Author: Denis Avetisyan
A new framework combines the power of artificial intelligence with graph databases to deliver more accurate and scalable data reasoning.
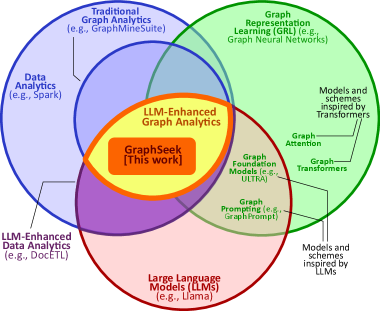
GraphSeek introduces a semantic catalog and non-LLM execution plane to enhance large language model-driven graph analytics.
Despite the promise of large language models for accessible data analysis, applying them to real-world, large-scale property graphs remains challenging due to their size, complexity, and dynamic nature. This paper introduces ‘GraphSeek: Next-Generation Graph Analytics with LLMs’, a novel framework that decouples LLM-driven semantic planning from deterministic query execution via a dedicated Semantic Catalog. This separation enables substantially improved efficiency and accuracy in graph analytics, achieving significantly higher success rates than existing approaches. Could this abstraction unlock a new era of affordable and scalable graph intelligence, unifying the reasoning power of LLMs with the reliability of database systems?
The Inevitable Scaling Crisis of Connected Data
Traditional graph analytics face significant hurdles when confronted with the sheer scale and intricacy of modern datasets. Algorithms designed for smaller, static graphs often falter as the number of nodes and edges expands into the billions, resulting in drastically slowed query performance. This computational burden isn’t merely a matter of processing time; it also limits the depth of insight attainable. Complex analytical operations, such as identifying nuanced community structures or predicting cascading failures, become impractical or even impossible within acceptable timeframes. Consequently, organizations struggle to fully leverage the potential of their connected data, missing opportunities for improved decision-making, fraud detection, and personalized experiences. The inherent limitations of these conventional methods necessitate the development of more scalable and efficient techniques to effectively navigate the complexities of real-world graph data.
Traditional graph analytics pipelines frequently demand substantial pre-processing of data before analysis can commence, often involving cleaning, transformation, and indexing-a process that can be both time-consuming and resource-intensive. This reliance on static pre-processing creates a significant bottleneck, particularly as real-world graphs are rarely static; they are dynamic entities constantly undergoing evolution through node and edge additions, deletions, and attribute changes. Consequently, existing methodologies struggle to adapt to these evolving landscapes, necessitating repeated and costly re-processing with each update. This inflexibility limits the ability to derive timely insights from rapidly changing connected data, hindering applications requiring real-time or near real-time graph analysis, and ultimately diminishing the overall value derived from the data.
The true potential of connected data remains largely untapped due to limitations in current analytical approaches. As datasets grow in both size and complexity-representing social networks, financial transactions, or biological systems-traditional graph analytics falter, struggling to deliver timely insights. A pressing need exists for systems capable of scaling to handle massive graphs without sacrificing performance, and which can adapt to dynamic data streams and evolving analytical questions. Crucially, these tools must also be intuitive, enabling a broader range of users – not just specialized data scientists – to explore complex relationships and extract meaningful value. Addressing these three pillars – scalability, adaptability, and intuitiveness – is paramount to transforming raw connections into actionable intelligence and realizing the full promise of graph-based analysis.
Decoupling Intelligence: A Necessary Architecture
GraphSeek introduces a distinct architectural separation between semantic understanding and deterministic execution. Traditionally, knowledge graphs require queries formulated in specific languages like SPARQL or Cypher. GraphSeek decouples query interpretation from execution by utilizing Large Language Models (LLMs) to process natural language input and translate it into a formal query. This formal query is then executed by a dedicated graph engine, ensuring predictable and verifiable results. This separation allows the LLM to focus on linguistic nuance and ambiguity resolution, while the graph engine guarantees efficient data retrieval and manipulation, independent of the LLM’s potential for non-deterministic outputs.
The decoupling of semantic understanding from deterministic execution enables a synergistic approach to knowledge processing. Large Language Models (LLMs) excel at interpreting natural language queries, accommodating ambiguity and variations in phrasing, but are computationally expensive and lack guaranteed consistency. Conversely, graph engines provide efficient, reliable, and scalable processing of structured data, but require precise and formally defined queries. By utilizing LLMs for initial query interpretation and translation into formal graph queries, and then executing those queries via a graph engine, the framework benefits from the LLM’s flexibility and the graph engine’s performance and deterministic results. This division of labor optimizes both the interpretative and computational aspects of knowledge retrieval and reasoning.
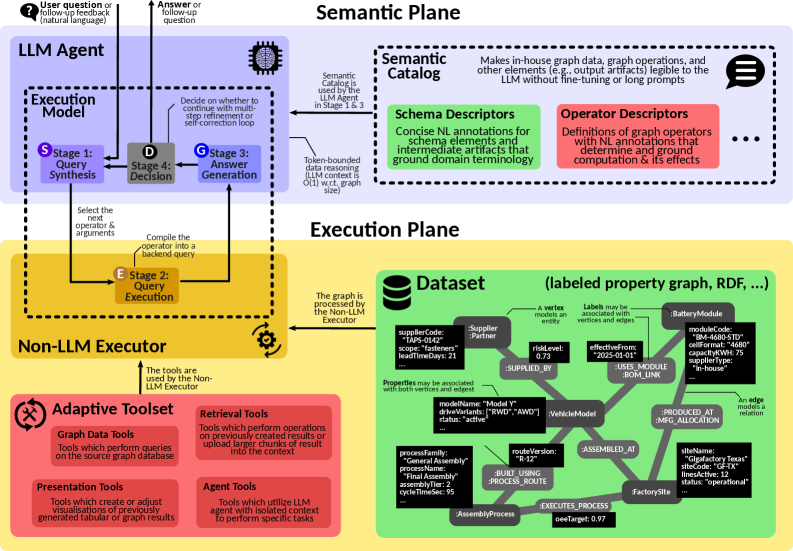
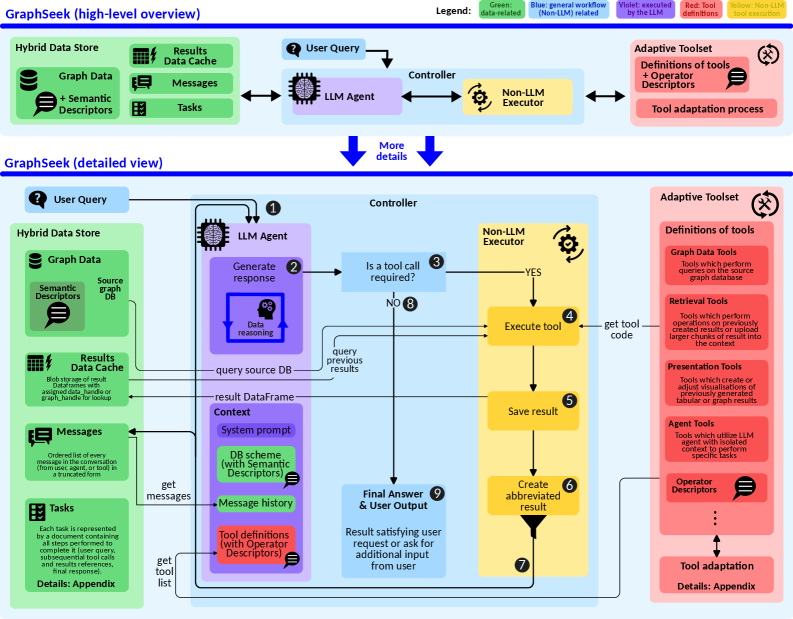
GraphSeek’s architecture comprises three core components. The LLM Agent processes natural language queries, translating them into an intermediate representation. This representation is then passed to the Non-LLM Executor, a deterministic engine responsible for executing the query against the underlying graph data. Crucially, the Semantic Catalog acts as a grounding layer, mapping natural language terms to specific elements within the graph schema – nodes, relationships, and properties – thereby ensuring accurate query translation and execution. This separation of concerns allows GraphSeek to combine the interpretative power of LLMs with the reliability and efficiency of traditional graph processing systems.
How GraphSeek Achieves Scalable and Adaptive Analytics
The GraphSeek LLM Agent employs Natural Language Processing (NLP) techniques to interpret user queries expressed in natural language. This interpretation is coupled with a process called Schema Grounding, which maps the concepts within the natural language request to the specific schema of the underlying graph database. This mapping is critical; it allows the LLM to accurately identify relevant entities, relationships, and properties within the graph. The result of this NLP and Schema Grounding process is the generation of a formal, executable graph query, typically expressed in a graph query language like Cypher or SPARQL, ready for processing by the Non-LLM Executor. This translation step bridges the gap between human-readable requests and machine-understandable instructions for data retrieval and analysis.
The Non-LLM Executor component of GraphSeek functions by translating the LLM Agent’s output into a formal graph query expressed in a Graph Query Language, such as Cypher or SPARQL. This query is then submitted to an underlying Graph Database – including options like Neo4j, Amazon Neptune, or others – for deterministic execution. This separation of concerns ensures predictable and reproducible results, as the execution is not subject to the stochasticity inherent in Large Language Models. The Executor strictly adheres to the defined schema of the Graph Database, enabling efficient data retrieval and manipulation without requiring the LLM to directly interact with the database during inference.
The GraphSeek system incorporates an Adaptive Toolset and Execution Plane to facilitate real-time optimization of graph queries during inference. This functionality enables dynamic adjustments to the query processing strategy based on intermediate results and observed performance metrics. The Execution Plane manages a series of potential optimizations, including tool selection, query rewriting, and data access path adjustments. These dynamic updates allow GraphSeek to mitigate performance bottlenecks and adapt to varying data characteristics without requiring pre-compiled query plans, resulting in improved efficiency and reduced latency compared to static query execution approaches. The system continuously evaluates the impact of these adaptations, further refining the optimization process for subsequent queries.
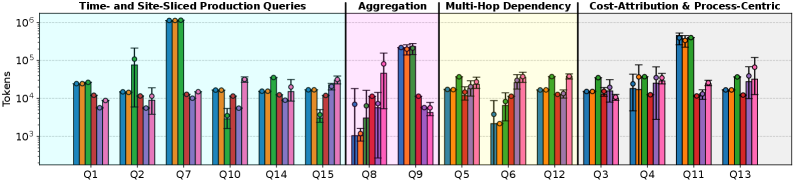
GraphSeek demonstrates an 86% success rate in processing graph queries, exceeding the performance of enhanced LangChain solutions. This performance is achieved while maintaining a median token usage of 29.7k tokens per query, indicating efficient resource utilization. Furthermore, the system exhibits a median latency of 2-3 seconds when leveraging Special Tools, representing a responsive processing time for analytical requests. These metrics were obtained through rigorous testing and benchmarking of the GraphSeek architecture.
Unlocking Industrial Value: From Manufacturing to Beyond
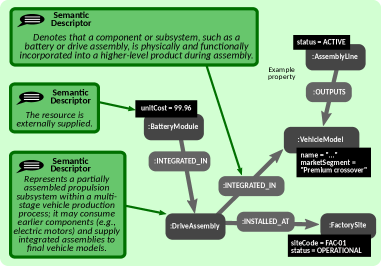
Industrial Graph Analytics presents unique hurdles due to the sheer complexity of interconnected data within manufacturing processes, and GraphSeek is designed to overcome these challenges, particularly within the rapidly evolving Electric Vehicle (EV) industry. The framework addresses the need to analyze relationships between thousands of components, assembly steps, and supply chain elements – a task often exceeding the capacity of traditional relational databases. By modeling EV manufacturing as a property graph, where nodes represent entities like parts, sensors, or production lines and edges define their relationships, GraphSeek enables efficient querying and reasoning about complex systems. This approach facilitates proactive identification of potential bottlenecks, optimization of production workflows, and improved quality control, ultimately accelerating innovation and reducing costs within the EV sector and beyond.
Industrial systems are inherently relational, with intricate connections between components, processes, and data streams; Property Graphs offer a uniquely effective means of representing these complexities. Unlike traditional relational databases, Property Graphs model data not just as tables, but as nodes and relationships, allowing for a more intuitive and flexible depiction of industrial assets and their interactions. This approach enables efficient modeling of dependencies – for instance, tracing the supply chain of a specific component, identifying potential bottlenecks in a manufacturing process, or understanding the impact of a design change across multiple systems. By directly encoding relationships as first-class citizens within the data model, analyses that would require complex joins in relational databases become streamlined, leading to faster insights and improved decision-making within industrial environments.
The GraphSeek framework excels at navigating complex industrial data through a process called multi-hop traversal. This capability allows the system to follow relationships between relationships, uncovering insights that remain hidden to conventional analytical methods. For instance, instead of simply identifying components with defects, GraphSeek can trace the origin of a faulty part through multiple stages of the manufacturing process – from raw material supplier to specific machine settings – revealing systemic issues impacting quality. This extended reasoning is particularly crucial in complex systems like electric vehicle production, where dependencies between thousands of parts and processes create intricate networks of information; multi-hop traversal unlocks a deeper understanding of these networks, enabling proactive problem-solving and optimized performance that traditional methods simply cannot achieve.
Evaluations reveal that GraphSeek offers a significant economic advantage in Large Language Model (LLM)-powered graph analytics, consistently exhibiting lower token costs when benchmarked against LangChain baselines. Across a comprehensive suite of 30 diverse queries designed to test complex industrial relationships, GraphSeek’s optimized approach minimizes the computational resources required to derive meaningful insights from property graphs. This improved efficiency translates directly into reduced operational expenses for businesses leveraging LLMs for tasks such as supply chain optimization, predictive maintenance, and root cause analysis, making advanced graph analytics more accessible and sustainable at scale.
The pursuit of scalable graph analytics, as demonstrated by GraphSeek, isn’t about imposing order, but about cultivating an environment where reasoning can flourish. The framework’s separation of semantic catalog and execution plane suggests an understanding that systems aren’t built, they evolve. This echoes a sentiment shared by Paul Erdős: “A mathematician knows a lot of things, but knows nothing deeply.” Similarly, GraphSeek doesn’t attempt to solve graph analytics with a monolithic approach, but rather provides a flexible foundation-a garden, if you will-for LLMs to explore and derive insights, acknowledging the inherent complexity and continuous discovery within the realm of data reasoning. The focus on forgiveness between components-allowing for efficient execution despite the imperfections of LLMs-is a testament to this principle.
What Lies Ahead?
GraphSeek rightly positions itself at the confluence of knowledge representation and reasoning. However, the architecture reveals a familiar tension: the semantic catalog, while intended to constrain the LLM, ultimately predicts the points of future fragility. Every curated ontology becomes a potential surface for unforeseen data drift, a silent assertion of incompleteness. Monitoring, then, is not merely observation, but the art of fearing consciously.
The pursuit of “scalable” LLM-enhanced analytics risks mistaking velocity for understanding. The true challenge isn’t processing more graphs, but accepting that every query exposes the inherent ambiguity within them. That’s not a bug-it’s a revelation. Future work must confront the inevitability of interpretive divergence, focusing not on eliminating it, but on making it explicit and auditable.
True resilience begins where certainty ends. The field should shift its focus from building systems that answer questions to building ecosystems that reveal the limitations of those questions. The semantic catalog, rather than a control mechanism, becomes a map of known unknowns-a testament to the infinite horizon of data’s inherent complexity.
Original article: https://arxiv.org/pdf/2602.11052.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Gold Rate Forecast
- Monster Hunter Stories 3: Twisted Reflection launches on March 13, 2026 for PS5, Xbox Series, Switch 2, and PC
- Here Are the Best TV Shows to Stream this Weekend on Paramount+, Including ‘48 Hours’
- 🚨 Kiyosaki’s Doomsday Dance: Bitcoin, Bubbles, and the End of Fake Money? 🚨
- ‘The Substance’ Is HBO Max’s Most-Watched Movie of the Week: Here Are the Remaining Top 10 Movies
- First Details of the ‘Avengers: Doomsday’ Teaser Leak Online
- The 10 Most Beautiful Women in the World for 2026, According to the Golden Ratio
- The 11 Elden Ring: Nightreign DLC features that would surprise and delight the biggest FromSoftware fans
- 20 Films Where the Opening Credits Play Over a Single Continuous Shot
2026-02-12 20:17