Author: Denis Avetisyan
New research reveals that the attention layers within large language models are surprisingly effective at retrieving relevant information from lengthy documents, offering a novel approach to knowledge retrieval.
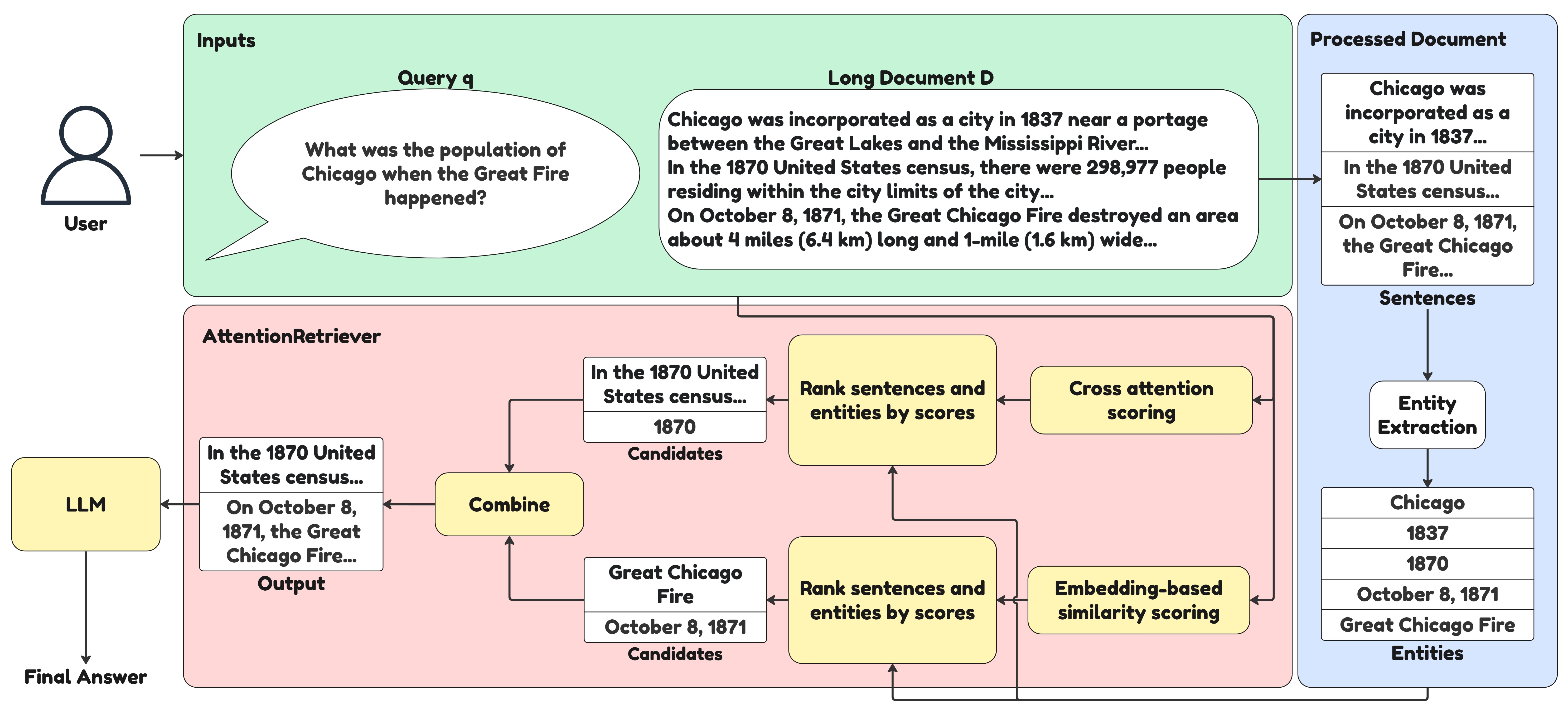
AttentionRetriever leverages attention mechanisms and entity graphs to improve the accuracy and efficiency of long document retrieval for retrieval-augmented generation tasks.
Despite the success of retrieval-augmented generation (RAG) for processing long documents, existing retrieval models struggle with context-awareness, causal dependencies, and defining appropriate retrieval scope. This paper introduces ‘AttentionRetriever: Attention Layers are Secretly Long Document Retrievers’, a novel approach that surprisingly reveals the inherent long document retrieval capabilities within the attention mechanisms of pretrained language models. By combining attention-based embeddings with entity-based retrieval, AttentionRetriever significantly outperforms existing methods on long document retrieval datasets while maintaining comparable efficiency. Could this work redefine our understanding of attention and unlock even more efficient methods for knowledge retrieval within large language models?
Decoding the Lost Signal: Why Long Documents Confuse Language Models
Despite their remarkable capabilities, Large Language Models frequently exhibit diminished performance when processing information positioned within lengthy documents, a challenge commonly referred to as the ‘Lost in the Middle’ problem. This isn’t a matter of factual inaccuracy, but rather a decline in the model’s ability to effectively utilize information that isn’t situated near the beginning or end of the text. Research suggests that LLMs tend to prioritize information presented at the edges of a document, potentially due to architectural biases or the way training data is structured. Consequently, crucial details and arguments embedded within the central portions of long-form content can be overlooked or underweighted, hindering comprehensive understanding and accurate knowledge extraction. This limitation poses a significant obstacle for applications requiring in-depth analysis of extensive reports, legal documents, or scientific literature.
The difficulty large language models experience with lengthy documents arises from a fundamental challenge: preserving contextual relevance as the sequence of information extends. While adept at processing shorter texts, these models struggle to maintain a consistent understanding of earlier content when analyzing extended passages, leading to a degradation in performance. This isn’t simply a matter of computational limits, but a core issue in how the models internally represent and access information; crucial details embedded within the middle sections of long documents can become obscured or lose their significance as the model focuses on more recent input. Consequently, complex reasoning and accurate knowledge extraction become increasingly difficult, as the model’s ability to connect distant concepts and draw informed conclusions is compromised by this fading contextual awareness.
Conventional methods for processing lengthy documents frequently resort to techniques like truncation – simply cutting off portions of the text – or employing sliding windows that analyze only limited segments at a time. While computationally efficient, these approaches inevitably discard potentially critical information, significantly hindering performance on tasks demanding a comprehensive understanding of the entire document. This limitation becomes particularly apparent when contrasted with systems like AttentionRetriever, engineered to excel with datasets containing documents of substantially greater length than those typically used to evaluate long-document retrieval capabilities; AttentionRetriever’s architecture is specifically designed to retain crucial context even across extensive texts, offering a more robust solution for complex information extraction and reasoning.
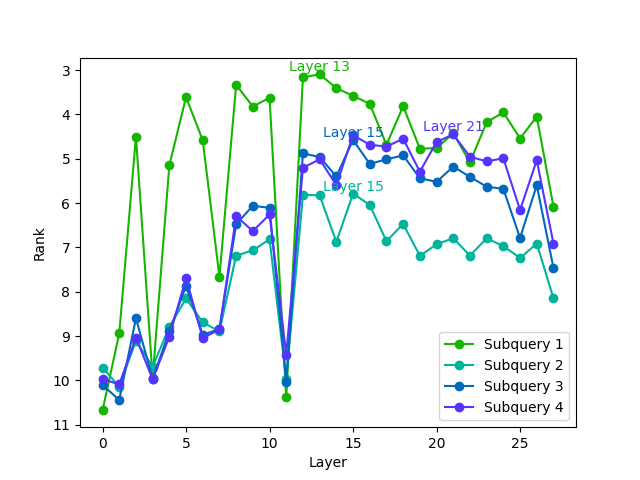
AttentionRetriever: Reclaiming Context in a Sea of Information
AttentionRetriever addresses the ‘Lost in the Middle’ problem – the tendency of retrieval models to prioritize information at the beginning and end of long documents while neglecting content in the central sections – through a novel architecture combining attention mechanisms and entity-based retrieval. Traditional retrieval methods often fail to adequately contextualize information within lengthy texts, leading to decreased accuracy for relevant passages located within the document’s core. AttentionRetriever mitigates this by explicitly modeling relationships between text chunks using an Entity Graph, enabling the model to focus on critical entities and their connections, and improving the identification of relevant information regardless of its position within the document. This approach contrasts with methods reliant solely on positional encoding or simple keyword matching, which are demonstrably less effective at maintaining context across extended text.
AttentionRetriever employs an Entity Graph to establish relationships between text chunks via identified entities, thereby expanding the contextual understanding beyond immediate adjacency. This graph-based approach allows the model to connect semantically related information across longer documents, addressing limitations in traditional retrieval methods. Benchmarking demonstrates that AttentionRetriever achieves superior performance on single-document, long-document retrieval tasks when compared to state-of-the-art sparse retrieval techniques and dense retrieval models, indicating improved accuracy in identifying relevant content within extensive textual data.
AttentionRetriever achieves effective long document retrieval by prioritizing entity relationships and employing embedding-based similarity calculations. This approach allows the model to identify contextual dependencies between text segments, improving the precision of information retrieval without sacrificing speed. Performance benchmarks demonstrate that AttentionRetriever’s processing time is comparable to that of large dense retrieval models, including GTE, Qwen3, and GritLM, while maintaining competitive accuracy on tasks requiring the analysis of extended text passages. The model establishes connections between entities within the document, enabling it to capture relevant information that may not be immediately apparent through keyword matching or sequential analysis.
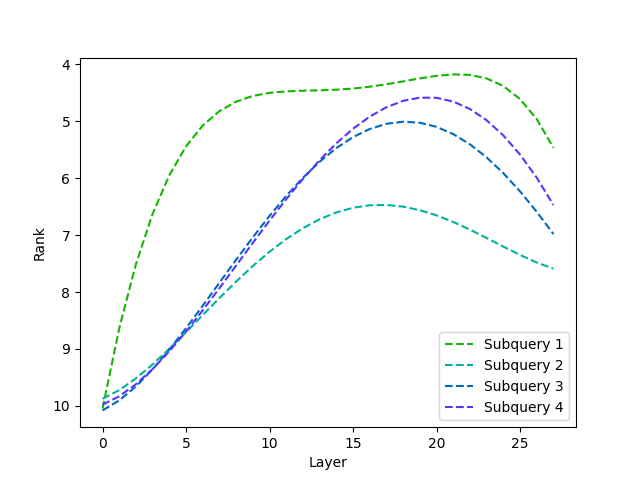
From Retrieval to Reasoning: Unlocking Causal Chains
AttentionRetriever facilitates causal reasoning by moving beyond simple information retrieval to actively identify and articulate intermediate answers within source documents. This is achieved through a process of concept linking, where the model establishes relationships between disparate pieces of information to build a cohesive understanding of the context surrounding a query. Rather than solely focusing on keyword matches, AttentionRetriever analyzes semantic connections to pinpoint relevant concepts and their dependencies, allowing it to synthesize information and present a more complete and logically structured response. This capability is crucial for tasks requiring the integration of multiple facts and the understanding of how events or ideas relate to one another within a given document.
AttentionRetriever mitigates the limitations of keyword-based retrieval systems by actively identifying background information pertinent to a query, even in the absence of direct keyword matches. This is achieved through a process of semantic understanding that allows the model to discern the contextual relevance of document passages. Unlike traditional methods that prioritize lexical overlap, AttentionRetriever focuses on the underlying meaning of the query and the document content, enabling the retrieval of implicitly related information. This capability is critical for addressing queries that require broader context or assume a degree of pre-existing knowledge, improving the LLM’s ability to formulate accurate and complete responses.
AttentionRetriever addresses causal dependency by enabling Large Language Models (LLMs) to synthesize information distributed across a document, rather than relying solely on directly stated answers. This is achieved through the identification of intermediary reasoning steps and the correlation of conceptually linked data points, even if those points lack explicit keyword connections. Consequently, LLMs utilizing AttentionRetriever demonstrate improved performance on complex question answering and tasks requiring nuanced comprehension, as the model facilitates the integration of disparate information necessary for accurate and complete responses. This capability is particularly valuable when a query’s answer isn’t immediately apparent and relies on inferential reasoning based on multiple contextual factors within the source document.
Beyond Information Access: Forging a More Powerful Generative Framework
AttentionRetriever enhances Retrieval-Augmented Generation (RAG) systems by fundamentally altering how large language models (LLMs) access and utilize external knowledge. Traditional RAG approaches often rely on retrieving a fixed number of documents, potentially missing crucial information or introducing irrelevant context. AttentionRetriever, however, dynamically weights and aggregates information from multiple retrieved documents, creating a more nuanced and relevant knowledge base for the LLM. This isn’t simply about providing more information; it’s about delivering the most pertinent information, allowing the LLM to focus its generative power on creating higher-quality, more accurate, and contextually appropriate text. The model achieves this by learning to attend to the most valuable segments within the retrieved documents, effectively filtering noise and amplifying signals, thus strengthening the connection between the LLM and its external knowledge source.
Retrieval-Augmented Generation (RAG) systems gain considerable enhancements when integrated with AttentionRetriever, yielding text that is demonstrably more refined and logically structured. This improvement arises from a synergistic effect: dense retrieval models efficiently pinpoint the most pertinent information from vast datasets, and the Large Language Model (LLM) leverages this focused knowledge to construct responses. Rather than relying solely on its pre-existing parameters, the LLM is actively informed by external, verified data, mitigating the risk of hallucination and bolstering factual accuracy. The resulting text exhibits not only greater coherence, maintaining a consistent and understandable flow, but also a richer depth of information, allowing for nuanced and comprehensive answers – a significant leap beyond conventional generative models.
The limitations of Large Language Models often stem from their fixed context windows, hindering their ability to effectively process extensive documents. AttentionRetriever addresses this challenge through ‘Context Length Extension’, a technique that enables LLMs to analyze documents far exceeding their typical input capacity. This extended processing capability isn’t simply about accommodating more text; it fundamentally unlocks new avenues for long-form content creation, such as synthesizing comprehensive reports from lengthy research papers, generating detailed summaries of legal documents, or even crafting cohesive narratives from extensive historical archives. By effectively expanding the scope of information an LLM can consider at once, AttentionRetriever facilitates a deeper understanding and more nuanced generation of complex, information-rich content.
The pursuit of efficient long document retrieval, as demonstrated by AttentionRetriever, isn’t merely about optimizing existing systems, but fundamentally questioning how information is located. One might consider this akin to peeling back layers of an onion-or, as Carl Friedrich Gauss once stated, “I would rather explain my errors than boast of my discoveries.” The paper’s innovative use of attention mechanisms, treating them not just as weighting tools but as implicit retrieval signals, embodies this spirit. It suggests that what appears as a limitation – the computational cost of attention – could, in fact, be a rich source of information, if approached with a willingness to dismantle assumptions and observe the resulting patterns. The exploration of entity graphs further reinforces this concept, revealing hidden connections often overlooked in traditional methods.
What Breaks Down Next?
The premise of AttentionRetriever-that attention mechanisms are, at their core, latent retrieval systems-is elegantly simple, almost to the point of being unsettling. If true, it begs the question: what happens when one deliberately misaligns the attention ‘lens’? Current evaluations focus on optimizing within the existing framework. A worthwhile, if disruptive, study would explore the consequences of introducing controlled ‘noise’ into the attention weights-forcing the system to retrieve based on spurious correlations. Does this reveal the true limits of attention, or merely expose the brittleness of the training data?
Furthermore, the reliance on entity graphs, while effective, feels like a temporary scaffolding. The system currently needs a pre-defined knowledge base. What if the retrieval process could dynamically construct these graphs from the document itself, creating a self-referential loop? This pushes the boundary between knowledge representation and retrieval, potentially leading to models that ‘understand’ documents not as static text, but as evolving webs of interconnected concepts.
Ultimately, AttentionRetriever is not about perfecting retrieval; it’s about admitting that the lines between attention, knowledge, and memory are increasingly blurred. The real challenge isn’t making these models better at finding information, but understanding what it means when they begin to construct it.
Original article: https://arxiv.org/pdf/2602.12278.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- The Best Directors of 2025
2026-02-15 23:59