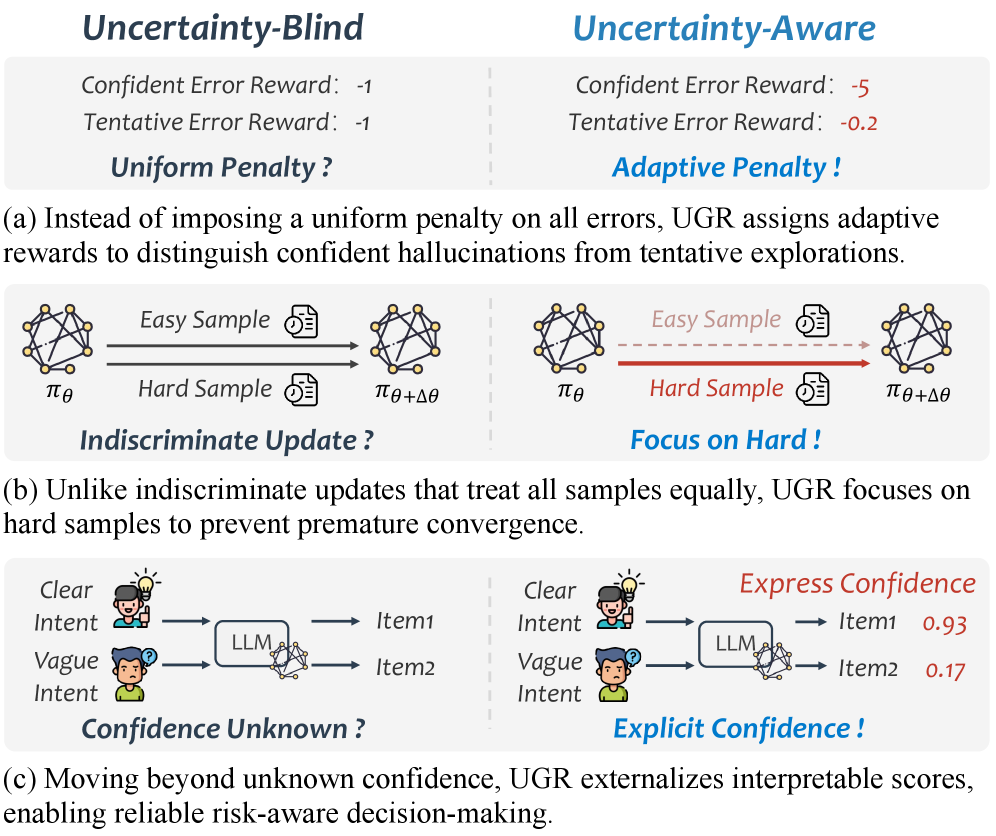
This paper introduces Uncertainty-aware Generative Recommendation (UGR), leveraging uncertainty modeling and sequence generation to improve preference alignment and confidence estimation in recommendation systems.
Despite the recent success of generative recommendation systems, a critical limitation remains: their inherent blindness to uncertainty in predictions. This paper introduces Uncertainty-aware Generative Recommendation (UGR), a novel framework that addresses this issue by explicitly modeling and leveraging confidence as a core optimization signal. UGR synergistically combines weighted rewards, difficulty-aware dynamics, and explicit confidence alignment to not only improve recommendation performance and training stability, but also to enable quantifiable risk assessment. Could incorporating model uncertainty fundamentally reshape the landscape of trustworthy and reliable recommender systems?
Decoding Preference: Beyond Simple Ranking
Conventional recommender systems often rely on discriminative ranking, a process that prioritizes predicting whether a user will interact with an item, rather than truly understanding the nuances of their tastes. This approach, while effective for suggesting popular items, frequently falls short in capturing the complexity of individual preferences and often results in predictable, homogenous recommendations. Consequently, users are often presented with content similar to what they’ve already consumed, limiting exposure to potentially interesting, yet unexpected, discoveries-a phenomenon known as limited serendipity. These systems excel at identifying items a user is likely to approve of, but struggle to proactively suggest items a user might love – particularly those outside their established patterns – hindering genuine personalization and potentially stifling exploration of new interests.
Generative recommendation systems represent a significant departure from traditional approaches by conceptualizing the recommendation process not as predicting a ranking, but as generating a sequence of items tailored to a user’s preferences. This reframing allows these systems to move beyond simply identifying the most relevant items and instead construct entire personalized experiences, much like composing a story. By treating recommendations as a conditional sequence generation task – where the system predicts the next item given a user’s history – it unlocks the potential for greater diversity, novelty, and coherence in suggested content. The system doesn’t just select; it creates a list, potentially weaving in unexpected but relevant items that a ranking-based system might overlook, ultimately leading to more engaging and satisfying user interactions.
The advent of generative recommendation systems marks a significant departure from traditional methods, harnessing the capabilities of Large Language Models (LLMs) to construct remarkably diverse and engaging recommendation lists. Rather than simply predicting which items a user might prefer based on past behavior, these models generate sequences of recommendations, mimicking the natural flow of human storytelling or conversation. This approach allows for the introduction of items that are not necessarily the most statistically similar to a user’s history, fostering serendipity and discovery. By framing recommendation as a generative task, LLMs can leverage their understanding of language and context to create nuanced and personalized lists, moving beyond simple ranking to offer experiences that are more creative, surprising, and ultimately, more satisfying for the user. The result is a shift from predicting preference to crafting an experience, potentially redefining how individuals interact with information and products.
The Alignment Problem: Sculpting Preferences
Preference alignment is the foundational principle in generative recommendation systems, directly impacting user engagement and satisfaction. Unlike traditional methods that prioritize popularity or broad appeal, preference alignment focuses on tailoring recommendations to the specific, nuanced tastes of each individual user. This is achieved by modeling user preferences – encompassing explicit ratings, implicit behaviors like viewing history, and contextual factors – and utilizing these models to generate recommendations that maximize the likelihood of a positive user response. Effective preference alignment necessitates a deep understanding of individual user tastes, requiring algorithms capable of capturing complex patterns and adapting to evolving preferences over time. Failure to adequately align with user preferences results in irrelevant or undesirable recommendations, leading to decreased user trust and reduced system effectiveness.
Reinforcement Learning (RL) approaches to recommendation leverage user interactions – clicks, purchases, time spent – as reward signals to train recommendation policies. This allows algorithms to dynamically optimize recommendations based on observed user behavior and maximize long-term engagement. However, standard RL algorithms can exhibit instability in recommendation systems due to several factors. These include the non-stationary nature of user preferences, the large action space of potential recommendations, and the delayed reward problem – where the full impact of a recommendation isn’t immediately apparent. Instability manifests as oscillations in the learned policy, leading to unpredictable and potentially irrelevant recommendations. Addressing these issues requires techniques to stabilize the learning process and ensure the policy converges to an optimal, user-centric solution.
Group Relative Policy Optimization (GRPO) addresses the instability often encountered when applying reinforcement learning to generative recommendation systems. GRPO achieves this by optimizing policies relative to a group of previously successful policies, rather than attempting absolute optimization. This relative approach constrains policy updates, preventing drastic shifts that can lead to recommendation instability and poor user experience. Specifically, GRPO maintains a buffer of past policies and encourages new policies to perform well compared to this buffer, ensuring a more conservative and stable learning process. This method has demonstrated improved convergence and robustness in various generative recommendation tasks, consistently outperforming standard reinforcement learning algorithms in scenarios with sparse or delayed user feedback.
Beyond Binary: Refining the Reward Signal
Binary reward functions, while straightforward to implement, often fail to adequately represent the complexities of user preference. These functions typically assign a reward of 1 for correct or desired outcomes and 0 for all others, providing limited signal for optimization. This lack of granularity hinders the model’s ability to distinguish between varying degrees of relevance or quality, leading to suboptimal recommendations that may satisfy basic criteria but fail to fully align with nuanced user needs. Consequently, models trained solely on binary rewards can struggle to generalize effectively and may exhibit limited performance in scenarios requiring more sophisticated evaluation metrics beyond simple correctness.
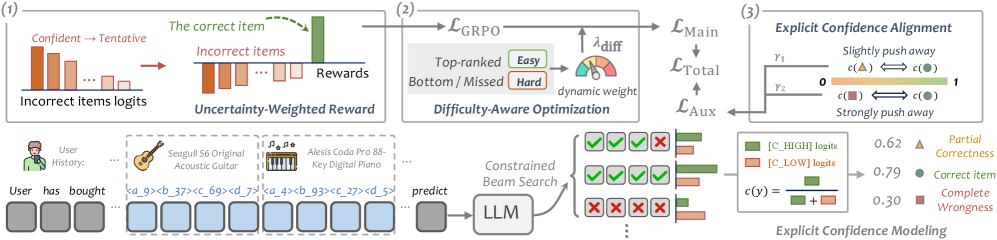
Ranking-Based Reward and Uncertainty-Weighted Reward systems move beyond binary penalties by incorporating the relative quality of generated sequences and the model’s confidence in its predictions. Ranking-Based Reward assigns penalties based on the position of a generated sequence within a ranked list of alternatives, effectively differentiating between marginally incorrect and severely flawed outputs. Uncertainty-Weighted Reward further refines this by modulating penalties according to the model’s predictive uncertainty; higher confidence, incorrect predictions incur larger penalties than low-confidence errors. This nuanced approach addresses the limitations of simple reward functions, which often fail to distinguish between degrees of incorrectness and can lead to suboptimal training signals, particularly in complex generation tasks.
Methods employing increased penalties for confident, yet inaccurate, predictions – termed hallucinations – encourage model exploration during training and result in higher-quality generated sequences. This approach is particularly effective when integrated with search algorithms such as Beam Search, which leverages the refined reward signal to identify and prioritize more reliable outputs. The UGR (Uncertainty-Guided Reward) framework, implementing this principle, has demonstrated state-of-the-art performance across several benchmarks, exhibiting improved training stability and enhanced capacity for risk-aware decision-making compared to existing methodologies.
Breaking the Echo Chamber: Diversity and Efficiency
Generative recommendation systems, while promising personalized suggestions, frequently encounter a challenge known as candidate collapse. This phenomenon describes the undesirable tendency of these models to progressively narrow the diversity of items presented to users, often favoring a small, highly-rated subset. As the model generates recommendations, it reinforces its existing biases, leading to a feedback loop where less popular, but potentially relevant, items are systematically excluded. This not only limits user discovery but also reduces the overall effectiveness of the system, as it fails to expose users to the full breadth of available options and can result in a homogenized and predictable experience. Over time, candidate collapse diminishes the value of the recommendation system, hindering its ability to truly personalize suggestions and satisfy evolving user preferences.
The challenge of representing complex items within a generative recommendation system is addressed through the innovative use of Semantic IDs (SIDs). Rather than treating items as continuous vectors, this approach transforms each item into a discrete token – a fundamental unit for sequence generation, much like words in natural language processing. By assigning unique SIDs, the model can leverage the strengths of Large Language Models (LLMs) – architectures inherently designed to process and generate sequences of discrete tokens. This tokenization allows the recommendation process to be framed as a sequence prediction task, where the model predicts the next item (SID) in a user’s potential interaction sequence. Consequently, the system benefits from the LLM’s ability to capture intricate relationships between items and generate diverse, contextually relevant recommendations, overcoming limitations inherent in traditional embedding-based approaches.
Large Language Models demonstrate substantial potential in recommendation systems, yet their full adaptation often requires extensive computational resources. Parameter-efficient fine-tuning techniques, such as Low-Rank Adaptation (LoRA), circumvent this limitation by freezing the pre-trained model weights and introducing a smaller number of trainable parameters. This approach dramatically reduces the computational cost and storage requirements associated with adapting these models to specific recommendation tasks, enabling rapid experimentation and deployment. By focusing training on these low-rank matrices, LoRA achieves performance comparable to full fine-tuning, while significantly accelerating the adaptation process and making it feasible to personalize recommendations across diverse user bases and item catalogs. The efficiency gained allows for more iterative refinement of the recommendation engine, ultimately improving its relevance and accuracy.
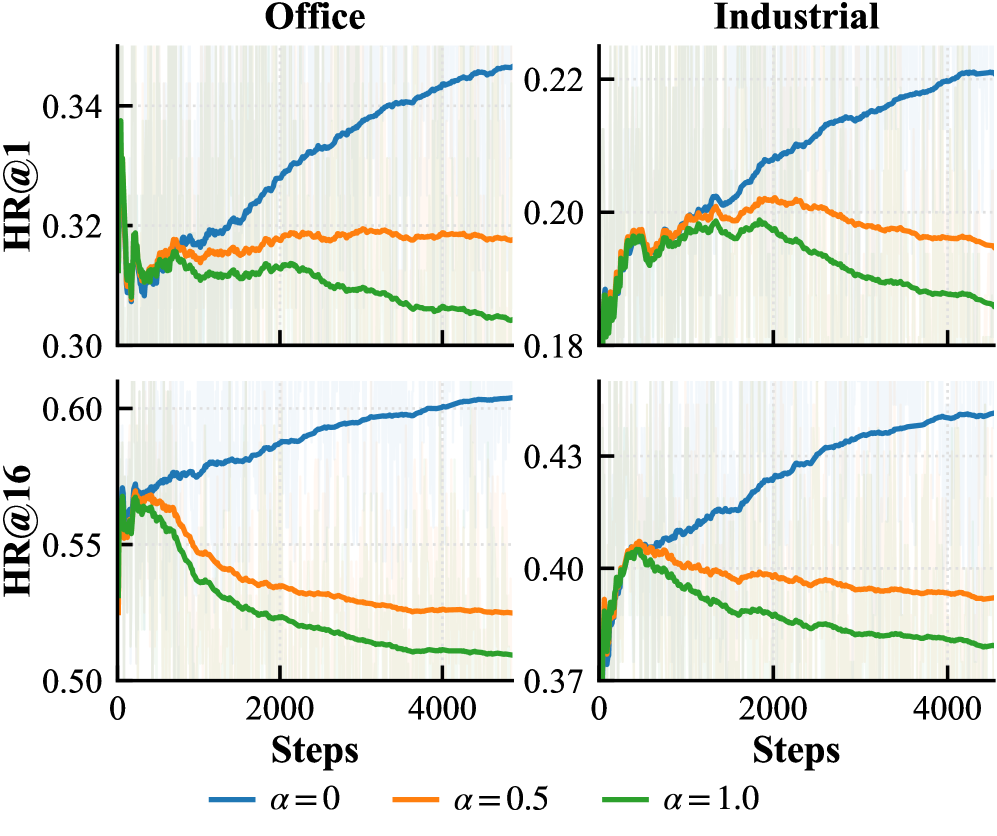
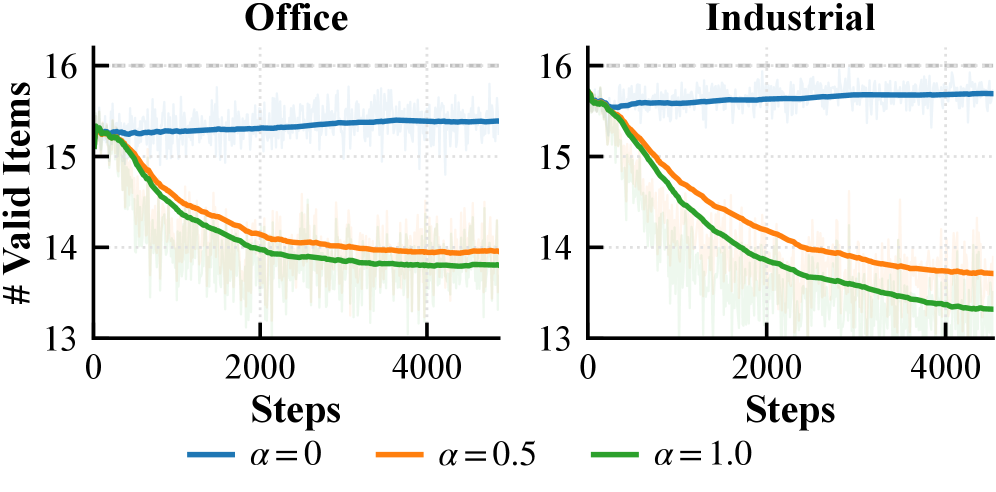
A novel optimization framework, integrating difficulty-awareness with Beam Search, demonstrably enhances recommendation search efficiency and accuracy. Evaluations across the Office, Industrial, and Yelp datasets reveal a significant improvement in Hit Ratio@1, indicating a greater likelihood of relevant recommendations being presented to users. Crucially, this framework maintains stable candidate diversity – measured by the average number of unique items generated – effectively preventing the phenomenon of candidate collapse where recommendations become increasingly homogenous. In contrast, conventional search methods exhibited a rapid decline in diversity alongside diminishing performance, suggesting the difficulty-aware approach offers a robust solution for both relevance and variety in generative recommendation systems.
The pursuit of robust generative recommendation, as detailed in this work, echoes a fundamental tenet of system understanding: probing boundaries. This research, with its focus on explicitly modeling uncertainty, doesn’t simply predict preferences; it actively assesses the confidence behind those predictions, acknowledging the inherent ambiguity in user behavior. As Brian Kernighan observed, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” Similarly, a recommendation system that fails to account for its own uncertainty is built on a cleverness that ultimately undermines its trustworthiness. The framework’s capacity to align preferences while quantifying confidence represents a step towards systems that are not only intelligent but also reliably self-aware.
Beyond the Horizon
The introduction of Uncertainty-aware Generative Recommendation (UGR) does not, as such, solve the riddle of preference. Instead, it meticulously charts the shadows – the areas where a system’s confidence falters. This is a crucial, and frankly refreshing, shift. The field has long fixated on generating plausible sequences; UGR acknowledges that knowing what a system doesn’t know is often more valuable than a confident, but potentially brittle, prediction. The architecture, however, begs further disruption. Current approaches largely treat uncertainty as a scalar; future iterations should explore its multi-dimensional nature, perhaps reflecting varying degrees of doubt across different aspects of a recommendation.
A key limitation lies in the reliance on current confidence estimation techniques. These methods, while improving, remain fundamentally post-hoc – measuring uncertainty after a prediction is made. A more radical approach would involve injecting controlled “noise” into the generative process itself, actively probing the model’s robustness and learning to anticipate failure modes. This echoes the scientific method: stress the system to reveal its limits.
Ultimately, the true test of UGR – and the broader field of generative recommendation – will not be its ability to predict what someone wants, but its capacity to gracefully navigate the inherent unpredictability of human desire. The system should not aim to eliminate uncertainty, but to acknowledge it, quantify it, and – perhaps most importantly – learn from it. The goal isn’t a perfect mirror, but a resilient one, capable of withstanding the inevitable distortions of reality.
Original article: https://arxiv.org/pdf/2602.11719.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Gold Rate Forecast
- Here Are the Best TV Shows to Stream this Weekend on Paramount+, Including ‘48 Hours’
- Top 15 Celebrities in Music Videos
- Top 20 Extremely Short Anime Series
- Where to Change Hair Color in Where Winds Meet
- 20 Films Where the Opening Credits Play Over a Single Continuous Shot
- Top gainers and losers
- 50 Serial Killer Movies That Will Keep You Up All Night
- All weapons in Wuchang Fallen Feathers
2026-02-16 05:06