Author: Denis Avetisyan
A new approach uses reinforcement learning to generate more consistent training data, boosting the performance and reliability of large language models.
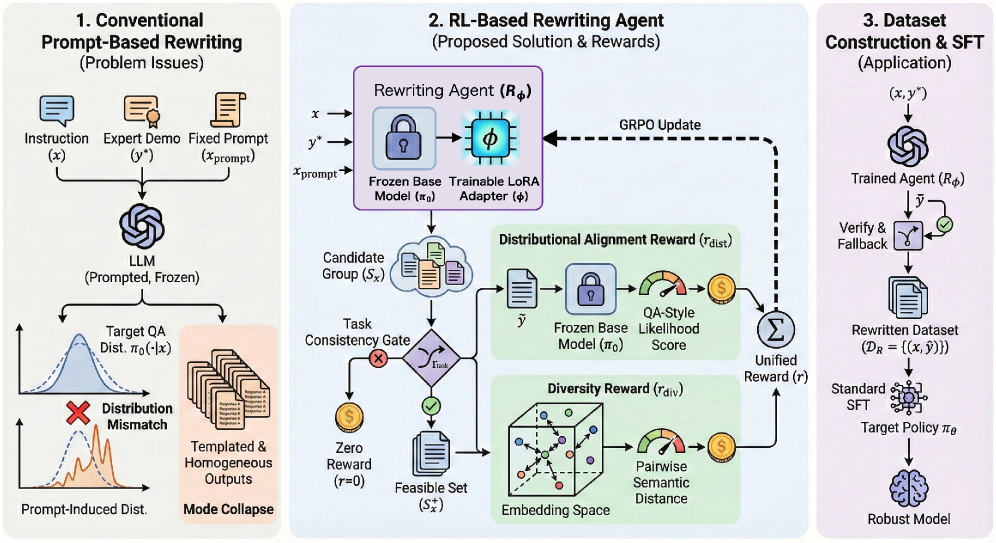
This paper introduces a reinforcement learning agent that addresses distribution shift and catastrophic forgetting during off-policy supervised fine-tuning of large language models by rewriting training data.
While large language models excel in many tasks, adapting them to new scenarios via supervised fine-tuning often suffers from catastrophic forgetting when faced with distributional shift. To address this, we present ‘Patch the Distribution Mismatch: RL Rewriting Agent for Stable Off-Policy SFT’, which introduces a reinforcement learning-based agent that rewrites downstream training data to better align with the model’s generation distribution and preserve diversity. This approach constructs a higher-quality dataset for fine-tuning, achieving comparable performance to standard SFT while significantly reducing forgetting on out-of-distribution benchmarks. Could this data-centric approach, leveraging RL to shape training data, unlock more robust and adaptable language models?
The Inherent Instability of Empirical Models
Large language models, despite demonstrating remarkable capabilities in controlled environments, frequently encounter performance declines when deployed in real-world scenarios due to a phenomenon known as distribution shift. This occurs when the statistical properties of the data a model encounters during use diverge from those it was trained on – a common occurrence given the ever-evolving nature of language and user input. While a model may excel at tasks mirroring its training data, even subtle changes in phrasing, topic, or style can lead to unpredictable outputs and diminished accuracy. This susceptibility isn’t a flaw in the model’s core architecture, but rather an inherent limitation of relying on patterns learned from a static dataset; the model struggles to generalize effectively to previously unseen distributions, highlighting the critical need for robust adaptation strategies and continuous learning mechanisms.
Catastrophic forgetting represents a significant hurdle for Large Language Models, as their performance can dramatically decline when encountering data differing from the initial training distribution. This isn’t simply a matter of reduced accuracy; the models actively lose previously acquired knowledge, effectively unlearning established patterns. This vulnerability is compounded by inherent variability at the token level during text generation; even slight differences in phrasing or word choice can steer the model towards less reliable outputs, particularly when dealing with unfamiliar or out-of-distribution inputs. The consequence is a compounding effect – as the model encounters novel data, its reliance on potentially fragile token-level associations increases, accelerating the forgetting process and diminishing its overall robustness.
While Supervised Fine-Tuning (SFT) remains a standard technique for adapting Large Language Models to specific tasks, it can inadvertently worsen performance issues stemming from distribution shift. The process often involves training on a limited, curated dataset intended to represent the target application, but this dataset rarely perfectly mirrors the nuances of real-world user inputs. Consequently, the model becomes overly specialized, exhibiting diminished generalization capabilities and struggling with previously mastered skills when confronted with data differing significantly from the fine-tuning distribution. This creates a mismatch, effectively trading broad competence for narrow expertise and ultimately exacerbating the problem of catastrophic forgetting as the model prioritizes the new, limited data over its initial, more extensive training.

Proactive Realignment of Empirical Distributions
Patching Distribution Mismatch addresses the performance degradation caused by distribution shift during deployment by modifying downstream data prior to Supervised Fine-Tuning (SFT). This proactive approach contrasts with traditional methods that attempt to correct for distribution shift after model training. By rewriting the supervision targets – the data used to train the model – the system aims to align the training distribution with the expected deployment distribution. This pre-emptive adjustment enhances the model’s generalization capability and reduces the impact of discrepancies between the environments in which the model is trained and deployed, ultimately improving real-world performance.
The RLRewritingAgent addresses distribution shift by modifying supervision targets prior to Supervised Fine-Tuning (SFT). This agent is trained to transform the provided labels or desired outputs, effectively adjusting the training data to more closely resemble the expected distribution encountered during deployment. The transformation process aims to reduce discrepancies between the training and deployment environments, improving model generalization and performance on real-world data. This is accomplished through a learned mapping from original supervision targets to rewritten targets, allowing the model to be trained on data that is statistically more aligned with its intended use case.
The RLRewritingAgent utilizes Low-Rank Adaptation (LoRA) to minimize the number of trainable parameters during adaptation to new supervision targets, enabling efficient modification of the model without full fine-tuning. LoRA achieves this by decomposing weight updates into low-rank matrices, significantly reducing computational cost and memory requirements. Policy optimization is performed using Generalized Reward-augmented Policy Optimization (GRPO), an off-policy algorithm that incorporates reward signals into the policy update process, allowing the agent to learn optimal rewriting strategies based on the desired performance metrics. GRPO facilitates stable and efficient learning in this context by effectively balancing exploration and exploitation during the training phase.

Maintaining Fidelity and Diversity in Augmented Data
The RLRewritingAgent employs a TaskConsistencyGate to validate rewritten data against the original expert demonstrations. This gate functions as a constraint, evaluating the semantic similarity between the generated output and the corresponding expert trajectory. Specifically, the agent calculates a consistency score based on features extracted from both the original and rewritten data; if this score falls below a predefined threshold, the rewritten example is rejected, preventing deviations from the intended task objective. This ensures that augmented data maintains fidelity to the expert behavior and avoids introducing spurious or incorrect information into the training set.
DiversityRegularization techniques within the RLRewritingAgent mitigate the risk of mode collapse during data augmentation. This is achieved by explicitly penalizing rewritten samples that are overly similar to each other, thereby encouraging the agent to explore a wider range of possible outputs. Specifically, the agent employs a diversity loss function that measures the dissimilarity between generated samples, promoting a more varied and representative dataset. This increased diversity improves the agent’s ability to generalize to unseen data and avoids becoming fixated on a limited subset of potential solutions, ultimately enhancing the robustness of the rewritten data.
QAStyleGeneration within the RLRewritingAgent facilitates data augmentation by reformulating existing data into a question-and-answer format. This process involves automatically generating questions based on the original data and using the original data as the corresponding answer. The resulting question-answer pairs effectively increase the size and diversity of the training dataset without requiring manual annotation. This technique is particularly useful for improving model generalization and robustness, as it exposes the model to variations in phrasing and presentation of the same underlying information, leading to more concise and effective data augmentation.

Beyond Empiricism: Implications for Robust Intelligence
This innovative methodology surpasses conventional Supervised Fine-Tuning (SFT) techniques, presenting a more resilient and versatile solution for practical applications. Rigorous testing demonstrates comparable mathematical performance, achieving an overall accuracy of 55.23%-a result directly competitive with standard SFT approaches. However, the framework’s true advantage lies in its adaptability; by moving beyond simple imitation, the system can generalize more effectively to unseen problems and varied datasets. This enhanced robustness positions it as a promising alternative for real-world deployment scenarios where consistent performance across diverse inputs is critical, and where the limitations of strictly supervised learning become particularly apparent.
Conventional machine learning paradigms frequently encounter difficulties when applying knowledge gained from datasets different from those used during training – a challenge known as off-policy learning. This work presents a framework designed to overcome these limitations, enabling the effective utilization of broader, more diverse datasets. By strategically addressing the discrepancies between training and deployment data, the system can extract valuable insights from previously inaccessible sources. The result is a model capable of generalizing beyond the confines of its initial training, leading to improved performance and adaptability in real-world scenarios where data distributions can vary significantly. This broadened data access represents a substantial step towards building more robust and versatile artificial intelligence systems.
The developed methodology demonstrably enhances a model’s ability to perform well on unseen data, achieving a generalization drop of only 7.35% when evaluated on out-of-domain benchmarks – a marked improvement of 11.82% over standard Supervised Fine-Tuning techniques which exhibit a drop of 19.17%. This increased robustness extends to subsequent training phases; downstream Supervised Fine-Tuning demonstrates a loss of just 0.44, a considerable reduction from the 0.74 observed with initial demonstration data and the 0.63 resulting from direct rewrite strategies. These findings suggest a more efficient and adaptable learning process, ultimately yielding models capable of broader application and improved performance in real-world scenarios.
The pursuit of robust large language models necessitates a focus on foundational correctness, mirroring the principles of mathematical elegance. This work, addressing the challenges of distribution shift and catastrophic forgetting, exemplifies this need. It’s not simply about achieving performance on a given dataset, but establishing a system capable of consistently generating in-distribution data, thereby reinforcing the model’s core understanding. As John McCarthy aptly stated, “The best way to predict the future is to invent it.” This sentiment underscores the proactive approach taken here – not merely adapting to existing data limitations, but actively reshaping the data landscape to cultivate a more stable and reliable learning environment. The reinforcement learning agent functions as an ‘inventor’, crafting data that facilitates consistent, provable improvement.
The Road Ahead
The presented work, while demonstrating a pragmatic amelioration of distribution shift, merely skirts the fundamental issue. Reinforcement learning, applied as a corrective to flawed datasets, feels akin to building a more sensitive scale to weigh inaccurate goods. The true elegance lies not in refining the symptoms, but in ensuring the provenance of the data itself. Future inquiry must confront the inherent ambiguities and biases woven into the very fabric of these large language models’ training corpora. Simply generating ‘more in-distribution’ examples begs the question: according to which distribution, and to what end?
A pressing limitation resides in the agent’s reliance on the existing model’s assessment of data quality. This circularity, while perhaps unavoidable in the short term, demands eventual resolution. The field requires a method for objective data validation, ideally grounded in information-theoretic principles rather than empirical performance on downstream tasks. Optimization without analysis remains self-deception; achieving marginal gains in benchmark scores provides scant comfort if the underlying foundations remain unstable.
Ultimately, the long-term viability of this approach hinges on a deeper understanding of catastrophic forgetting. Is this phenomenon merely a surface-level instability, or does it reflect a fundamental limitation in the capacity of these models to truly ‘learn’ in the human sense? The pursuit of provable guarantees – a demonstrably stable and robust learning process – remains the elusive, yet essential, horizon.
Original article: https://arxiv.org/pdf/2602.11220.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- 20 Films Where the Opening Credits Play Over a Single Continuous Shot
- Gold Rate Forecast
- 50 Serial Killer Movies That Will Keep You Up All Night
- Here Are the Best TV Shows to Stream this Weekend on Paramount+, Including ‘48 Hours’
- ‘The Substance’ Is HBO Max’s Most-Watched Movie of the Week: Here Are the Remaining Top 10 Movies
- 17 Black Voice Actors Who Saved Games With One Line Delivery
- Top gainers and losers
- 20 Movies to Watch When You’re Drunk
- 10 Underrated Films by Ben Mendelsohn You Must See
2026-02-14 12:34