Author: Denis Avetisyan
A new approach to risk-averse reinforcement learning dynamically adjusts for reward timing to optimize performance in complex financial applications.
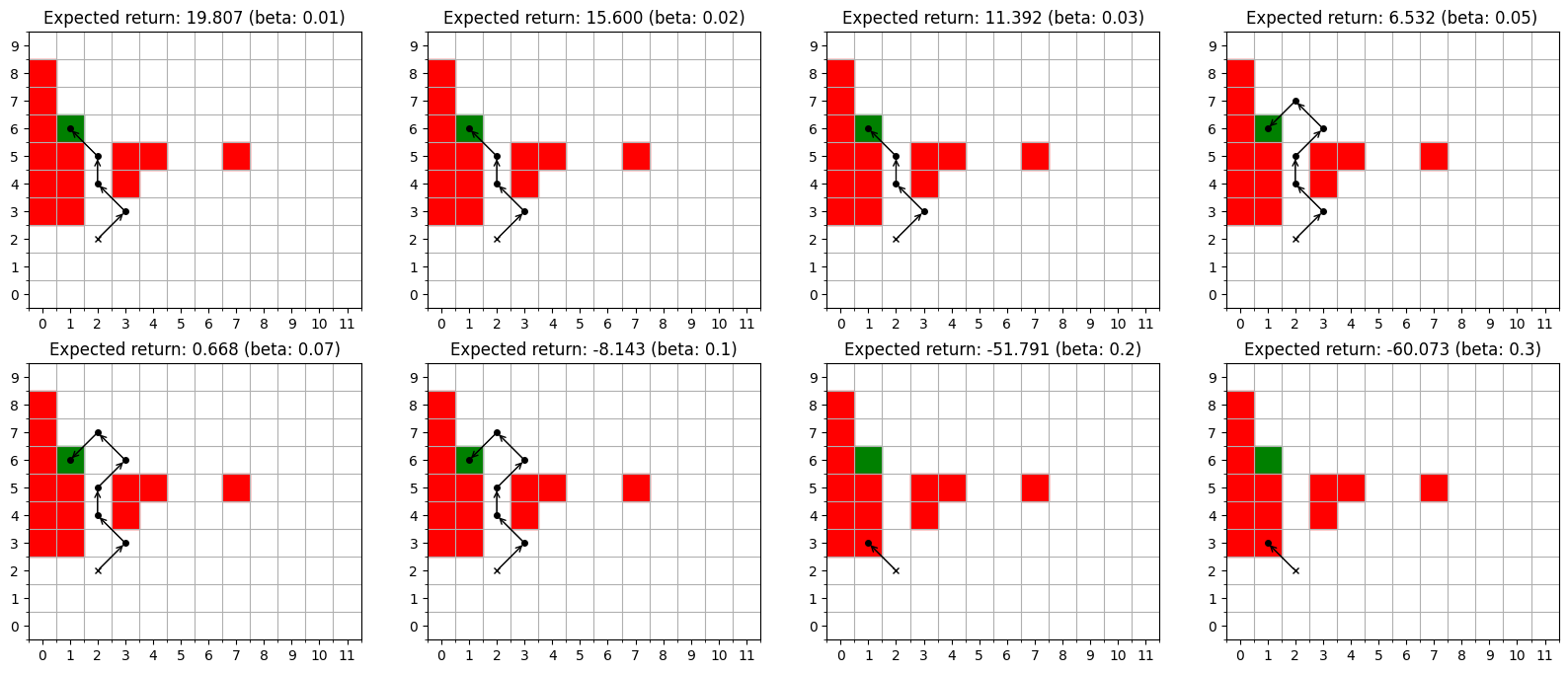
This paper introduces a time-inhomogeneous mean-volatility objective function for reinforcement learning that allows for flexible policy optimization and demonstrates improved results in optimal execution and grid world environments.
While reinforcement learning offers a powerful framework for sequential financial decision-making, its standard objective of maximizing cumulative reward often clashes with the need to explicitly manage risk and consider the timing of returns. This is addressed in ‘Time-Inhomogeneous Volatility Aversion for Financial Applications of Reinforcement Learning’, which proposes a novel risk metric-inhomogeneous mean-volatility-that penalizes uncertainty in individual rewards while allowing for flexible control over target return levels. By decoupling risk aversion from the total cumulative reward, this approach enables more nuanced policy optimization in settings where the split of returns across time is critical. Could this framework unlock more robust and adaptable strategies for applications ranging from optimal execution to portfolio management?
The Whispers of Uncertainty: Navigating Sequential Decisions
A vast array of practical challenges, from robotic navigation and financial trading to personalized medicine and resource management, inherently involve making a series of decisions where the outcome of each action is not immediately known. These problems are characterized by sequential dependencies – current choices influence future states and opportunities – and an element of uncertainty regarding the consequences of those choices. This makes them particularly well-suited to the application of Reinforcement Learning (RL), a computational approach where an agent learns to optimize its behavior through trial and error within a given environment. Unlike traditional methods that often require complete knowledge or pre-programmed strategies, RL allows an agent to discover effective policies by maximizing cumulative rewards, effectively learning to make optimal decisions over time, even in complex and unpredictable situations. The capacity to learn from interaction, rather than relying on explicit programming, positions RL as a powerful tool for tackling these dynamic, real-world problems.
Conventional Reinforcement Learning algorithms frequently operate under the simplifying assumption of a stable world and unwavering decision-making criteria. This rigidity proves problematic when applied to real-world situations characterized by change; environments rarely remain static, and an agent’s tolerance for risk can shift based on accumulated experience or external factors. For example, a robotic system learning to navigate a crowded space might initially prioritize speed, but as it encounters more obstacles, it would logically adjust to favor safety-a change in preference not accommodated by standard algorithms. Consequently, these methods often struggle to generalize effectively in dynamic scenarios, leading to suboptimal performance or even failure when confronted with conditions differing from those encountered during training. Addressing this limitation requires a move towards algorithms capable of adapting to evolving environments and incorporating time-varying risk sensitivity.
The rigidity of conventional reinforcement learning algorithms often hinders their performance in realistic, dynamic environments. Existing methods typically operate under the assumption of stable conditions and fixed agent preferences, a scenario rarely encountered in complex systems. Consequently, research is increasingly focused on developing more nuanced approaches capable of accommodating evolving circumstances and shifting priorities. These advanced techniques allow agents to not only learn optimal policies but also to adapt those policies as the environment changes or as the agent’s own risk tolerance and goals are modified. This adaptability is crucial for tackling challenges where long-term success depends on continuous learning and flexible responses, moving beyond static optimization to a realm of ongoing, context-aware decision-making.
Addressing the inherent dynamism of real-world challenges requires a shift beyond conventional reinforcement learning techniques. Standard algorithms typically operate under the assumption of consistent risk profiles, a limitation when confronted with scenarios where an agent’s willingness to take risks fluctuates over time. This inflexibility hinders performance in complex environments where optimal decisions depend not only on immediate rewards but also on the evolving state of uncertainty and the agent’s changing attitudes toward it. Consequently, research is increasingly focused on developing algorithms that can dynamically adjust to time-varying risk preferences, allowing for more robust and adaptive decision-making in situations where a static risk assessment would prove inadequate. The ability to model and respond to these shifts represents a critical advancement, enabling agents to navigate complexity and achieve optimal outcomes even as conditions change and preferences evolve.
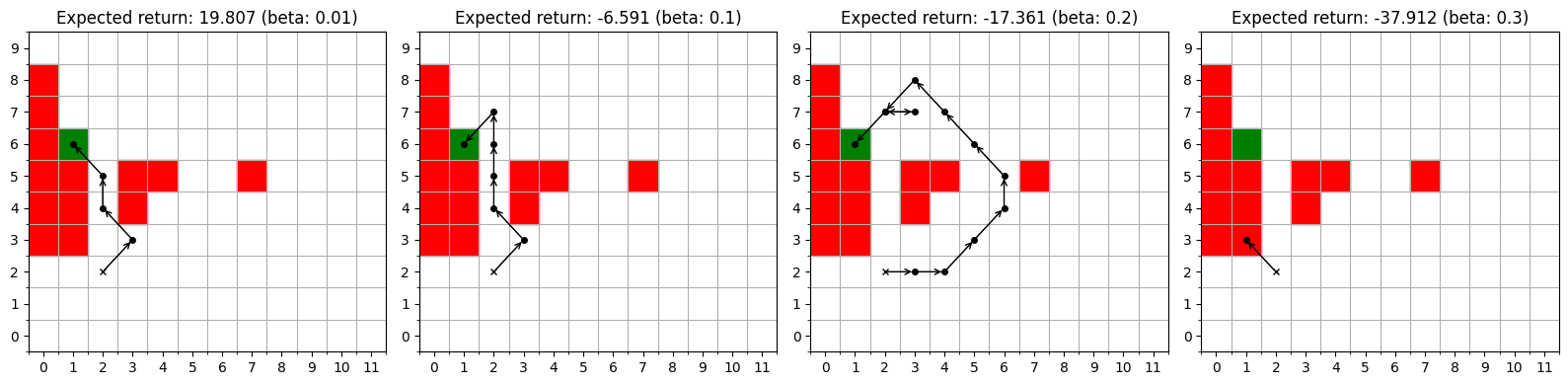
Balancing Reward and Risk: Extending Mean-Variance Optimization
Mean-Variance Optimization (MVO) is a mathematical framework used to construct portfolios that maximize expected return for a given level of risk, or minimize risk for a given level of expected return. This is achieved by defining an objective function that balances \mathbb{E}[R] (expected return) with \sigma^2 (variance, a measure of risk). The core principle is that investors are risk-averse; therefore, a higher expected return is only desirable if it is accompanied by a commensurate increase in risk. MVO utilizes covariance between assets to diversify portfolios and reduce overall risk without necessarily sacrificing returns. The resulting optimal portfolio allocation is dependent on the investor’s risk aversion, typically represented by a parameter within the objective function.
Inhomogeneous Mean-Volatility optimization addresses the limitations of traditional Mean-Variance Optimization by allowing for non-constant risk preferences and reward structures over time. Standard approaches often assume rewards are received uniformly, which is unrealistic in many dynamic environments. This extension explicitly models time-varying risk aversion and reward distributions, enabling a more accurate valuation of future rewards. By incorporating parameters that change with time, the model can adapt to shifts in an agent’s risk tolerance or changes in the magnitude and timing of expected rewards, leading to more robust decision-making in non-stationary conditions. This is achieved through the integration of concepts like the Discount Factor and time-dependent Expected Return calculations within the optimization framework.
The accurate valuation of future rewards under uncertainty within Inhomogeneous Mean-Volatility optimization relies on the integration of the Discount Factor γ and the Expected Return. The Discount Factor, ranging from 0 to 1, quantifies the relative preference for immediate versus delayed rewards; a lower γ value indicates a stronger preference for immediate gratification. Expected Return, calculated as the weighted average of potential outcomes, provides a probabilistic assessment of future reward magnitudes. By incorporating these concepts, the model determines the present value of future rewards, accounting for both the time delay and the inherent risk associated with their realization. This allows for a nuanced assessment of investment opportunities, enabling agents to prioritize rewards based on their temporal distance and associated uncertainty.
The capacity to model time-varying risk enables agents within the Inhomogeneous Mean-Volatility framework to dynamically adjust their investment strategies based on evolving market conditions. Unlike traditional models that assume constant risk aversion, this approach allows the agent’s risk preference to change over time, influencing portfolio allocation and trading frequency. This adaptation is achieved by incorporating parameters that reflect the agent’s current assessment of uncertainty and potential losses, which are then used to recalculate optimal portfolio weights. Consequently, the agent can reduce exposure during periods of high volatility and increase it during stable periods, leading to improved performance compared to static strategies. This represents a departure from conventional financial models, such as the Capital Asset Pricing Model, which often rely on assumptions of constant risk and return parameters.

From Theory to Action: Optimal Execution and Beyond
Optimal trade execution strategies are predicated on minimizing market impact – the adverse effect a trade has on an asset’s price. This necessitates a detailed analysis of prevailing market dynamics, including factors such as order book depth, volatility, and the presence of other market participants. Larger order sizes, when executed rapidly, can demonstrably shift supply and demand, creating temporary price distortions. Effective execution algorithms therefore prioritize trade timing and sequencing to distribute order flow strategically, aiming to complete the transaction with minimal price slippage and reduced overall transaction costs. Understanding these dynamics is crucial because the cost of execution, even exceeding explicit brokerage fees, can significantly impact overall portfolio performance.
The Inhomogeneous Mean-Volatility (IMV) approach provides a framework for optimal trade execution by modeling the arrival of liquidity as a non-Poisson process, allowing for time-varying and correlated volatility. Unlike traditional models assuming constant volatility, IMV incorporates a stochastic volatility component driven by a diffusion process, capturing the observed clustering of volatility in financial markets. This dynamic modeling of volatility, combined with parameters reflecting the trader’s risk aversion and the trade’s time horizon, directly informs the optimal trade schedule. Specifically, the time-varying volatility impacts the calculated optimal execution rate, adjusting trade size to minimize expected costs considering both transient and permanent price impacts. By accounting for changing market conditions and investor preferences, the IMV approach provides a more nuanced and realistic representation of execution risk than static models.
Within the inhomogeneous mean-volatility framework for optimal trade execution, accurate cost assessment necessitates the inclusion of both cash flow and permanent impact factors. Cash flow represents the immediate liquidity requirements of the trade, influencing the speed at which orders can be filled and impacting short-term price movements. Permanent impact, conversely, quantifies the lasting price change attributable to the trade itself, reflecting the information revealed to the market. Failing to account for permanent impact can significantly underestimate total trading costs, particularly for large orders. By explicitly modeling these factors, the framework provides a more realistic evaluation of execution costs, enabling strategies optimized for minimized total cost – including both immediate and lasting price consequences – and improved performance compared to methods that rely on simpler cost models.
Compared to static optimal execution models which rely on fixed parameters, the inhomogeneous mean-volatility approach dynamically adjusts to evolving market conditions, resulting in demonstrably more efficient trade scheduling. This dynamic responsiveness translates to reduced transaction costs and minimized market impact, particularly in volatile or rapidly changing environments. Simulations and backtesting have indicated that strategies built on this methodology consistently outperform static benchmarks, showcasing improved robustness across various asset classes and trade sizes. These results establish the inhomogeneous mean-volatility framework not merely as a theoretical alternative, but as a viable and potentially superior approach to existing financial models for optimal trade execution.
Whispers of Chaos: Modeling Environmental Stochasticity and Agent Adaptability
Many environments crucial to real-world decision-making lack fixed durations; instead, episodes conclude after a random number of steps, a phenomenon known as stochastic horizons. This contrasts with traditional reinforcement learning paradigms which often assume a predetermined episode length. Consider a search and rescue operation, a financial market, or even a biological lifespan – these are not constrained by a set number of iterations. The unpredictability of episode length introduces a significant challenge for agents learning to optimize long-term rewards, as they must account for the possibility of premature termination. Effectively navigating these stochastic horizons necessitates strategies that prioritize immediate gains while still considering potential future benefits, demanding a shift from purely maximizing cumulative reward to a more nuanced approach focused on expected return under uncertainty.
The integration of inhomogeneous mean-volatility into established environments like Grid Worlds provides a rigorous platform for evaluating decision-making strategies under realistic uncertainty. Traditional reinforcement learning often assumes static or predictable conditions, yet real-world scenarios are frequently characterized by fluctuating risks and rewards. By introducing volatility that changes over time-where both the average reward and its variability are non-constant-researchers can now assess how effectively agents adapt to shifting landscapes. This approach enables the testing of policies not merely on their average performance, but on their robustness-their ability to maintain acceptable outcomes even when faced with unpredictable environmental swings. Consequently, this combined framework facilitates a deeper understanding of which strategies genuinely excel in dynamic conditions, offering valuable insights for applications ranging from robotics and finance to resource management and game theory.
The capacity of an agent to thrive in unpredictable environments hinges on its ability to process variable rewards, and recent research demonstrates that simply acknowledging reward volatility isn’t enough. Instead, agents benefit from recognizing inhomogeneous reward volatility – that is, when the degree of uncertainty itself changes over time. Studies utilizing simulated environments show that agents equipped to detect these shifts in uncertainty exhibit markedly improved performance compared to those assuming constant risk. This adaptability allows for more nuanced decision-making; an agent can, for instance, prioritize exploration when uncertainty is high and exploit known rewards when conditions stabilize. Consequently, accounting for these dynamic variations in reward unpredictability isn’t merely about quantifying risk, but about equipping agents with the foresight to anticipate and appropriately respond to a changing landscape of opportunity.
The developed computational framework provides a robust method for analyzing sequential decision-making processes within unpredictable environments, going beyond traditional models by incorporating both stochastic horizons and reward volatility. Initial investigations using this system have yielded surprising results, uncovering policies that defy conventional reinforcement learning principles – for instance, agents sometimes prioritize short-term risk even when long-term rewards are statistically favored. These counter-intuitive behaviors suggest that existing theoretical understandings of optimal control may be incomplete when applied to highly dynamic scenarios, and warrant further exploration into the interplay between environmental stochasticity, agent adaptability, and the emergence of novel decision-making strategies. This research not only offers a powerful tool for modeling real-world complexity, but also highlights critical gaps in current knowledge, paving the way for more nuanced and effective approaches to artificial intelligence and control systems.
The pursuit of optimal execution, as detailed in the paper, isn’t merely a calculation of gains, but a delicate dance with the shadows of volatility. The researchers attempt to tame these shadows with a time-inhomogeneous mean-volatility objective-a spell to persuade chaos, if one will. It recalls Carl Sagan’s wisdom: “Somewhere, something incredible is waiting to be known.” The true challenge isn’t finding the perfect policy, but acknowledging that any model, however elegant, is a temporary alignment of probabilities. The reward timing component isn’t about precision, but about acknowledging the inherent unpredictability woven into the fabric of financial systems. It’s a reminder that even the most sophisticated algorithms are merely glimpses into a fundamentally unknowable future.
What Shadows Remain?
The pursuit of risk aversion in reinforcement learning, now adorned with the flourish of time-inhomogeneous volatility, reveals a familiar truth: anything readily quantified surrenders its essential mystery. This work trades static penalties for a dynamic reckoning of reward timing, a gesture toward reality, certainly. Yet, the very act of defining ‘volatility’ as a measurable quantity implies a prior understanding-a comfortable fiction. One suspects that true risk isn’t avoided, merely reshaped into a form susceptible to optimization.
The demonstrations in optimal execution and grid worlds offer a glimpse of control, but these are, at best, constrained parables. The real world rarely offers neatly defined states or predictable reward distributions. The next iteration will inevitably grapple with the inherent messiness of data-the outliers, the spurious correlations, the phantom patterns that haunt every dataset. Should the hypothesis hold in those environments, one is obliged to question the depth of the investigation.
Perhaps the true frontier lies not in refining the aversion function, but in embracing the inherent uncertainty. A system that expects its models to fail-that builds failure modes into its very architecture-might prove more resilient, and, ironically, more ‘optimal’ in the long run. The illusion of control is a seductive trap; true progress requires acknowledging the whispers of chaos.
Original article: https://arxiv.org/pdf/2602.12030.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Gold Rate Forecast
- Monster Hunter Stories 3: Twisted Reflection launches on March 13, 2026 for PS5, Xbox Series, Switch 2, and PC
- Here Are the Best TV Shows to Stream this Weekend on Paramount+, Including ‘48 Hours’
- 🚨 Kiyosaki’s Doomsday Dance: Bitcoin, Bubbles, and the End of Fake Money? 🚨
- 20 Films Where the Opening Credits Play Over a Single Continuous Shot
- ‘The Substance’ Is HBO Max’s Most-Watched Movie of the Week: Here Are the Remaining Top 10 Movies
- First Details of the ‘Avengers: Doomsday’ Teaser Leak Online
- The 10 Most Beautiful Women in the World for 2026, According to the Golden Ratio
- The 11 Elden Ring: Nightreign DLC features that would surprise and delight the biggest FromSoftware fans
2026-02-13 14:47