Author: Denis Avetisyan
A new framework reveals systematic biases in time series forecasting, demonstrating that even sophisticated models can struggle with complex data dynamics.
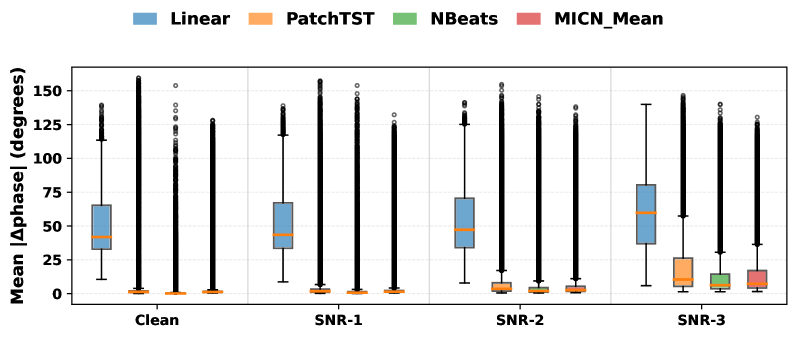
TimeSynth, a synthetic data generation technique, highlights the limitations of linear models and the superior robustness of nonlinear approaches in the face of distribution shift and frequency domain challenges.
Despite the widespread use of time series forecasting, a long-standing debate questions whether complex nonlinear models truly outperform simpler linear approaches. This paper introduces TimeSynth: A Framework for Uncovering Systematic Biases in Time Series Forecasting, a structured approach to generating synthetic time series data that captures key real-world temporal dynamics. Our analysis reveals a systematic bias in linear models-a tendency to collapse into simple oscillatory behavior-while nonlinear models, including Transformers and CNNs, demonstrate greater adaptability to complex signals and improved robustness under distribution shift. This raises a critical question: can principled data generation frameworks like TimeSynth provide a more reliable foundation for evaluating and understanding the strengths and limitations of different forecasting methodologies?
The Fragility of Prediction: A System’s Inevitable Collapse
The capacity to accurately predict future values in time series data is foundational to progress across a remarkably diverse range of fields, from financial markets and climate modeling to neurological research and supply chain logistics. However, many commonly employed forecasting models demonstrate a surprising fragility when confronted with even moderately complex temporal patterns. These models, often optimized for simplicity and computational efficiency, frequently fail to capture the subtle nuances, non-linear dependencies, and high-frequency variations inherent in real-world data. Consequently, predictions can be significantly skewed, leading to flawed decision-making and potentially substantial consequences in any application reliant on precise temporal forecasting. This limitation underscores the urgent need for developing more robust and adaptable algorithms capable of accurately representing the intricate dynamics observed in complex time series.
Despite their computational advantages, conventional time series forecasting methods such as linear models and ARIMA frequently falter when confronted with intricate temporal patterns. These models, designed to extrapolate based on past values and linear relationships, struggle to represent non-linear dynamics, abrupt shifts, or interactions between different frequencies within the data. Consequently, they tend to oversimplify complex signals, smoothing out crucial details and failing to accurately predict future behavior. This limitation isn’t simply a matter of precision; these models can fundamentally misinterpret the underlying process generating the time series, leading to systematic errors and unreliable forecasts – a particularly concerning issue when applied to critical applications like climate modeling or financial analysis.
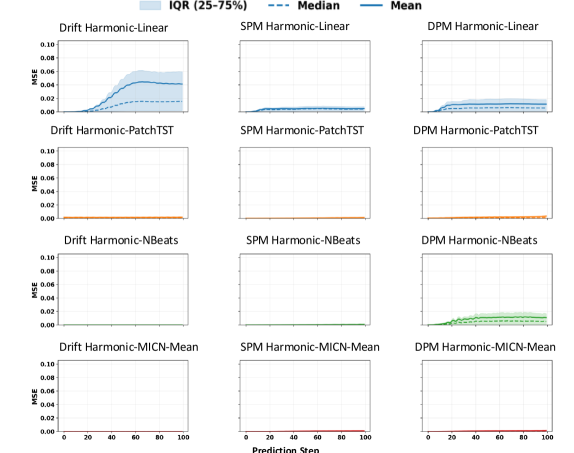
Evaluations reveal a consistent tendency for baseline forecasting models – specifically linear models and ARIMA – to exhibit a fundamental bias, resulting in an oversimplification of complex time series data. Despite the presence of intricate patterns within the input signals, these models frequently converge on basic oscillatory behaviors, effectively ‘collapsing’ the information into repeating cycles. This phenomenon is quantitatively demonstrated through significant \text{Frequency Error} and \text{Amplitude Error} metrics, indicating a systematic inability to accurately reproduce the original signal’s characteristics. The observed behavior suggests an inherent limitation in the model’s capacity to capture non-linear dynamics, highlighting the need for more sophisticated approaches when dealing with genuinely complex temporal data.

The Art of Controlled Complexity: Fabricating Reality
TimeSynth facilitates the creation of synthetic time series data with a wide spectrum of characteristics, beginning with fundamental harmonic signals and extending to complex combinations thereof. This generation process allows for the programmatic control of signal parameters, including frequency, amplitude, and phase modulation. The resulting dataset encompasses signals exhibiting varying degrees of complexity, ranging from single-frequency sine waves to multi-component signals with both linear and non-linear spectral characteristics. This capability is crucial for generating data with known properties, enabling controlled experimentation and rigorous evaluation of time series analysis algorithms and models.
The generation of time series data within TimeSynth utilizes signal types – including Drift, SPM-Harmonic, and DPM-Harmonic signals – that offer granular control over key signal characteristics. Specifically, these signals allow for independent manipulation of frequency, defining the rate of oscillation; amplitude, controlling the signal’s intensity; and phase, determining the initial position within a cycle. Drift Harmonic Signals introduce a linear frequency modulation, while SPM-Harmonic (Sum-Product Modulation) and DPM-Harmonic (Difference-Product Modulation) signals create more complex spectral characteristics through multiplicative combinations of frequencies, enabling the creation of highly customized and controlled datasets for performance evaluation.
Synthetic data generation facilitates a rigorous assessment of model capabilities by providing datasets with precisely defined characteristics. This approach allows researchers to isolate and quantify the effects of various data attributes – such as noise levels, signal complexity, or feature distributions – on model performance. By controlling these parameters, the influence of the data itself can be separated from the inherent limitations of the modeling algorithm, enabling a clear determination of whether observed errors stem from the model’s inability to learn the underlying patterns or from challenges posed by the data’s properties. This disentanglement is crucial for targeted model improvement and the development of robust algorithms less susceptible to data-specific artifacts.

Beyond Simplification: Architectures for a Complex World
Recent advancements in time series forecasting utilize deep learning architectures as alternatives to traditional statistical methods. These include Transformer-based models such as Autoformer and PatchTST, which employ self-attention mechanisms to capture long-range dependencies; Convolutional Neural Networks, implemented in models like ModernTCN and MICN, which leverage convolutional filters for feature extraction; and frequency-domain approaches exemplified by FreTS, which analyze time series data in the frequency domain. These architectures are designed to model complex temporal patterns and potentially improve forecasting accuracy by addressing the limitations inherent in linear models and offering greater flexibility in capturing non-linear relationships within the data.
Modern time series forecasting architectures employ diverse methods to model temporal dependencies. `Transformers`, such as those used in `Autoformer` and `PatchTST`, utilize self-attention mechanisms to weigh the importance of different time steps, enabling the capture of long-range dependencies. `Convolutional Neural Networks` (CNNs), implemented in models like `ModernTCN` and `MICN`, apply convolutional filters to extract local patterns and features within the time series data. Frequency-domain models, exemplified by `FreTS`, decompose the time series into frequency components, allowing for analysis and forecasting based on dominant frequencies; this approach can be particularly effective for seasonal data. Each of these mechanisms offers a unique approach to understanding and predicting future values based on historical data, differing in computational cost and ability to capture specific temporal characteristics.
Evaluation of the described deep learning architectures-including Transformers, Convolutional Neural Networks, and frequency-domain models-was conducted using a synthetic dataset designed to exhibit complex temporal dependencies. This evaluation specifically aimed to determine which models effectively capture these dynamics, surpassing the performance limitations inherent in linear models. Quantitative results, measured by Amplitude Error (MAE) and Phase Error, demonstrated significant reductions in error rates when utilizing these modern architectures, indicating improved accuracy in forecasting both the magnitude and timing of time series data. These metrics provide objective evidence of the models’ ability to represent and predict non-linear patterns present in the synthetic dataset.
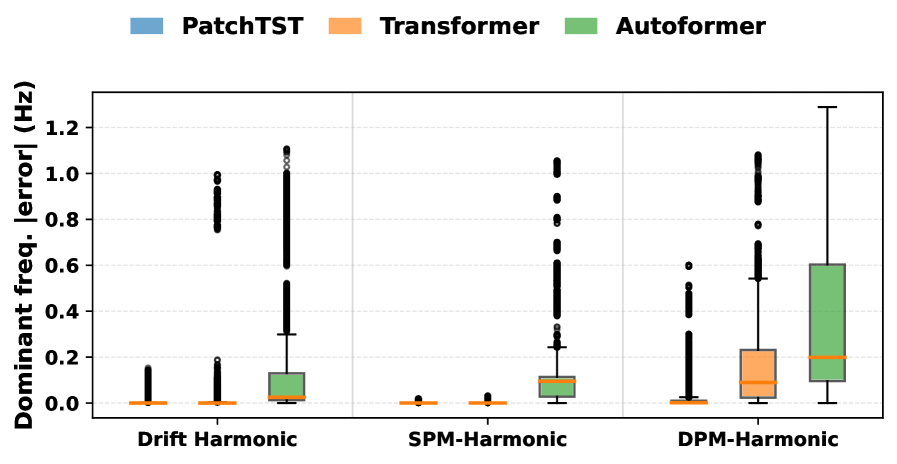
The Inevitable Shift: Stress Testing and the Limits of Generalization
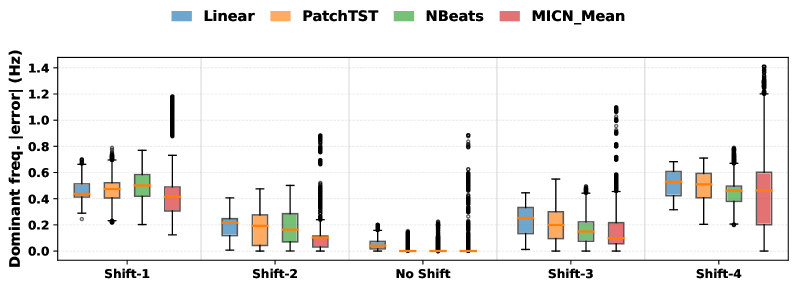
Trained models are rigorously assessed for their capacity to perform reliably when confronted with data that deviates from the original training distribution and the introduction of random noise. This process, known as stress testing, involves deliberately shifting the input data distributions and adding perturbations to simulate real-world conditions where perfect data is rarely available. By exposing the models to these challenges, researchers can quantify their generalization ability – how well they maintain predictive accuracy on unseen data – and identify potential vulnerabilities. The goal is to determine the model’s robustness, ensuring consistent and trustworthy performance even when faced with unexpected variations or imperfect inputs, ultimately increasing confidence in its practical applicability.
A rigorous evaluation of forecasting accuracy hinges on detailed error metrics, and this study employed measures of Frequency Error, Amplitude Error, and Phase Error to dissect model performance. Analysis reveals a compelling advantage for nonlinear models; these consistently demonstrate significantly lower errors across all three metrics when predicting complex patterns. This isn’t simply a marginal improvement; the observed differences indicate a greater capacity for nonlinear models to capture the intricacies of the data and maintain predictive power, suggesting they are better equipped to handle real-world forecasting challenges where data rarely conforms to simple linear relationships.
A model’s efficacy isn’t solely determined by performance on training data; its robustness in the face of real-world imperfections is paramount. Deployment often introduces unforeseen variations – noise, incomplete data, or shifts in underlying distributions – that can drastically degrade predictive power. Therefore, rigorously assessing a model’s sensitivity to these factors is not merely an academic exercise, but a practical necessity. Statistical analysis confirms, with a highly significant p-value of less than 0.001, that even subtle deviations from ideal conditions can impact forecasting accuracy. Consequently, understanding and mitigating these vulnerabilities is critical for ensuring reliable and consistent performance when a model transitions from the controlled environment of the laboratory to the unpredictable landscape of real-world application.
The Horizon Beckons: Towards Foundation Models for Time Series
Recent synthetic evaluations are actively shaping the development of what are termed `Foundation Models` for time series forecasting. These models represent a paradigm shift, moving beyond task-specific approaches towards broadly applicable systems capable of learning robust representations from diverse time series data. The core principle involves pre-training on large-scale, synthetically generated datasets – allowing the model to capture underlying temporal dynamics and patterns – before fine-tuning on specific, real-world forecasting tasks. This pre-training process effectively establishes a strong prior, enabling the model to generalize more effectively to unseen data and adapt quickly to new domains, ultimately leading to improved forecasting accuracy and reliability across a wide range of applications.
The pursuit of foundation models in time series analysis centers on creating a unified approach to both understanding the underlying patterns within data – representation learning – and predicting future values – forecasting. This convergence allows for the development of models capable of transferring knowledge gained from one time series domain to another, dramatically improving generalization performance. Instead of training specialized models for each unique dataset, a single, pre-trained foundation model can be adapted to various tasks, such as predicting stock prices, forecasting energy consumption, or analyzing patient health data, with minimal fine-tuning. This capability promises to overcome the limitations of traditional time series models, which often struggle with unseen data or require extensive retraining for each new application, ultimately paving the way for more robust and adaptable forecasting systems.
The pursuit of robust time series forecasting is increasingly focused on integrating architectural strengths and pre-training methodologies. Researchers are moving beyond single-model approaches, instead combining the advantages of recurrent neural networks, transformers, and state-space models to capture diverse temporal dependencies. This unification is significantly enhanced by synthetic data generation, allowing for the creation of large, controlled datasets used to pre-train models – a technique proven effective in natural language processing and computer vision. This pre-training process aims to resolve a critical challenge in time series analysis: the inherent trade-off between model stability – the ability to consistently produce reasonable forecasts – and fidelity, or the accuracy of those forecasts, particularly during periods of high volatility or unexpected events. By learning broad temporal patterns from synthetic data, these models demonstrate improved generalization capabilities, potentially unlocking more accurate and reliable forecasts in complex, real-world applications where data is often limited or noisy.
The pursuit of perfect forecasting models often obscures a fundamental truth: systems reveal their limitations not in isolated failures, but in predictable patterns of compromise. This work with TimeSynth, demonstrating the tendency of linear models towards trivial oscillations under distribution shift, merely confirms what history already knows. As Blaise Pascal observed, “The eloquence of angels is silence.” Similarly, the simplicity of a linear model, while elegant, betrays its inability to grapple with the inherent noise and nonlinearity of temporal dynamics. The framework isn’t a solution, but an illumination – a means of understanding how systems fail, and accepting the inevitability of that failure as part of their very nature. One builds not for perfection, but for graceful degradation.
What’s Next?
The generation of synthetic time series, as formalized by TimeSynth, does not offer a solution so much as a clearer view of the problem. Each carefully constructed dataset is, inevitably, a prophecy of failure – a precise articulation of the assumptions baked into both the data generation process and the models subsequently evaluated upon it. The observed collapse of linear models into trivial oscillation isn’t a bug, but a predictable consequence of applying a fundamentally limited architecture to systems that demonstrably aren’t linear. The question isn’t whether such models will fail, but when, and under what specific conditions.
Future work will undoubtedly explore more elaborate synthetic data generation techniques, attempting to capture increasingly nuanced dynamics. However, the pursuit of ‘realistic’ synthetic data feels like chasing a phantom. The true leverage lies not in mimicking reality, but in deliberately crafting datasets that expose the limits of our modeling approaches. It is in the careful design of counterfactuals, of impossible scenarios, that genuine progress might be found.
The emphasis on frequency domain analysis is promising, yet feels like the opening of another, perhaps larger, box. It suggests that model bias isn’t merely a matter of capturing point estimates, but of reproducing the underlying spectral characteristics of the system. One anticipates a future where model evaluation focuses not on accuracy, but on fidelity to the shape of the power spectrum – a subtly different, and considerably more difficult, objective. And, predictably, documentation of these findings will be sparse; no one writes prophecies after they come true.
Original article: https://arxiv.org/pdf/2602.11413.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- 20 Films Where the Opening Credits Play Over a Single Continuous Shot
- Gold Rate Forecast
- Here Are the Best TV Shows to Stream this Weekend on Paramount+, Including ‘48 Hours’
- ‘The Substance’ Is HBO Max’s Most-Watched Movie of the Week: Here Are the Remaining Top 10 Movies
- 17 Black Voice Actors Who Saved Games With One Line Delivery
- Top gainers and losers
- 20 Movies to Watch When You’re Drunk
- 10 Underrated Films by Ben Mendelsohn You Must See
- 10 Underrated Films by Wyatt Russell You Must See
2026-02-14 04:16